十四、使用 SfM 模块从运动中探索结构
运动的结构(SfM)是恢复摄像机注视场景的位置和场景的稀疏几何体的过程。 相机之间的运动施加了几何约束,可以帮助我们恢复物体的结构,因此这个过程被称为 Sfm。 从 OpenCV v3.0+开始,添加了一个名为sfm的贡献("contrib")模块,它帮助从多个图像执行端到端的 SfM 处理。 在本章中,我们将学习如何使用 SfM 模块将场景重建为稀疏点云,包括相机姿势。 稍后,我们还将加密点云,通过使用名为 OpenMVS 的开放多视图立体(MVS)软件包向其添加更多点以使其密集。 SFM 被用于高质量的三维扫描,自主导航的视觉里程计,航空摄影测绘,以及更多的应用,使其成为计算机视觉中最基本的追求之一。 计算机视觉工程师应该熟悉 SfM 的核心概念,计算机视觉课程经常讲授这一主题。
本章将介绍以下主题:
- SfM 的核心概念:多视图几何(MVG)、三维重建和多视图立体(MVS)
- 使用 OpenCV SfM 模块实施 SfM 管道
- 可视化重建结果
- 将重建导出到 OpenMVG,并将稀疏云加密为完全重建
技术要求
构建和运行本章中的代码需要以下技术和安装:
- OpenCV 4(使用
sfm contrib模块编译) - Eigen v3.3+(
sfm模块要求) - CERES 求解器 v2+1(
sfm模块要求) - CMake 3.12+
- Boost v1.66+
- OpenMVS
- CGAL v4.12+(OpenMVS 要求)
所列组件的构建说明以及实现本章中概念的代码将在附带的代码存储库中提供。 使用 OpenMVS 是可选的,我们可以在得到稀疏重建后停止。 然而,完整的 MVS 重建更令人印象深刻,也更有用;例如,对于 3D 打印复制品。
具有足够重叠的任何一组照片对于 3D 重建可能是足够的。 例如,我们可以使用我在南达科他州拍摄的一组疯马纪念头的照片,它与这个章节代码捆绑在一起。 要求拍摄的图像之间应该有足够的移动,但足够有明显的重叠,以便进行强有力的配对匹配。
在下面的例子中,从疯马纪念数据集,我们可以注意到图像之间的视角有轻微的变化,重叠非常强烈。 请注意,我们还可以在人们行走的雕像下方看到巨大的变化;这不会干扰石面的 3D 重建:

Sfm 的核心概念
在我们深入研究 SfM 管道的实现之前,让我们回顾一下作为该过程的重要部分的一些关键概念。 SfM 中最重要的一类理论主题是核极几何(EG),即多视图几何或 MVG,它建立在图像形成和相机校准知识的基础上;然而,我们将只略过这些基本主题。在我们介绍了 EG 的几个基础知识之后,我们将很快讨论立体重建,并回顾诸如从视差获得深度的主题。 SfM 中的其他关键主题,如健壮特征匹配,更多的是机械性的,而不是理论上的,我们将在对系统进行编码的过程中介绍这些主题。 我们有意省略了一些非常有趣的主题,例如相机分割、PNP 算法和重构因子分解,因为这些都是由底层的sfm模块处理的,我们不需要调用它们,尽管 OpenCV 中确实存在执行它们的函数。
在过去的四十年里,所有这些主题都是大量研究和文献的来源,并成为数以千计的学术论文、专利和其他出版物的主题。Hartley 和 Zisserman 的多视图几何是迄今为止 SfM 和 MVG 数学和算法的最重要的资源,尽管令人难以置信的次要资产是 Szeliski 的计算机视觉:算法和应用,它非常详细地解释了 SfM,重点是 Richard Szelisiski。 对于第三个解释来源,我建议你买一本普林斯的计算机视觉:模型、学习和推理,这本书的特点是漂亮的图形、图表和细致的数学推导。
校准相机和核线几何
我们的图像从投影开始。 他们通过镜头看到的 3D 世界在相机内部的 2D 传感器上被展平,基本上失去了所有的深度信息。 那么我们如何才能从 2D 图像回到 3D 结构呢? 在许多情况下,标准强度相机的答案是 MVG。 直观地说,如果我们至少可以从两个视图看到一个物体(2D),我们就可以估计它与摄像机的距离。 作为人类,我们经常这样做,用我们的两只眼睛。 我们人类的深度感知来自多个(两个)视角,但不仅仅是这样。 事实上,人类的视觉感知,因为它与感知深度和 3D 结构有关,是非常复杂的,与眼睛的肌肉和传感器有关,而不仅仅是我们视网膜上的图像及其在大脑中的处理。 人类的视觉及其神奇特征远远超出了本章的范围;然而,在不止一个方面,SFM(以及所有的计算机视觉!)。 灵感来自人类的视觉。
回到我们的摄像机。 在标准的 SfM 中,我们使用针孔相机模型,它简化了真实相机中进行的整个光学、机械、电气和软件过程。 针孔模型描述了现实世界中的对象如何变成像素,并涉及一些我们称为内部参数的参数,因为它们描述了相机的内部功能:
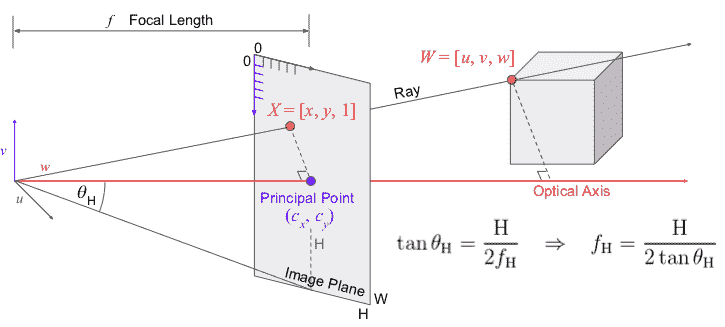
使用针孔模型,我们通过应用投影来确定 3D 点在图像平面上的 2D 位置。 请注意 3D 点 和相机原点如何形成直角三角形,其中相邻边等于
和相机原点如何形成直角三角形,其中相邻边等于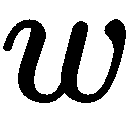 。 图像点
。 图像点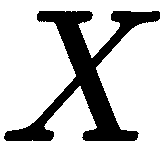 与相邻的点
与相邻的点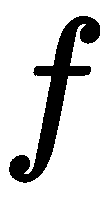 共享相同的角度,即从原点到图像平面的距离。 这个距离被称为焦距,但这个名称可能具有欺骗性,因为图像平面实际上并不是焦平面;为了简单起见,我们将这两个名称融合在一起。 重叠直角三角形的初等几何将告诉我们
