一、OpenCV 入门
计算机视觉应用是有趣和有用的,但是底层算法是计算密集型的。 随着云计算的到来,我们可以使用更多的处理能力。
OpenCV 库使我们能够实时高效地运行计算机视觉算法。 它已经有很多年的历史了,并且已经成为该领域的标准库。 OpenCV 的主要优势之一是它高度优化,几乎可以在所有平台上使用。
这本书将涵盖我们将使用的各种算法,我们为什么要使用它们,以及如何在 OpenCV 中实现它们。
在本章中,我们将学习如何在各种操作系统上安装 OpenCV。 我们将讨论 OpenCV 提供的开箱即用功能,以及使用内置函数可以做的各种事情。
在本章结束时,您将能够回答以下问题:
- 人类是如何处理视觉数据的,他们又是如何理解图像内容的呢?
- 我们可以使用 OpenCV 做什么,OpenCV 中有哪些模块可以用来实现这些功能?
- 如何在 Windows、Linux 和 Mac OS X 上安装 OpenCV?
了解人类的视觉系统
在我们进入 OpenCV 功能之前,我们首先需要了解为什么要构建这些功能。 重要的是要了解人类视觉系统是如何工作的,这样你才能开发出正确的算法。
计算机视觉算法的目标是理解图像和视频的内容。 人类似乎可以毫不费力地做到这一点! 那么,我们如何让机器以同样的精确度来做这件事呢?
让我们考虑下图:
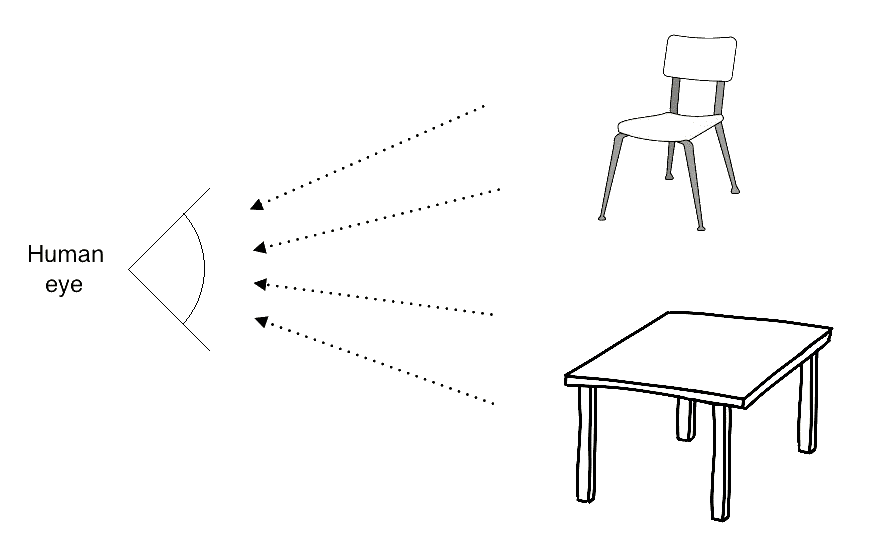
人眼可以捕捉到所有的信息,比如颜色、形状、亮度等等。 在上图中,人眼捕捉到关于这两个主要物体的所有信息,并以某种方式进行存储。 一旦我们了解了我们的系统是如何工作的,我们就可以利用它来实现我们想要的。
例如,以下是我们需要知道的几件事:
- 我们的视觉系统对低频内容比高频内容更敏感。 低频内容是指像素值变化不快的平面区域,高频内容是指像素值波动较大的角和边区域。 我们可以很容易地看到平面上是否有斑点,但在高度纹理的表面上很难发现这样的东西。
-
人眼对亮度的变化比对颜色的变化更敏感。
-
我们的视觉系统对运动很敏感。 我们可以很快识别出是否有什么东西在我们的视野中移动,即使我们没有直接看着它。
-
我们倾向于在脑海中记下我们视野中的要点。 假设你看到一张白色的桌子,它有四条黑色的腿,桌子表面的一角有一个红点。 当你看着这张桌子时,你会立即在脑海中注意到表面和腿的颜色是相反的,其中一个角上有一个红点。 我们的大脑在这方面真的很聪明! 我们会自动这样做,这样如果我们再次遇到一个物体,我们就可以立即认出它。
