六、线性代数
本章包含以下方面的秘籍:
- 正交 Procrustes 问题
- 秩约束矩阵近似
- 主成分分析
- 线性方程组的求解系统(包括欠定和超定)
- 求解多项式方程
- 使用单纯形法进行线性规划
介绍
变量之间的线性相关性是所有可能选项中最简单的。 从近似和几何任务到数据压缩,相机校准和机器学习,它可以在许多应用中找到。 但是,尽管它很简单,但是当现实世界的影响发挥作用时,事情就会变得复杂。 从传感器收集的所有数据都包含一部分噪声,这可能导致线性方程组具有不稳定的解。 计算机视觉问题通常需要求解线性方程组。 即使在许多 OpenCV 函数中,这些线性方程也是隐藏的。 可以肯定的是,您将在计算机视觉应用中面对它们。 本章中的秘籍将使您熟悉线性代数的方法,这些方法可能有用并且实际上已在计算机视觉中使用。
正交 Procrustes 问题
最初,这个问题对寻找两个矩阵之间的正交变换的方式提出了质疑。 也许这与实际的计算机视觉应用无关,但是当您考虑到一组点确实是矩阵时,这种感觉可能会改变。 相机校准,刚体转换,摄影测量问题以及许多其他任务都需要解决正交 Procrustes 问题。 在本秘籍中,我们找到了估计点集旋转这一简单任务的解决方案,并研究了噪声输入数据如何影响我们的解决方案。
准备
在继续此秘籍之前,您需要安装 OpenCV 3.0(或更高版本)Python API 包。
操作步骤
您需要完成以下步骤:
- 导入模块:
import cv2
import numpy as np
- 生成初始点集。 然后通过将旋转矩阵应用于初始点来创建一组旋转点。 此外,向旋转点添加一部分噪声:
pts = np.random.multivariate_normal([150, 300], [[1024, 512], [512, 1024]], 50)
rmat = cv2.getRotationMatrix2D((0, 0), 30, 1)[:, :2]
rpts = np.matmul(pts, rmat.transpose())
rpts_noise = rpts + np.random.multivariate_normal([0, 0], [[200, 0], [0, 200]], len(pts))
- 使用奇异值分解(SVD)解决正交 Procrustes 问题,并获得旋转矩阵的估计值:
M = np.matmul(pts.transpose(), rpts_noise)
sigma, u, v_t = cv2.SVDecomp(M)
rmat_est = np.matmul(v_t, u).transpose()
- 现在我们可以使用估计的旋转矩阵来找出我们的估计有多好。 为此,请计算反向旋转矩阵,然后将我们先前旋转的点乘以该矩阵。 然后,计算有噪声和无噪声的旋转点之间,旋转的反向点与初始反向点之间以及原始旋转矩阵及其估计值之间的欧几里得距离(L2):
res, rmat_inv = cv2.invert(rmat_est)
assert res != 0
pts_est = np.matmul(rpts, rmat_inv.transpose())
rpts_err = cv2.norm(rpts, rpts_noise, cv2.NORM_L2)
pts_err = cv2.norm(pts_est, pts, cv2.NORM_L2)
rmat_err = cv2.norm(rmat, rmat_est, cv2.NORM_L2)
- 显示我们的数据,将初始点显示为绿色圆圈,将旋转点显示为黄色圆圈,将反向点显示为白色细圆圈,将具有噪声的旋转点显示为红色细圆圈。 然后,打印有关点和矩阵之间的 L2 差的信息,并显示结果图像:
def draw_pts(image, points, color, thickness=cv2.FILLED):
for pt in points:
cv2.circle(img, tuple([int(x) for x in pt]), 10, color, thickness)
img = np.zeros([512, 512, 3])
draw_pts(img, pts, (0, 255, 0))
draw_pts(img, pts_est, (255, 255, 255), 2)
draw_pts(img, rpts, (0, 255, 255))
draw_pts(img, rpts_noise, (0, 0, 255), 2)
cv2.putText(img, 'R_points L2 diff: %.4f' % rpts_err, (5, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2)
cv2.putText(img, 'Points L2 diff: %.4f' % pts_err, (5, 60), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2)