共享相同的角度,即从原点到图像平面的距离。 这个距离被称为焦距,但这个名称可能具有欺骗性,因为图像平面实际上并不是焦平面;为了简单起见,我们将这两个名称融合在一起。 重叠直角三角形的初等几何将告诉我们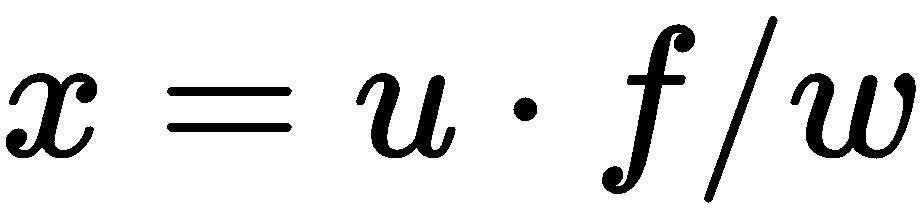 ;然而,由于我们处理图像,我们必须考虑原点和
;然而,由于我们处理图像,我们必须考虑原点和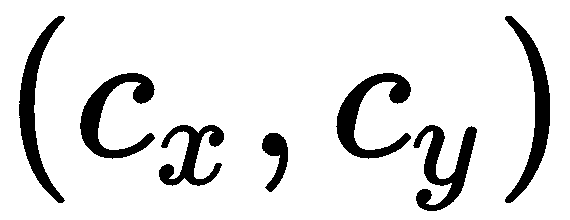 ,并得出
,并得出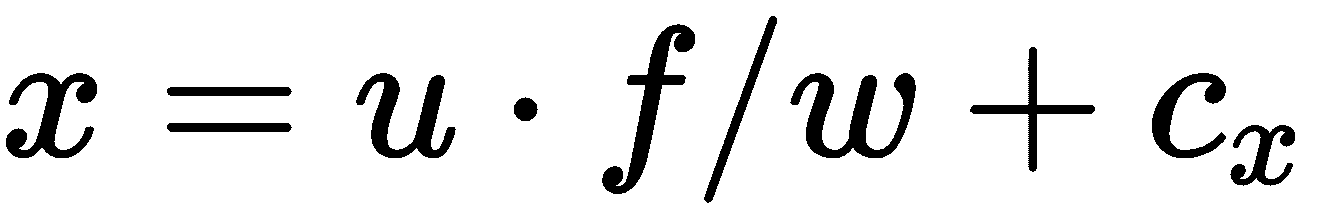 。 如果我们对
。 如果我们对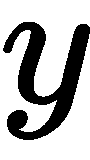 轴执行同样的操作,则如下所示:
轴执行同样的操作,则如下所示:
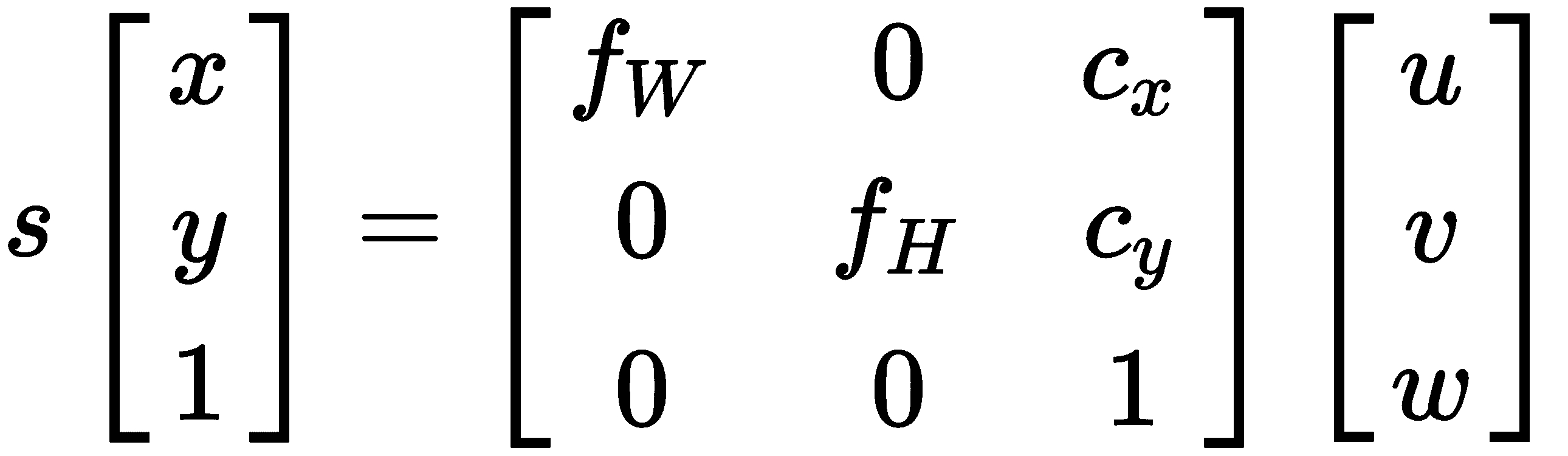
3x3 矩阵称为本征参数矩阵,通常表示为 ;然而,这个方程式有一些地方似乎不太对劲,需要解释。 首先,我们错过了分区
;然而,这个方程式有一些地方似乎不太对劲,需要解释。 首先,我们错过了分区 ,它去了哪里? 第二,方程式的 LHS 上出现的那个神秘的公式
,它去了哪里? 第二,方程式的 LHS 上出现的那个神秘的公式 是什么? 答案是齐次坐标,这意味着我们在向量的末尾加上一个
是什么? 答案是齐次坐标,这意味着我们在向量的末尾加上一个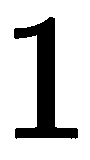 符号。这个有用的符号允许我们线性化这些运算,并在以后执行除法。 在矩阵乘法步骤的末尾,我们可能会一次对数千个点进行乘法,我们将结果除以向量中的最后一项,这恰好就是我们要寻找的结果
符号。这个有用的符号允许我们线性化这些运算,并在以后执行除法。 在矩阵乘法步骤的末尾,我们可能会一次对数千个点进行乘法,我们将结果除以向量中的最后一项,这恰好就是我们要寻找的结果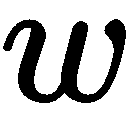 。 至于
。 至于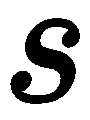 ,这是一个我们必须牢记的未知的任意尺度因素,它来自我们在预测中的一个视角。 想象一下,我们有一辆玩具车离摄像机非常近,旁边是一辆真实大小的车,距离摄像机 10 米远;在图像中,它们看起来大小相同。 换句话说,我们可以将 3D 点
,这是一个我们必须牢记的未知的任意尺度因素,它来自我们在预测中的一个视角。 想象一下,我们有一辆玩具车离摄像机非常近,旁边是一辆真实大小的车,距离摄像机 10 米远;在图像中,它们看起来大小相同。 换句话说,我们可以将 3D 点 沿着相机发出的光线移动到任何地方,但仍然可以在图像中获得相同的
沿着相机发出的光线移动到任何地方,但仍然可以在图像中获得相同的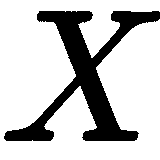 坐标。 这就是透视投影的魔咒:我们失去了我们在本章开头提到的深度信息。
坐标。 这就是透视投影的魔咒:我们失去了我们在本章开头提到的深度信息。
还有一件事我们必须考虑,那就是我们的相机在世界上的姿势。 并不是所有的摄像头都放置在原点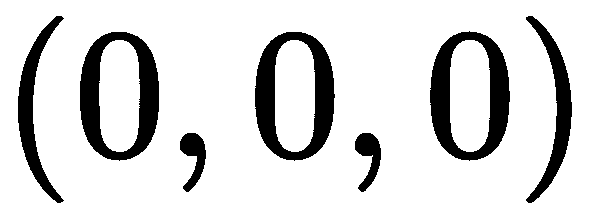 ,特别是如果我们有一个有很多摄像头的系统。 我们可以方便地将一个摄影机放置在原点,但其余摄影机将具有相对于其自身的旋转和平移(刚性变换)组件。 因此,我们将另一个矩阵添加到投影方程式中:
,特别是如果我们有一个有很多摄像头的系统。 我们可以方便地将一个摄影机放置在原点,但其余摄影机将具有相对于其自身的旋转和平移(刚性变换)组件。 因此,我们将另一个矩阵添加到投影方程式中:
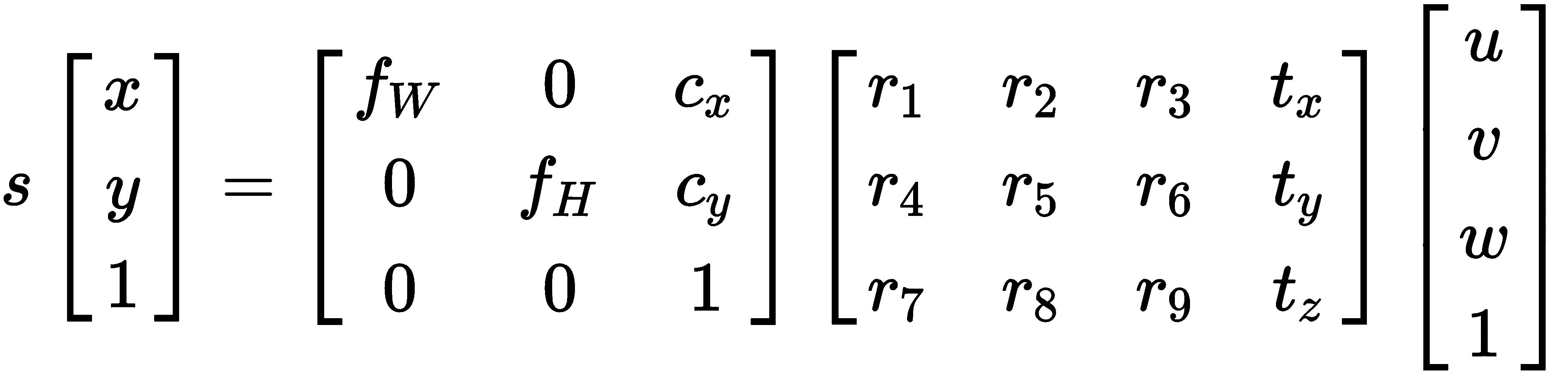
新的 3x4 矩阵通常称为外部参数矩阵,包含 3x3 旋转和 3x1 平移分量。 请注意,我们使用了相同的齐次坐标技巧,通过在 末尾添加 1 来帮助将平移合并到计算中。 我们经常会在文献中看到写成
末尾添加 1 来帮助将平移合并到计算中。 我们经常会在文献中看到写成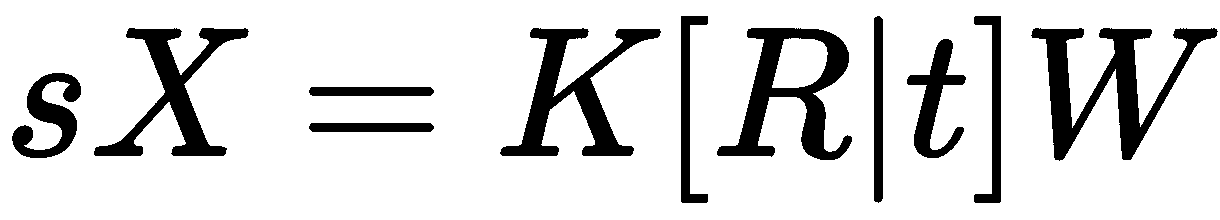 的整个方程式:
的整个方程式:
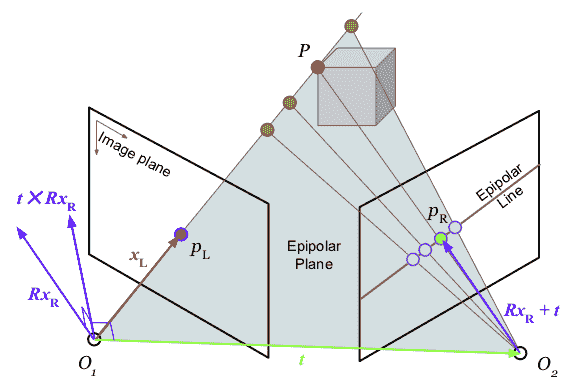
假设两个相机看着相同的对象点。 正如我们刚才所讨论的,我们可以将 3D 点的真实位置沿着相机的轴向滑动,但仍然观察到相同的 2D 点,从而丢失深度信息。直观地说,两个视角应该足以找到真实的 3D 位置,因为来自两个视点的光线会聚在这里。但实际上,当我们在光线上滑动该点时,在另一个从不同角度看的相机中,这个位置会改变。 事实上,相机L 和(左)中的任何点都将对应于相机R(右)中的线,称为核极线e(有时称为尾线),该线位于由两个相机的光学中心和 3D 点构成的核极面上。 这可以用作两个视图之间的几何约束,帮助我们找到关系。
我们已经知道,在两个摄像头之间,有一个刚性的变换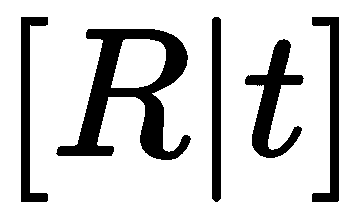 。 如果我们想在摄像机L的坐标系中表示摄像机R中的一个点--
。 如果我们想在摄像机L的坐标系中表示摄像机R中的一个点--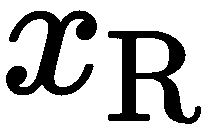 ,我们可以这样写:
,我们可以这样写: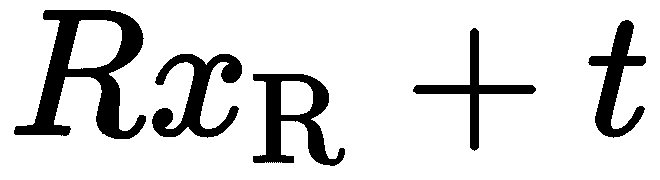 。 如果我们取叉积
。 如果我们取叉积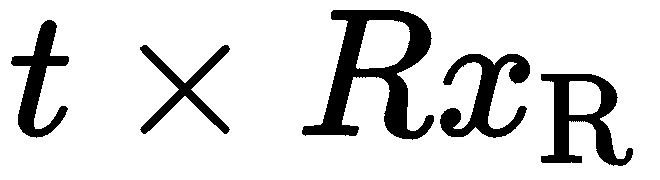 ,我们将得到一个垂直于极平面的矢量。 因此,推论
,我们将得到一个垂直于极平面的矢量。 因此,推论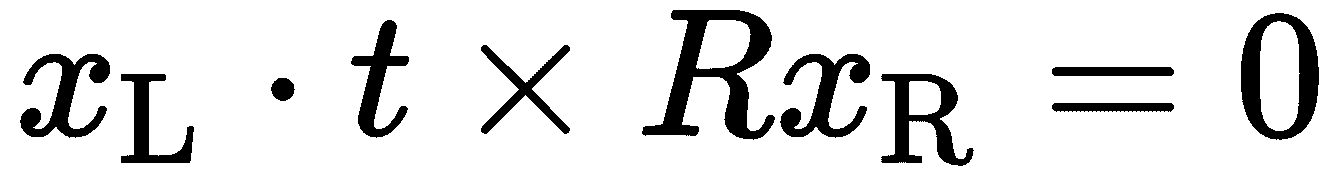 ,因为