为了了解我们的视野,让我们看看人类的俯视图,以及我们观察各种事物的角度:
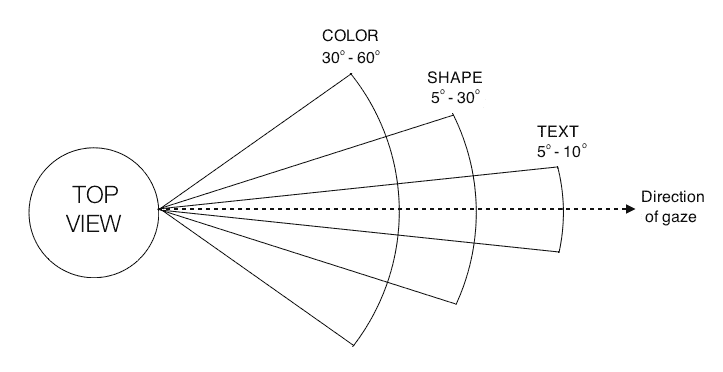
我们的视觉系统实际上有更多的能力,但这应该足以让我们开始。 您可以通过在网络上阅读人类视觉系统(HVS)模型来进一步探索。
人类如何理解图像内容?
如果你环顾四周,你会看到很多东西。 你每天都会遇到许多不同的物体,你几乎可以毫不费力地在瞬间认出它们。 当你看到一把椅子时,你不用等几分钟就会意识到它实际上是一把椅子。 你只要知道它马上就是一把椅子。
另一方面,计算机发现很难完成这项任务。 研究人员多年来一直在努力找出为什么计算机在这方面不如我们。
为了得到这个问题的答案,我们需要了解人类是如何做到这一点的。 视觉数据处理发生在腹侧视流中。 这种腹侧视觉流指的是我们视觉系统中与物体识别相关的路径。 它基本上是我们大脑中帮助我们识别物体的区域的层次结构。
人类可以毫不费力地识别不同的物体,并可以将相似的物体聚集在一起。 我们之所以能做到这一点,是因为我们已经开发出对同一类对象的某种不变性。 当我们看着一个物体时,我们的大脑以这样一种方式提取突出点,即方向、大小、视角和照明等因素都无关紧要。
一把椅子的大小是正常大小的两倍,并且旋转了 45 度,它仍然是一把椅子。 我们可以很容易地识别它,因为我们处理它的方式。 机器不能这么容易做到这一点。 人类往往会根据物体的形状和重要特征来记住它。 无论物体是如何放置的,我们仍然可以识别它。
在我们的视觉系统中,我们建立了关于位置、比例和视点的层次不变性,这有助于我们变得非常健壮。 如果你更深入地观察我们的系统,你会发现人类的视觉皮层中有能对曲线和线条等形状做出反应的细胞。
当我们沿着腹侧流走得更远时,我们会看到更复杂的细胞,它们被训练成对更复杂的物体(如树木、大门等)做出反应。 沿着腹侧流的神经元倾向于显示出感受场的大小增加。 再加上他们喜欢的刺激的复杂性也增加了。
为什么机器很难理解图像内容?
我们现在了解了视觉数据是如何进入人类视觉系统的,以及我们的系统是如何处理它的。 问题是我们仍然不能完全理解我们的大脑是如何识别和组织这些视觉数据的。 在机器学习中,我们只是从图像中提取一些特征,然后要求计算机使用算法来学习它们。 我们仍然有这些变化,例如形状、大小、透视、角度、照明、遮挡等等。
例如,当您从纵断面图查看时,同一张椅子在机器看来非常不同。 人们可以很容易地认出它是一把椅子,不管它是如何呈现给我们的。 那么,我们该如何向我们的机器解释这一点呢?
要做到这一点,一种方法是存储对象的所有不同变化,包括大小、角度、透视等。 但这一过程既繁琐又耗时。 而且,实际上不可能收集到涵盖每一种变异的数据。 这些机器将消耗大量的内存和大量的时间来建立一个能够识别这些物体的模型。
即便如此,如果一个物体被部分遮挡,计算机仍然无法识别它。 这是因为他们认为这是一个新的物体。 因此,当我们构建计算机视觉库时,我们需要构建底层功能块,这些功能块可以以多种不同的方式组合在一起,以形成复杂的算法。
OpenCV 提供了很多这样的功能,而且它们都经过了高度优化。 因此,一旦我们了解了 OpenCV 的能力,我们就可以有效地利用它来构建有趣的应用。
让我们在下一节继续探索这一点。
您可以使用 OpenCV 做什么?
使用 OpenCV,你几乎可以完成你能想到的每一项计算机视觉任务。 现实生活中的问题需要您一起使用许多计算机视觉算法和模块才能达到预期的结果。 因此,您只需要了解要使用哪些 OpenCV 模块和函数,就可以获得您想要的东西。
让我们看看 OpenCV 可以实现哪些开箱即用的功能。
内置数据结构和输入/输出
OpenCV 最好的一点是它提供了大量内置原语来处理与图像处理和计算机视觉相关的操作。 如果必须从头开始编写内容,则必须定义Image、Point、Rectangle等。 这些都是几乎所有计算机视觉算法的基础。
OpenCV 附带了所有这些开箱即用的基本结构,包含在核心模块中。 另一个优点是这些结构已经针对速度和内存进行了优化,因此您不必担心实现细节。
imgcodecs模块处理图像文件的读取和写入。 当您操作输入图像并创建输出图像时,可以用一个简单的命令将其保存为.jpg或.png文件。
当您使用摄像机工作时,您将处理大量视频文件。 videoio模块处理与视频文件的输入和输出相关的一切。 您可以轻松地从网络摄像头捕获视频或读取多种不同格式的视频文件。 您甚至可以通过设置属性(如每秒帧数、帧大小等)将一串帧另存为视频文件。
图像处理操作
在编写计算机视觉算法时,有很多基本的图像处理操作需要反复使用。 这些功能中的大多数都存在于imgproc模块中。 您可以执行图像过滤、形态操作、几何变换、颜色转换、在图像上绘图、直方图、形状分析、运动分析、特征检测等操作。
让我们来看一下下面的照片:

右图是左图的旋转版本。 在 OpenCV 中,我们只需一行即可执行此转换。
还有另一个模块,称为ximgproc,它包含用于边缘检测的结构森林、域变换滤波器、自适应流形滤波器等高级图像处理算法。