,因为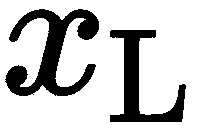 在的极面上是*,所以一个点积将产生 0。 我们取叉积的斜对称形式,我们可以写成
在的极面上是*,所以一个点积将产生 0。 我们取叉积的斜对称形式,我们可以写成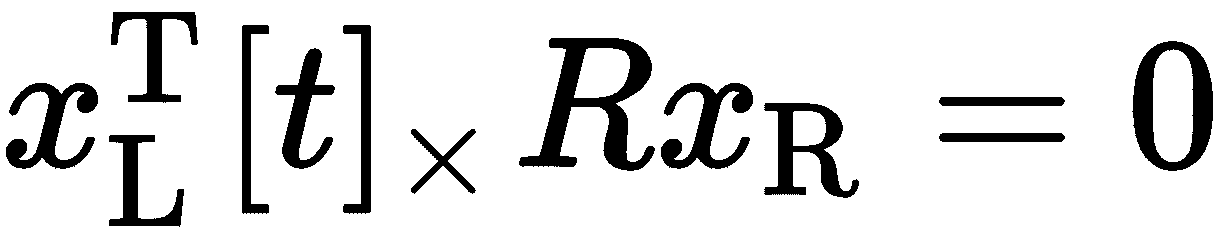 ,然后把它组合成一个矩阵
,然后把它组合成一个矩阵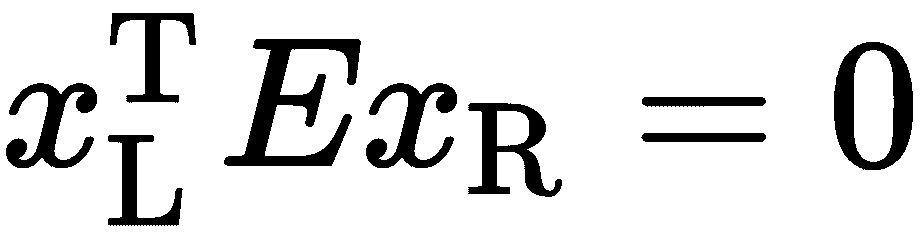 。 我们称
。 我们称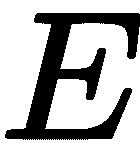 为本质矩阵。 本质矩阵给出了一个核线约束,约束范围是摄像机 L 和摄像机 R 之间所有会聚于真实 3D 点的点对。 如果一对点(来自L和R)不能满足此约束,则它很可能不是有效的配对。 我们也可以使用一些点对来估计本质矩阵,因为它们简单地构造了齐次线性方程组。 用特征值或奇异值分解(奇异值分解*)可以很容易地得到解。
为本质矩阵。 本质矩阵给出了一个核线约束,约束范围是摄像机 L 和摄像机 R 之间所有会聚于真实 3D 点的点对。 如果一对点(来自L和R)不能满足此约束,则它很可能不是有效的配对。 我们也可以使用一些点对来估计本质矩阵,因为它们简单地构造了齐次线性方程组。 用特征值或奇异值分解(奇异值分解*)可以很容易地得到解。
到目前为止,在我们的几何学中,我们假设我们的相机是规格化的,本质上是指单位矩阵 。 然而,在具有特定像素大小和焦距的真实图像中,我们必须考虑真实的固有特性。 为此,我们可以在两侧应用
。 然而,在具有特定像素大小和焦距的真实图像中,我们必须考虑真实的固有特性。 为此,我们可以在两侧应用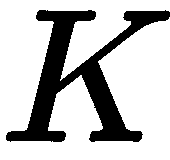 的逆:
的逆: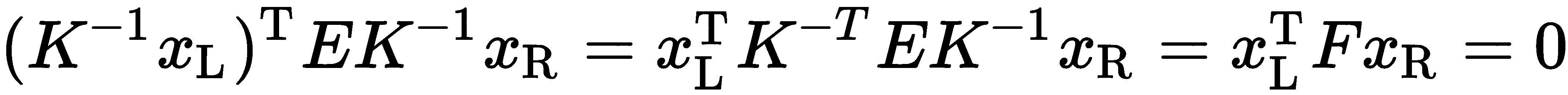 。 我们最终得到的这个新矩阵称为基本矩阵,它可以从足够多的像素坐标点对中估计出来。 如果我们知道
。 我们最终得到的这个新矩阵称为基本矩阵,它可以从足够多的像素坐标点对中估计出来。 如果我们知道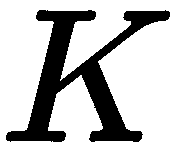 ,我们就可以得到本质矩阵;然而,基础矩阵本身可以作为一个很好的核线约束。
,我们就可以得到本质矩阵;然而,基础矩阵本身可以作为一个很好的核线约束。
立体重建与 SfM
在 SFM 中,我们希望同时恢复摄像机的姿势和 3D 特征点的位置。 我们刚刚看到了简单的 2D 点对匹配如何帮助我们估计本质矩阵,从而编码视图之间的严格几何关系: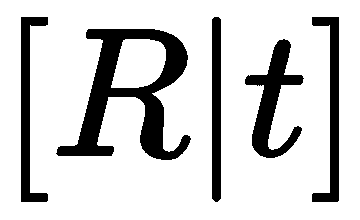 。 本质矩阵可以通过奇异值分解(SVD)的方式分解为
。 本质矩阵可以通过奇异值分解(SVD)的方式分解为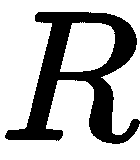 和
和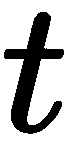 ,在找到
,在找到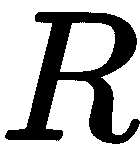 和
和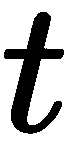 之后,我们继续寻找 3D 点,并完成这两幅图像的 SfM 任务。
之后,我们继续寻找 3D 点,并完成这两幅图像的 SfM 任务。
我们已经看到了两个 2D 视图和 3D 世界之间的几何关系;但是,我们还没有看到如何从 2D 视图恢复 3D 形状。 我们的一个见解是,给出同一点的两个视图,我们可以从相机的光学中心和图像平面上的 2D 点穿过这两条光线,它们将会聚在 3D 点上。 这是三角剖分的基本思想。 求解 3D 点的一种简单方法是写出投影方程并将其等值,因为 3D 点( )是常见的
)是常见的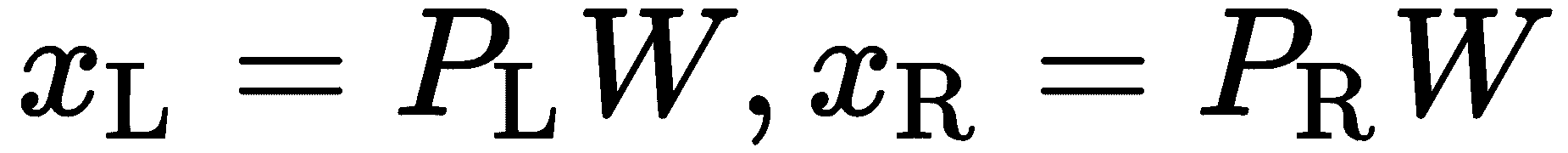 ,其中第
,其中第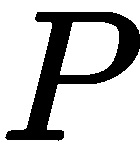 个矩阵是第
个矩阵是第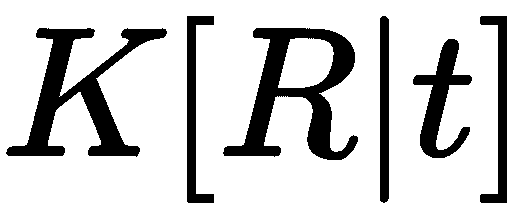 个投影矩阵。 这些方程可以化为齐次线性方程组,并且可以例如用奇异值分解(SVD)来求解。 这被称为三角剖分的直接线性方法;然而,它是严重次优的,因为它没有直接最小化有意义的误差函数。 还提出了其他几种方法,包括查看光线之间的最近点(通常不直接相交),称为中点法。
个投影矩阵。 这些方程可以化为齐次线性方程组,并且可以例如用奇异值分解(SVD)来求解。 这被称为三角剖分的直接线性方法;然而,它是严重次优的,因为它没有直接最小化有意义的误差函数。 还提出了其他几种方法,包括查看光线之间的最近点(通常不直接相交),称为中点法。
从两个视图获得基线 3D 重建后,我们可以继续添加更多视图。 这通常以不同的方法完成,在现有的 3D 点和传入的 2D 点之间使用匹配。 这类算法称为点-n-透视(PnP),我们不在这里讨论。 另一种方法是执行成对立体重建(我们已经看到),并计算比例因子,因为如前所述,重建的每个图像对可能会产生不同的比例。
恢复深度信息的另一个有趣的方法是进一步利用核线。 我们知道,图像L中的一个点将位于图像R中的一条直线上,我们也可以使用 精确地计算这条直线。 因此,任务是在图像R的核线上找到与图像 L 中的点最匹配的点。这种线匹配方法可称为立体深度重建,由于我们可以恢复图像中几乎每个像素的深度信息,因此它是密集重建的大多数倍。 实际上,核线首先校正为完全水平,模仿图像之间的纯水平平移。 这减少了仅在x轴上匹配的问题:
精确地计算这条直线。 因此,任务是在图像R的核线上找到与图像 L 中的点最匹配的点。这种线匹配方法可称为立体深度重建,由于我们可以恢复图像中几乎每个像素的深度信息,因此它是密集重建的大多数倍。 实际上,核线首先校正为完全水平,模仿图像之间的纯水平平移。 这减少了仅在x轴上匹配的问题:
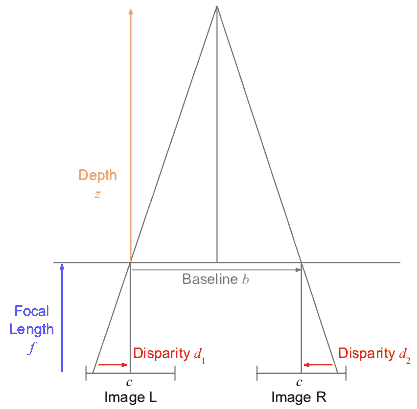
水平平移的主要吸引力是视差、和,它描述了兴趣点在两幅图像之间水平移动的距离。 在上图中,我们可以注意到,由于右重叠三角形: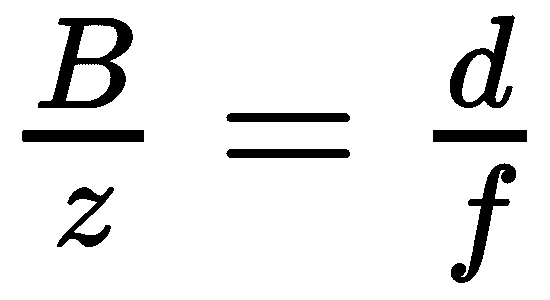 ,这导致了
,这导致了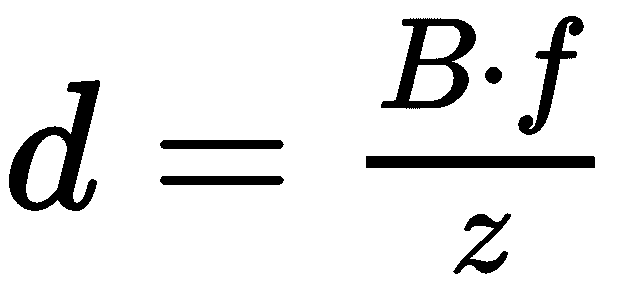 。 基线
。 基线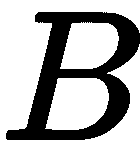 (水平运动)和焦距
(水平运动)和焦距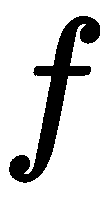 相对于特定的 3D 点及其与相机的距离是恒定的。 因此,我们的洞察力是,差异与深度成反比。 视差越小,点离相机越远。 当我们从移动的火车车窗看地平线时,远处的山脉移动得很慢,而近处的树木移动得很快。 这种效果也称为视差。 利用视差进行三维重建是所有立体算法的基础。
相对于特定的 3D 点及其与相机的距离是恒定的。 因此,我们的洞察力是,差异与深度成反比。 视差越小,点离相机越远。 当我们从移动的火车车窗看地平线时,远处的山脉移动得很慢,而近处的树木移动得很快。 这种效果也称为视差。 利用视差进行三维重建是所有立体算法的基础。
另一个被广泛研究的主题是 MVS,它利用核线约束一次从多个视图中寻找匹配点。 同时扫描多个图像中的尾部可以对匹配特征施加进一步的约束。 只有当找到满足所有约束的匹配项时,才会考虑它。 当我们恢复多个相机位置时,我们可以使用 MVS 进行密集重建,这也是我们在本章后面要做的。
在 OpenCV 中实现 SfM
OpenCV 拥有丰富的工具,可以从 First Principle 实现成熟的 SfM 管道。 然而,这样的任务要求非常高,超出了本章的范围。 这本书的前一版只是略微介绍了构建这样一个系统需要做些什么,但幸运的是,现在我们已经掌握了一种经过验证和测试的技术,它直接集成到 OpenCV 的 API 中。尽管sfm模块允许我们通过简单地提供一个带有图像列表的非参数函数来处理和接收具有稀疏点云和相机姿势的完全重建的场景,但是我们不会走这条路。 相反,我们将在这一节中看到一些有用的方法,这些方法将使我们能够更好地控制重建,并举例说明我们在上一节中讨论的一些主题,以及更强的抗噪能力。
本节将从 sfm:使用关键点和功能描述符匹配图像的非常基础开始。 然后,我们将使用匹配图通过图像集查找个轨迹以及相似特征的多个视图。 我们继续进行3D 图像重建,3D 可视化,最后使用 OpenMVS 进行 MVS。
图像特征匹配
如上一节所述,SFM 依赖于理解图像之间的几何关系,因为它与图像中的可见对象相关。 我们看到,我们可以计算出两幅图像之间的精确运动,并且有足够的关于图像中对象如何运动的信息。 可以从图像特征线性估计的基本矩阵或基本矩阵可以分解成定义3D 刚性变换的旋转和平移元素。 此后,这种变换可以帮助我们从 3D-2D 投影方程或根据校正后的尾部上的密集立体匹配来三角测量对象的 3D 位置。 这一切都是从图像特征匹配开始的,因此我们将看到如何获得健壮且无噪声的匹配。
OpenCV 提供了大量的 2D 特征检测器(也称为提取器)和描述符。 特征被设计为与图像变形不变,因此它们可以通过场景中对象的平移、旋转、缩放和其他更复杂的变换(仿射、投影)来匹配。 OpenCV API 的最新功能之一是AKAZE特征提取器和检测器,它在计算速度和对变换的稳健性之间提供了非常好的折衷。 结果显示,AKAZE的表现优于其他突出特征,例如ORB(Oriented Brief的缩写)和SURF(加速健壮特征的缩写)。
以下代码片断将提取一个AKAZE关键点,为我们在imagesFilenames中收集的每个图像计算AKAZE个特征,并将它们分别保存在keypoints和descriptors数组中:
auto detector = AKAZE::create();
auto extractor = AKAZE::create();
for (const auto& i : imagesFilenames) {
Mat grayscale;
cvtColor(images[i], grayscale, COLOR_BGR2GRAY);
detector->detect(grayscale, keypoints[i]);
extractor->compute(grayscale, keypoints[i], descriptors[i]);
CV_LOG_INFO(TAG, "Found " + to_string(keypoints[i].size()) + "
keypoints in " + i);
}
注意,我们还将图像转换为灰度;但是,这一步可能会被省略,结果不会受到影响。
这是在两张相邻图像中检测到的特征的可视化。 注意其中有多少是重复的;这称为 FeatureRepeatability,这是一个好的特征提取器最需要的功能之一:

下一步是匹配每对图像之间的特征。 OpenCV 提供了一个出色的功能匹配套件。 AKAZE特征描述符是二进制,这意味着它们在匹配时不能被视为二进制编码数;它们必须在位级别上与逐位运算符进行比较。 OpenCV 为二进制特征匹配器提供了汉明距离度量,该度量实质上计算两位序列之间不正确匹配的数量:
vector<DMatch> matchWithRatioTest(const DescriptorMatcher& matcher,
const Mat& desc1,