图形用户界面
OpenCV 提供了一个名为highgui的模块,用于处理所有高级用户界面操作。 假设您正在处理一个问题,并且希望在继续下一步之前检查图像的外观。 此模块具有可用于创建窗口以显示图像和/或视频的功能。
有一个等待功能,它会等到你按下键盘上的一个键,然后它才会进入下一步。 还有一个可以检测鼠标事件的功能。 这在开发交互式应用时非常有用。
使用此功能,您可以在这些输入窗口上绘制矩形,然后根据所选区域继续。 请考虑以下屏幕截图:
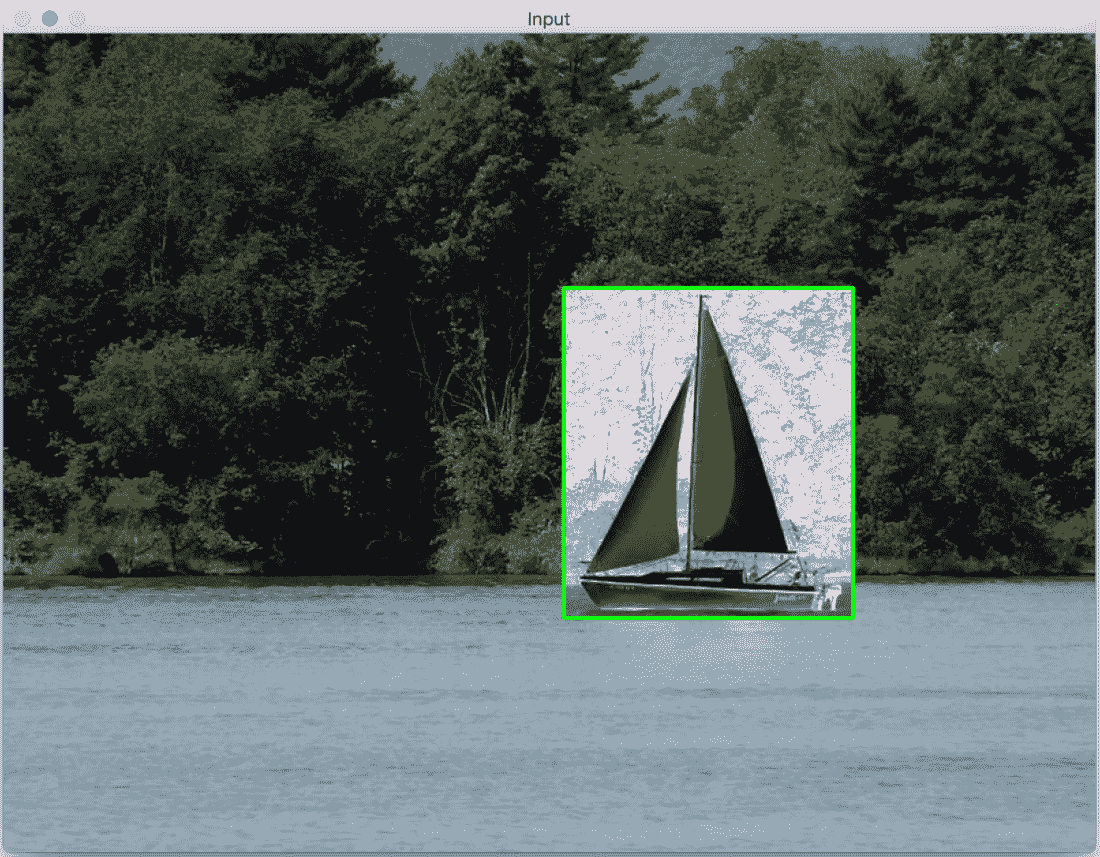
如您所见,我们在窗口顶部绘制了一个绿色矩形。 一旦我们有了那个矩形的坐标,我们就只能在那个区域上行动了。
视频分析
视频分析包括分析视频中连续帧之间的运动、跟踪视频中的不同对象、创建视频监控模型等任务。 OpenCV 提供了一个名为video的模块,可以处理所有这些问题。
还有一个名为videostab的模块,用于处理视频稳定。 视频稳定很重要,因为当你用手持相机拍摄视频时,通常会有很多抖动需要纠正。 所有现代设备在将视频呈现给最终用户之前都会使用视频稳定器对视频进行处理。
三维重建
三维重建是计算机视觉中的一个重要课题。 在给定一组 2D 图像的情况下,我们可以使用相关算法重建 3D 场景。 OpenCV 提供了一些算法,可以找到这些 2D 图像中各种对象之间的关系,从而在其calib3d模块中计算它们的 3D 位置。
该模块还可以处理摄像机校准,这是估计摄像机参数所必需的。 这些参数定义摄影机如何看到它前面的场景。 我们需要知道这些参数来设计算法,否则我们可能会得到意想不到的结果。
让我们考虑下图:

正如我们在这里看到的,同一对象是从多个位置捕获的。 我们的工作是使用这些 2D 图像重建原始对象。
特征提取
正如我们前面讨论的,人类视觉系统倾向于从给定的场景中提取显著特征,以便记住它以备以后检索。 为了模仿这一点,人们开始设计各种特征提取器,可以从给定的图像中提取这些显著点。 流行的算法包括尺度不变特征变换(SIFT)、加速鲁棒特征(SURF)和FEATURES from Accelerated Segment Test(FAST)。
名为features2d的 OpenCV 模块提供了检测和提取所有这些特征的功能。 另一个名为xfeatures2d的模块提供了更多的特征提取器,其中一些仍处于实验阶段。 如果你有机会,你可以玩这些东西。
还有一个名为bioinspired的模块,它为生物启发的计算机视觉模型提供算法。
目标检测
目标检测是指检测目标在给定图像中的位置。 此过程与对象的类型无关。 如果你设计了一个椅子探测器,它不会告诉你一张给定图像中的椅子是红色的高靠背还是蓝色的低靠背-它只会告诉你椅子的位置。
目标位置检测是许多计算机视觉系统中的关键步骤。 请看下面的照片:

如果你在这张图片上运行椅子探测器,它会在所有的椅子周围放一个绿色的方框-但它不会告诉你这是哪种椅子。
对象检测过去是一项计算密集型任务,因为执行各种尺度的检测所需的计算量很大。 为了解决这个问题,Paul Viola 和 Michael Jones 在他们 2001 年的开创性论文中提出了一个很棒的算法,您可以通过以下链接阅读:https://www.cs.cmu.edu/~efros/courses/LBMV07/Papers/viola-cvpr-01.pdf。 它们提供了一种为任何对象设计对象检测器的快速方法。
OpenCV 有称为objdetect和xobjdetect的模块,它们提供了设计对象检测器的框架。 您可以使用它来开发用于太阳镜、靴子等随机物品的检测器。
机器学习
机器学习算法被广泛用于构建计算机视觉系统,用于目标识别、图像分类、人脸检测、视觉搜索等。
OpenCV 提供了一个名为ml的模块,其中捆绑了许多机器学习算法,包括贝叶斯分类器、k 近邻(KNN)、支持向量机(SVM)、决策树、神经网络等等。
它还有一个名为快速近似最近邻搜索库(FLAN)的模块,其中包含在大数据集中进行快速最近邻搜索的算法。
计算摄影
计算摄影是指使用先进的图像处理技术来改善相机捕获的图像。 计算摄影使用软件来处理视觉数据,而不是关注光学过程和图像捕捉方法。 应用包括高动态范围成像、全景图像、图像重新照明和光场相机。
让我们看下图:

看看那些鲜艳的颜色! 这是一个高动态范围图像的例子,使用传统的图像捕捉技术是不可能获得的。 要做到这一点,我们必须在多次曝光时捕捉相同的场景,将这些图像彼此配准,然后将它们很好地混合在一起,以创建这张图像。
photo和xphoto模块包含提供与计算摄影有关的算法的各种算法。 还有一个名为stitching的模块,它提供了创建全景图像的算法。
The image shown can be found here: https://pixabay.com/en/hdr-high-dynamic-range-landscape-806260/.