const Mat& desc2)
{
// Raw match
vector< vector<DMatch> > nnMatch;
matcher.knnMatch(desc1, desc2, nnMatch, 2);
// Ratio test filter
vector<DMatch> ratioMatched;
for (size_t i = 0; i < nnMatch.size(); i++) {
const DMatch first = nnMatch[i][0];
const float dist1 = nnMatch[i][0].distance;
const float dist2 = nnMatch[i][1].distance;
if (dist1 < MATCH_RATIO_THRESHOLD * dist2) {
ratioMatched.push_back(first);
}
}
return ratioMatched;
}
前面的函数不仅定期调用我们的匹配器(例如,aBFMatcher(NORM_HAMMING)),它还执行比率测试。 这一简单的测试在许多依赖于特征匹配的计算机视觉算法(如 SfM、全景拼接、稀疏跟踪等)中是一个非常基本的概念。 我们不再为图像B中的图像A中的特征寻找单个匹配项,而是在图像B中查找两个匹配项,并确保没有混淆。 如果两个潜在的匹配特征描述符太相似(就它们的距离度量而言),并且我们不能区分它们中的哪一个是查询的正确匹配,则可能会在匹配中出现混淆,因此我们将它们都丢弃以防止混淆。
接下来,我们实现一个互易过滤器。 此过滤器仅允许在A至B、以及B至A中匹配(使用比率测试)的功能。 本质上,这是确保图像A和图像B:中的特征之间存在对称匹配的一对一匹配。 互易过滤器消除了更多的歧义,有助于实现更清晰、更稳健的匹配:
// Match with ratio test filter
vector<DMatch> match = matchWithRatioTest(matcher, descriptors[imgi], descriptors[imgj]);
// Reciprocity test filter
vector<DMatch> matchRcp = matchWithRatioTest(matcher, descriptors[imgj], descriptors[imgi]);
vector<DMatch> merged;
for (const DMatch& dmrecip : matchRcp) {
bool found = false;
for (const DMatch& dm : match) {
// Only accept match if 1 matches 2 AND 2 matches 1.
if (dmrecip.queryIdx == dm.trainIdx and dmrecip.trainIdx ==
dm.queryIdx) {
merged.push_back(dm);
found = true;
break;
}
}
if (found) {
continue;
}
}
最后,我们应用核线约束。 每两个图像之间有一个有效的刚性变换,它们将遵守对其特征点的核线约束: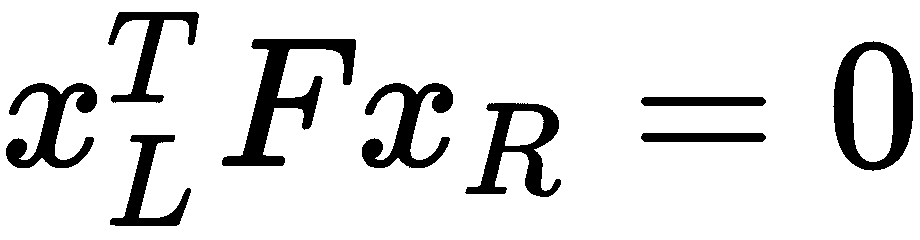 ,而那些没有通过此测试(获得足够成功)的图像很可能不是很好的匹配,并且可能会导致噪声。 我们通过使用投票算法(RANSAC)计算基本矩阵并检查内异值之比来实现这一点。 我们应用一个阈值来丢弃与原始匹配相比存活率较低的匹配:
,而那些没有通过此测试(获得足够成功)的图像很可能不是很好的匹配,并且可能会导致噪声。 我们通过使用投票算法(RANSAC)计算基本矩阵并检查内异值之比来实现这一点。 我们应用一个阈值来丢弃与原始匹配相比存活率较低的匹配:
// Fundamental matrix filter
vector<uint8_t> inliersMask(merged.size());
vector<Point2f> imgiPoints, imgjPoints;
for (const DMatch& m : merged) {
imgiPoints.push_back(keypoints[imgi][m.queryIdx].pt);
imgjPoints.push_back(keypoints[imgj][m.trainIdx].pt);
}
findFundamentalMat(imgiPoints, imgjPoints, inliersMask);
vector<DMatch> final;
for (size_t m = 0; m < merged.size(); m++) {
if (inliersMask[m]) {
final.push_back(merged[m]);
}
}
if ((float)final.size() / (float)match.size() < PAIR_MATCH_SURVIVAL_RATE) {
CV_LOG_INFO(TAG, "Final match '" + imgi + "'->'" + imgj + "' has less than "+to_string(PAIR_MATCH_SURVIVAL_RATE)+" inliers from orignal. Skip");
continue;
}
我们可以在下图中看到每个过滤步骤(原始匹配、比率、互易性和核线)的效果:

查找要素轨迹