形状分析
形状的概念在计算机视觉中至关重要。 我们通过识别图像中各种不同的形状来分析视觉数据。 这实际上是许多算法中的重要一步。
假设您正在尝试识别图像中的特定徽标。 您知道它可以以各种形状、方向和大小出现。 开始的一个好方法是量化物体形状的特征。
shape模块提供提取不同形状、测量它们之间的相似性、变换对象形状等所需的所有算法。
光流算法
在视频中使用光流算法来跟踪连续帧上的特征。 假设您想要跟踪视频中的特定对象。 在每个帧上运行特征提取器的计算代价会很高;因此,该过程会很慢。 因此,您只需从当前帧中提取特征,然后在连续的帧中跟踪这些特征。
光流算法广泛应用于计算机视觉中基于视频的应用中。 optflow模块包含执行光流所需的所有算法。 还有一个名为tracking的模块,它包含更多可用于跟踪功能的算法。
人脸和物体识别
人脸识别是指识别给定图像中的人。 这与人脸检测不同,在人脸检测中,您只需识别给定图像中人脸的位置。
如果你想构建一个实用的生物识别系统,能够识别摄像头前的人,你首先需要运行人脸检测器来识别人脸的位置,然后运行单独的人脸识别器来识别这个人是谁。 有一个名为face的 OpenCV 模块处理人脸识别。
正如我们前面讨论的,计算机视觉试图根据人类感知视觉数据的方式对算法进行建模。 因此,在图像中发现显著区域和目标将有助于不同的应用,如目标识别、目标检测和跟踪等。 有一个名为saliency的模块就是为此目的而设计的。 它提供了可以检测静态图像和视频中显著区域的算法。
曲面匹配
我们越来越多地与能够捕捉我们周围物体的 3D 结构的设备互动。 这些设备主要捕捉深度信息,以及常规的 2D 彩色图像。 因此,构建能够理解和处理 3D 对象的算法对我们来说非常重要。
Kinect就是捕获深度信息和视觉数据的设备的一个很好的例子。 手头的任务是通过将输入的 3D 对象与我们数据库中的一个模型进行匹配来识别输入的 3D 对象。 如果我们有一个可以识别和定位物体的系统,那么它可以用于许多不同的应用。
有一个名为surface_matching的模块,它包含 3D 对象识别算法和使用 3D 特征的姿势估计算法。
文本检测与识别
识别特定场景中的文本和识别内容变得越来越重要。 应用包括车牌识别、自动驾驶汽车的路标识别、书籍扫描以数字化内容等。
有一个名为text的模块,它包含处理文本检测和识别的各种算法。
深度学习
深度学习对计算机视觉和图像识别的影响很大,比其他机器学习和人工智能算法具有更高的准确率。 深度学习并不是一个新概念;它在 1986 年左右被引入社区,但它在 2012 年左右开始了一场革命,当时新的 GPU 硬件针对并行计算进行了优化,卷积神经网络(CNN)实现和其他技术允许在合理的时间内训练复杂的神经网络结构。
深度学习可以应用于多个用例,例如图像识别、对象检测、语音识别和自然语言处理。 从 3.4 版本开始,OpenCV 就一直在实现深度学习算法--在最新版本中,为TensorFlow和Caffe等重要框架添加了多个导入器。
安装 OpenCV
让我们看看如何在各种操作系统上启动和运行 OpenCV。
Windows 操作系统
为简单起见,让我们使用预构建库安装 OpenCV。 转到opencv.org并下载 Windows 的最新版本。 目前的版本是 4.0.0,您可以从 OpenCV 主页获取下载链接。 在继续之前,您应该确保您拥有管理员权限。
下载的文件将是可执行文件,因此只需双击它即可开始安装。 安装程序将内容展开到文件夹中。 您将能够选择安装路径,并通过检查文件来检查安装。
完成上一步后,我们需要设置 OpenCV 环境变量并将它们添加到系统路径以完成安装。 我们将设置一个环境变量,该变量将保存 OpenCV 库的构建目录。 我们将在我们的项目中使用这一点。
打开终端并键入以下内容:
C:> setx -m OPENCV_DIR D:OpenCVBuildx64vc14
We are assuming that you have a 64-bit machine with Visual Studio 2015 installed. If you have Visual Studio 2012, replace vc14 with vc11 in the command. The path specified is where we would have our OpenCV binaries, and you should see two folders inside that path called lib and bin. If you are using Visual Studio 2018, you should compile OpenCV from scratch.
让我们继续并将bin文件夹的路径添加到我们的系统路径。 之所以需要这样做,是因为我们将使用动态链接库(DLLs)形式的 OpenCV 库。 实际上,所有的 OpenCV 算法都存储在这里,我们的操作系统只会在运行时加载它们。
为了做到这一点,我们的操作系统需要知道它们的位置。 PATH系统变量包含它可以在其中找到 DLL 的所有文件夹的列表。 因此,我们自然需要将 OpenCV 库的路径添加到此列表中。
我们为什么要做这一切呢? 好的,另一种选择是将所需的 DLL 复制到与应用的可执行文件(.exe文件)相同的文件夹中。 这是一个不必要的开销,特别是当我们在处理许多不同的项目时。
我们需要编辑PATH变量来添加此文件夹。 您可以使用路径编辑器等软件来执行此操作,您可以从此处下载:https://patheditor2.codeplex.com。 安装后,启动它并添加以下新条目(您可以右键单击路径以插入新项目):
%OPENCV_DIR%bin
继续并将其保存到注册表。 我们完了!
Mac OS X Mac OS X
在本节中,我们将了解如何在 Mac OS X 上安装 OpenCV。预编译的二进制文件在 Mac OS X 上不可用,因此我们需要从头开始编译 OpenCV。
在继续之前,我们需要安装 CMake。 如果您还没有安装 CMake,可以从这里下载:https://cmake.org/files/v3.12/cmake-3.12.0-rc1-Darwin-x86_64.dmg。 这是一个.dmg文件,所以下载后,只需运行安装程序即可。
从opencv.org下载最新版本的 OpenCV。 当前版本是 4.0.0,您可以从这里下载:https://github.com/opencv/opencv/archive/4.0.0.zip。 将内容解压缩到您选择的文件夹中。
OpenCV 4.0.0 还有一个名为opencv_contrib的新包,其中包含尚未被认为是稳定的用户贡献,以及在所有最新的计算机视觉算法中不能免费用于商业用途的一些算法,这一点值得记住。 安装此软件包是可选的-如果您不安装opencv_contrib,OpenCV 将工作得很好。
因为我们无论如何都要安装 OpenCV,所以最好安装这个软件包,这样您以后就可以试用它了(而不是再次经历整个安装过程)。 这是学习和使用新算法的好方法。 您可以从以下链接下载:https://github.com/opencv/opencv_contrib/archive/4.0.0.zip。
将 zip 文件的内容解压缩到您选择的文件夹中。 为方便起见,请将其解压缩到与前面相同的文件夹中,以便opencv-4.0.0和opencv_contrib-4.0.0文件夹位于同一主文件夹中。
我们现在就可以构建 OpenCV 了。 打开终端并导航到解压 OpenCV 4.0.0 内容的文件夹。 在命令中替换正确路径后运行以下命令:
$ cd /full/path/to/opencv-4.0.0/
$ mkdir build
$ cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/full/path/to/opencv-4.0.0/build -D INSTALL_C_EXAMPLES=ON -D BUILD_EXAMPLES=ON -D OPENCV_EXTRA_MODULES_PATH=/full/path/to/opencv_contrib-4.0.0/modules ../
现在是安装 OpenCV 4.0.0 的时候了。 转到/full/path/to/opencv-4.0.0/build目录,并在您的终端上运行以下命令:
$ make -j4
$ make install
在前面的命令中,-j4标志指示它应该使用四个内核来安装它。 这样会更快! 现在,让我们设置库路径。 使用vi ~/.profile命令在您的终端中打开您的~/.profile文件,并添加以下行:
export DYLD_LIBRARY_PATH=/full/path/to/opencv-4.0.0/build/lib:$DYLD_LIBRARY_PATH
我们需要将opencv.pc中的pkgconfig文件复制到/usr/local/lib/pkgconfig,并将其命名为opencv4.pc。 这样,如果您已经安装了 OpenCV 3.x.x,则不会发生冲突。 让我们继续这样做:
$ cp /full/path/to/opencv-4.0.0/build/lib/pkgconfig/opencv.pc /usr/local/lib/pkgconfig/opencv4.pc
我们还需要更新我们的PKG_CONFIG_PATH变量。 打开您的~/.profile文件并添加以下行:
export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig/:$PKG_CONFIG_PATH