特征轨迹的概念早在 1992 年 Tomasi 和 Kanade 的工作(Shape and Motion from Image Streams,1992)中就被引入到 SFM 文献中,并在 Snaful 和 Szeliski 于 2007 年因大规模无约束重建而在其开创性的摄影旅游工作中声名鹊起。 轨迹只是单个场景要素(一个有趣的点)在多个视图上的 2D 位置。 轨迹很重要,因为它们保持了帧之间的一致性,而不是像 Snaful 建议的那样,可以组合成全局优化问题。 轨迹对我们特别重要,因为 OpenCV 的sfm模块允许通过仅提供所有视图上的 2D 轨迹来重建场景:

在所有视图之间已经找到成对匹配之后,我们就有了在这些匹配特征中查找轨迹所需的信息。 如果我们沿着第一张图中的特征i通过匹配到第二张图,那么从第二张图到第三张图通过他们自己的匹配,以此类推,我们可能最终会得到它的轨迹。 这种记账方式很容易变得太难使用标准数据结构以简单的方式实现。 但是,如果我们表示匹配图中的所有匹配,就可以简单地完成。 图中的每个节点都是在一张图像中检测到的特征,边是我们恢复的匹配。 从第一个图像的特征节点到第二个图像、第三个图像、第四个图像的特征节点有许多边,依此类推(对于未被过滤器丢弃的匹配项)。 因为我们的匹配是相互的(对称的),所以图可以是无向的。 此外,互易性测试确保对于第一图像中的特征i,在第二图像、中只有一个匹配特征j,反之亦然:特征j将仅与特征i相匹配。
以下是这样的匹配图的可视示例。 节点颜色表示特征点(节点)的来源图像。 边缘表示图像特征之间的匹配。 我们可以注意到从第一张图像到最后一张图像的特征匹配链的非常强的模式:

要编码匹配图,我们可以使用Boost Graph Library(bgl),它具有广泛的图形处理和算法 API。 构建图形很简单;我们只需使用图像 ID 和 Feature ID 来增加节点,这样稍后我们就可以追溯原点:
using namespace boost;
struct ImageFeature {
string image;
size_t featureID;
};
typedef adjacency_list < listS, vecS, undirectedS, ImageFeature > Graph;
typedef graph_traits < Graph >::vertex_descriptor Vertex;
map<pair<string, int>, Vertex> vertexByImageFeature;
Graph g;
// Add vertices - image features
for (const auto& imgi : keypoints) {
for (size_t i = 0; i < imgi.second.size(); i++) {
Vertex v = add_vertex(g);
g[v].image = imgi.first;
g[v].featureID = i;
vertexByImageFeature[make_pair(imgi.first, i)] = v;
}
}
// Add edges - feature matches
for (const auto& match : matches) {
for (const DMatch& dm : match.second) {
Vertex& vI = vertexByImageFeature[make_pair(match.first.first, dm.queryIdx)];
Vertex& vJ = vertexByImageFeature[make_pair(match.first.second, dm.trainIdx)];
add_edge(vI, vJ, g);
}
}
查看结果图的可视化(使用boost::write_graphviz()),我们可以看到许多情况下我们的匹配是错误的。 坏的匹配链将涉及来自链中同一图像的多个特征。 我们在下图中标记了几个这样的实例;请注意,有些链具有两个或更多颜色相同的节点:
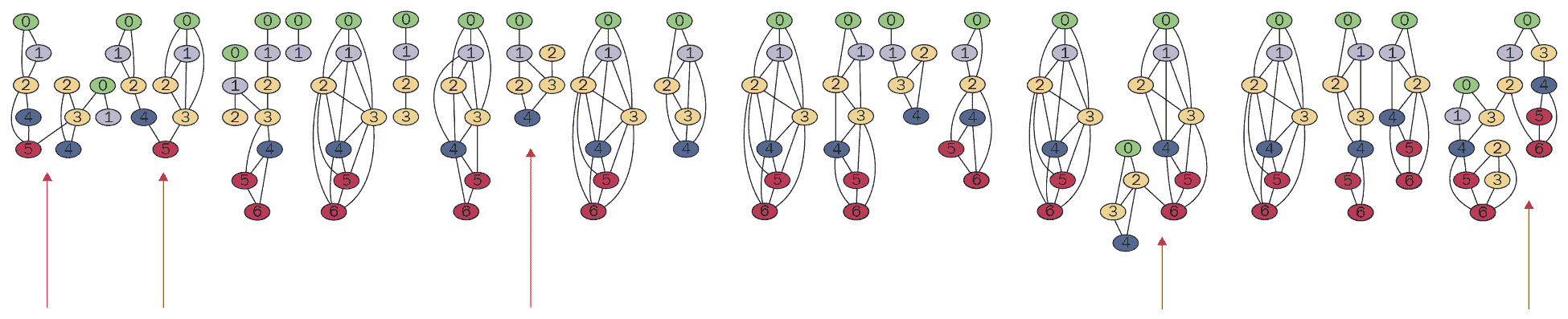
我们可以注意到,这些链本质上是图中的连通组件。 使用boost::connected_components()提取组件很简单:
// Get connected components
std::vector<int> component(num_vertices(gFiltered), -1);
int num = connected_components(gFiltered, &component[0]);
map<int, vector<Vertex> > components;
for (size_t i = 0; i != component.size(); ++ i) {
if (component[i] >= 0) {
components[component[i]].push_back(i);
}
}
我们可以过滤掉不好的成分(任何一幅图像中有多个特征),以得到干净的匹配图。
三维重建和可视化
原则上获得轨迹后,我们需要按照 OpenCV 的 SfM 模块期望的数据结构对齐它们。不幸的是,sfm模块没有很好的文档记录,所以这一部分我们必须从源代码中自己找出。 我们将调用cv::sfm::名称空间下的以下函数,该函数可以在opencv_contrib/modules/sfm/include/opencv2/sfm/reconstruct.hpp中找到:
void reconstruct(InputArrayOfArrays points2d, OutputArray Ps, OutputArray points3d, InputOutputArray K, bool is_projective = false);