使用以下命令重新加载~/.profile文件:
$ source ~/.profile
我们完了! 让我们看看它是不是起作用了:
$ cd /full/path/to/opencv-4.0.0/samples/cpp
$ g++ -ggdb `pkg-config --cflags --libs opencv4` opencv_version.cpp -o /tmp/opencv_version && /tmp/opencv_version
如果您的终端上显示了欢迎使用 OpenCV 4.0.0,您就可以开始使用了。 在本书中,我们将使用 CMake 来构建我们的 OpenCV 项目。 我们将在第 2 章,OpenCV 基础简介中更详细地介绍它。
Linux 操作系
让我们来看看如何在 Ubuntu 上安装 OpenCV。 在开始之前,我们需要安装一些依赖项。 让我们通过在您的终端中运行以下命令,使用包管理器安装它们:
$ sudo apt-get -y install libopencv-dev build-essential cmake libdc1394-22 libdc1394-22-dev libjpeg-dev libpng12-dev libtiff5-dev libjasper-dev libavcodec-dev libavformat-dev libswscale-dev libxine2-dev libgstreamer0.10-dev libgstreamer-plugins-base0.10-dev libv4l-dev libtbb-dev libqt4-dev libmp3lame-dev libopencore-amrnb-dev libopencore-amrwb-dev libtheora-dev libvorbis-dev libxvidcore-dev x264 v4l-utils
现在您已经安装了依赖项,让我们下载、构建并安装 OpenCV:
$ wget "https://github.com/opencv/opencv/archive/4.0.0.tar.gz" -O opencv.tar.gz
$ wget "https://github.com/opencv/opencv_contrib/archive/4.0.0.tar.gz" -O opencv_contrib.tar.gz
$ tar -zxvf opencv.tar.gz
$ tar -zxvf opencv_contrib.tar.gz
$ cd opencv-4.0.0
$ mkdir build
$ cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/full/path/to/opencv-4.0.0/build -D INSTALL_C_EXAMPLES=ON -D BUILD_EXAMPLES=ON -D OPENCV_EXTRA_MODULES_PATH=/full/path/to/opencv_contrib-4.0.0/modules ../
$ make -j4
$ sudo make install
让我们将opencv.pc中的pkgconfig文件复制到/usr/local/lib/pkgconfig,并将其命名为opencv4.pc:
$ cp /full/path/to/opencv-4.0.0/build/lib/pkgconfig/opencv.pc /usr/local/lib/pkgconfig/opencv4.pc
我们完了! 我们现在可以使用它从命令行编译我们的 OpenCV 程序。 此外,如果您已经安装了 OpenCV 3.x.x,则不会发生冲突。
让我们检查一下安装是否工作正常:
$ cd /full/path/to/opencv-4.0.0/samples/cpp
$ g++ -ggdb `pkg-config --cflags --libs opencv4` opencv_version.cpp -o /tmp/opencv_version && /tmp/opencv_version
如果您的终端上显示了欢迎使用 OpenCV 4.0.0,您应该可以开始使用了。 在接下来的章节中,我们将学习如何使用 CMake 来构建我们的 OpenCV 项目。
简略的 / 概括的 / 简易判罪的 / 简易的
在本章中,我们讨论了人类的视觉系统,以及人类如何处理视觉数据。 我们解释了为什么机器很难做到这一点,以及在设计计算机视觉库时需要考虑的问题。
我们了解了使用 OpenCV 可以做什么,以及可以用来完成这些任务的各种模块。 最后,我们学习了如何在各种操作系统上安装 OpenCV。
在下一章中,我们将讨论如何对图像进行操作,以及如何使用各种函数对其进行操作。 我们还将学习如何为我们的 OpenCV 应用构建项目结构。