下面opencv_contrib/modules/sfm/src/simple_pipeline.cpp文件提供了一个重要提示,说明该函数期望作为输入的内容:
static void
parser_2D_tracks( const std::vector<Mat> &points2d, libmv::Tracks &tracks )
{
const int nframes = static_cast<int>(points2d.size());
for (int frame = 0; frame < nframes; ++ frame) {
const int ntracks = points2d[frame].cols;
for (int track = 0; track < ntracks; ++ track) {
const Vec2d track_pt = points2d[frame].col(track);
if ( track_pt[0] > 0 && track_pt[1] > 0 )
tracks.Insert(frame, track, track_pt[0], track_pt[1]);
}
}
}
通常,sfm模块使用精简版本的libmvhttps://developer.blender.org/tag/libmv/(https://www.blender.org/),这是一个成熟的 SFM 软件包,用于使用 Blender 3D(Sfm)图形软件进行影院制作的 3D 重建。
我们可以告诉我们,需要将轨迹放在多个单独cv::Mat的向量中,其中每个都包含作为列的cv::Vec2d对齐列表,这意味着它有两行double。 我们还可以推断,轨迹中缺失(不匹配)的特征点将具有负坐标。 以下代码片断将从匹配图中提取所需数据结构中的轨迹:
vector<Mat> tracks(nViews); // Initialize to number of views
// Each component is a track
const size_t nViews = imagesFilenames.size();
tracks.resize(nViews);
for (int i = 0; i < nViews; i++) {
tracks[i].create(2, components.size(), CV_64FC1);
tracks[i].setTo(-1.0); // default is (-1, -1) - no match
}
int i = 0;
for (auto c = components.begin(); c != components.end(); ++ c, ++ i) {
for (const int v : c->second) {
const int imageID = imageIDs[g[v].image];
const size_t featureID = g[v].featureID;
const Point2f p = keypoints[g[v].image][featureID].pt;
tracks[imageID].at<double>(0, i) = p.x;
tracks[imageID].at<double>(1, i) = p.y;
}
}
我们继续运行重建功能,收集稀疏的 3D 点云和每个 3D 点的颜色,然后可视化结果(使用cv::viz::中的函数):
cv::sfm::reconstruct(tracks, Rs, Ts, K, points3d, true);
这将使用点云和相机位置生成稀疏重建,如下图所示:
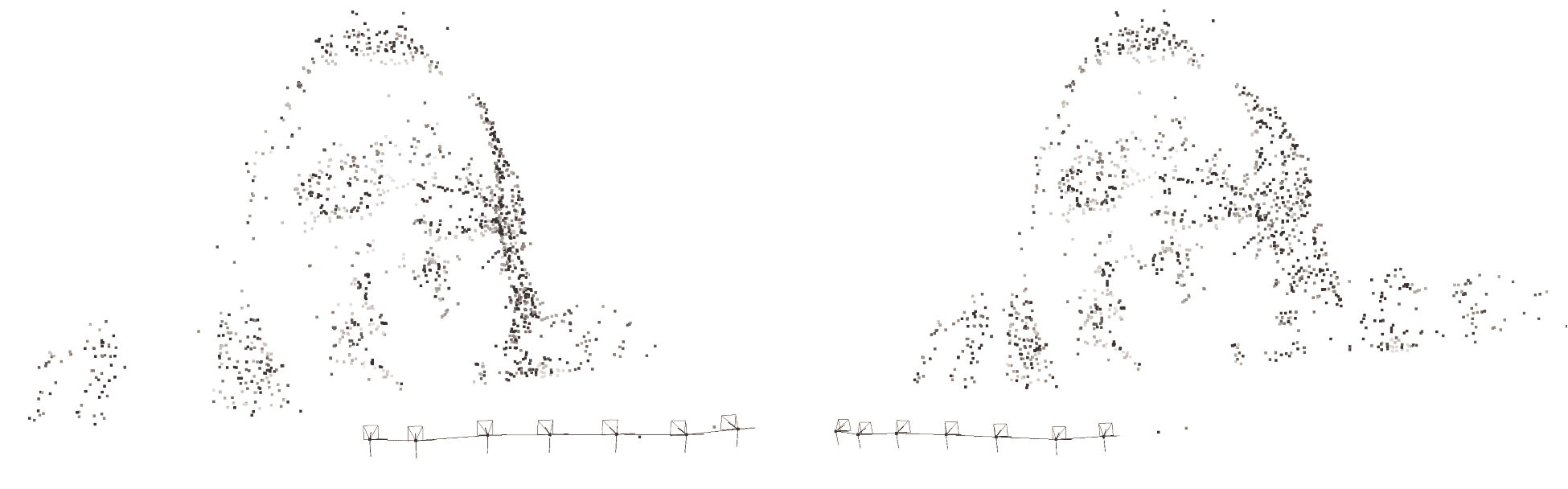
将 3D 点重新投影到 2D 图像上,我们可以验证正确的重建:

在附带的源代码存储库中查看重构和可视化的完整代码。
请注意,重建非常稀疏;我们只看到特征匹配的 3D 点。 在获取场景中对象的几何体时,这不会产生非常吸引人的效果。 在许多情况下,Sfm 管道不会以稀疏重建结束,这对许多应用(如 3D 扫描)没有用处。 接下来,我们将了解如何获得密集重建。
用于密集重建的 MVS
利用稀疏的三维点云和摄像机的位置,我们可以利用 MVS 进行密集重建。 在第一节中我们已经学习了 MVS 的基本概念;但是,我们不需要从头开始实现它,而是可以使用OpenMVS项目。 要使用 OpenMVS 进行云加密,我们必须将我们的项目保存为专门的格式。 OpenMVS 提供了一个用于保存和加载.mvs项目的类,即在MVS/Interface.h中定义的MVS::Interface类。
让我们从摄像机开始:
MVS::Interface interface;
MVS::Interface::Platform p;
// Add camera
MVS::Interface::Platform::Camera c;
c.K = Matx33d(K_); // The intrinsic matrix as refined by the bundle adjustment
c.R = Matx33d::eye(); // Camera doesn't have any inherent rotation
c.C = Point3d(0,0,0); // or translation
c.name = "Camera1";
const Size imgS = images[imagesFilenames[0]].size();
c.width = imgS.width; // Size of the image, to normalize the intrinsics
c.height = imgS.height;
p.cameras.push_back(c);
在添加相机姿势(视图)时,我们必须小心。 OpenMVS 希望获得相机的旋转和中心,而不是点投影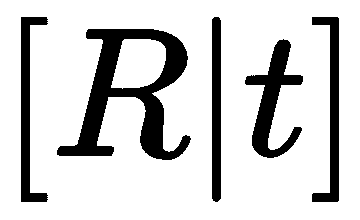 的相机姿势矩阵。 因此,我们必须通过应用反向旋转
的相机姿势矩阵。 因此,我们必须通过应用反向旋转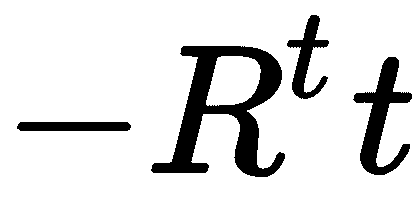 来平移平移向量以表示相机的中心:
来平移平移向量以表示相机的中心:
// Add views
p.poses.resize(Rs.size());
for (size_t i = 0; i < Rs.size(); ++ i) {
Mat t = -Rs[i].t() * Ts[i]; // Camera *center*
p.poses[i].C.x = t.at<double>(0);
p.poses[i].C.y = t.at<double>(1);
p.poses[i].C.z = t.at<double>(2);
Rs[i].convertTo(p.poses[i].R, CV_64FC1);
// Add corresponding image (make sure index aligns)
MVS::Interface::Image image;
image.cameraID = 0;
image.poseID = i;
image.name = imagesFilenames[i];
image.platformID = 0;
interface.images.push_back(image);
}
p.name = "Platform1";
interface.platforms.push_back(p);
在将点云也添加到Interface之后,我们可以在命令行中继续进行云的增密:
$ ${openMVS}/build/bin/DensifyPointCloud -i crazyhorse.mvs
18:48:32 [App ] Command line: -i crazyhorse.mvs
18:48:32 [App ] Camera model loaded: platform 0; camera 0; f 0.896x0.896; poses 7
18:48:32 [App ] Image loaded 0: P1000965.JPG
18:48:32 [App ] Image loaded 1: P1000966.JPG
18:48:32 [App ] Image loaded 2: P1000967.JPG
18:48:32 [App ] Image loaded 3: P1000968.JPG
18:48:32 [App ] Image loaded 4: P1000969.JPG
18:48:32 [App ] Image loaded 5: P1000970.JPG
18:48:32 [App ] Image loaded 6: P1000971.JPG
18:48:32 [App ] Scene loaded from interface format (11ms):
7 images (7 calibrated) with a total of 5.25 MPixels (0.75 MPixels/image)
1557 points, 0 vertices, 0 faces
18:48:32 [App ] Preparing images for dense reconstruction completed: 7 images (125ms)
18:48:32 [App ] Selecting images for dense reconstruction completed: 7 images (5ms)
Estimated depth-maps 7 (100%, 1m44s705ms)
Filtered depth-maps 7 (100%, 1s671ms)
Fused depth-maps 7 (100%, 421ms)
18:50:20 [App ] Depth-maps fused and filtered: 7 depth-maps, 1653963 depths, 263027 points (16%%) (1s684ms)
18:50:20 [App ] Densifying point-cloud completed: 263027 points (1m48s263ms)
18:50:21 [App ] Scene saved (489ms):
7 images (7 calibrated)
263027 points, 0 vertices, 0 faces
18:50:21 [App ] Point-cloud saved: 263027 points (46ms)
此过程可能需要几分钟才能完成。 然而,一旦它完成了,结果是非常令人印象深刻的。 密集的点云拥有惊人的263,027 个 3D 点,而稀疏云中只有 1,557 个点。 我们可以使用 OpenMVS 中捆绑的Viewer应用来可视化密集的 OpenMVS 项目:

OpenMVS 还有几个功能来完成重建,比如从密集的点云中提取三角网格。
简略的 / 概括的 / 简易判罪的 / 简易的
本章重点介绍了 SfM 及其使用 OpenCV 的sfm贡献模块和 OpenMVS 的实现。 探讨了多视点几何中的一些理论概念和几个实际问题:关键特征点的提取、匹配、匹配图的创建和分析、重建,最后对稀疏的三维点云进行 MVS 加密。
在下一章中,我们将了解如何使用 OpenCV 的face contrib模块检测照片中的人脸地标,以及如何使用solvePnP函数检测人脸指向的方向。**