cv2.putText(img, 'R_matrices L2 diff: %.4f' % rmat_err, (5, 90), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2)
cv2.imshow('Points', img)
cv2.waitKey()
cv2.destroyAllWindows()
工作原理
为了找到正交 Procrustes 问题的解决方案,我们将 SVD 应用于两个矩阵的乘积:由初始点组成的矩阵和由旋转后的点组成的另一个矩阵。 每个矩阵中的行是对应点的(x,y)坐标。 SVD 方法是众所周知的,可以使噪声结果稳定。 cv2.SVDecomp是在 OpenCV 中实现 SVD 的函数。 它接受一个矩阵(MxN)进行分解并返回三个矩阵。 返回的第一个矩阵是大小为MxN的矩形对角矩阵,对角线上的正数称为奇异值。 第二矩阵和第三矩阵分别是左奇异向量矩阵和右奇异向量矩阵的共轭转置。
SVD 是线性代数中非常方便的工具。 它能够产生可靠的解决方案,因此在许多不同的任务中经常使用。 我们不会深入研究 SVD 的理论,因为它是一个独立且确实是广泛的主题。 但是,我们将在本章后面的其他秘籍中了解此过程。
让我们还回顾一下前面代码中的 OpenCV 的另一个函数。 本书以前没有提到cv2.getRotationMatrix2D函数。 它为给定的旋转中心和角度以及比例尺计算仿射变换矩阵。 参数按以下顺序排列:旋转中心(格式为(x,y),旋转角度(以度为单位),比例。 返回的值是2x3仿射变换矩阵。
cv2.invert找到给定一个矩阵的伪逆矩阵。 此函数接受要求逆的矩阵,并选择接受结果和求逆方法标志的矩阵。 默认情况下,该标志设置为cv2.DECOMP_LU,它将应用 LU 分解来查找结果。 另外,cv2.DECOMP_SVD和cv2.DECOMP_CHOLESKY也可以作为选项使用; 第一个使用 SVD 查找伪逆矩阵(是,这是 SVD 的另一个应用),第二个使用 Cholesky 分解实现相同的目的。 该函数返回两个对象,一个float值和所得的倒置矩阵。 如果第一个返回值为 0,则输入矩阵为奇数。 在这种情况下,cv2.DECOMP_LU和cv2.DECOMP_CHOLESKY无法产生结果,但是cv2.DECOMP_SVD计算伪逆矩阵。
从当前秘籍启动代码的结果是,您将获得与以下内容类似的结果:
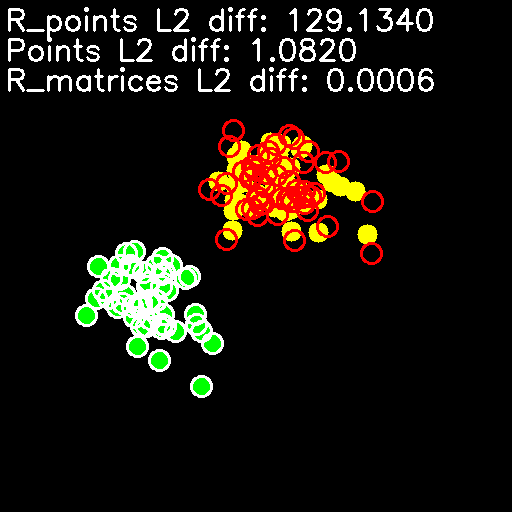
如您所见,尽管添加噪声前后的点之间的差异相对较大,但初始点和估计点与旋转矩阵之间的差异很小。
如果您对 SVD 的理论感兴趣,那么此 Wikipedia 页面是一个不错的起点。
秩约束矩阵近似
在本秘籍中,您将学习如何计算秩相关矩阵近似值。 该问题被表述为优化问题。 给定一个输入矩阵,目的是找到它的近似值,在该近似值下,使用 Frobenius 范数测量拟合,并且输出矩阵的秩不应大于给定值。 除其他领域外,此功能还用于数据压缩和机器学习。
准备
在继续此秘籍之前,您需要安装 OpenCV 3.0(或更高版本)Python API 包。
操作步骤
您需要完成以下步骤:
- 导入模块:
import cv2
import numpy as np
- 生成一个随机矩阵:
A = np.random.randn(10, 10)
- 计算 SVD:
w, u, v_t = cv2.SVDecomp(A)
- 计算秩约束矩阵近似值:
RANK = 5
w[RANK:,0] = 0
B = u @ np.diag(w[:,0]) @ v_t
- 检查结果:
print('Rank before:', np.linalg.matrix_rank(A))
print('Rank after:', np.linalg.matrix_rank(B))
print('Norm before:', cv2.norm(A))
print('Norm after:', cv2.norm(B))
工作原理
Eckart-Young-Mirsky 定理指出,可以通过计算 SVD(使用cv2.SVDecomp函数)并构造一个近似值(最小的奇异值设置为零)来解决问题,因此近似值等级不大于所需的值。 值。
输出如下所示:
Rank before: 10
Rank after: 5
Norm before: 9.923378133354824
Norm after: 9.511025831320431
主成分分析
主成分分析(PCA)旨在确定维度在数据中的重要性并建立新的基础。 在这个新的基础上,选择的方向要与其他方向具有最大的独立性。 由于具有最大的独立性,我们可以了解哪些数据维度承载更多信息,哪些数据维度承载较少。 PCA 用于许多应用,主要用于数据分析和数据压缩,但也可以用于计算机视觉。 例如,确定并跟踪物体的方向。 此秘籍将向您展示如何在 OpenCV 中进行操作。
准备
在继续此秘籍之前,您需要安装 OpenCV 3.0(或更高版本)Python API 包。
操作步骤
您需要完成以下步骤:
- 导入我们需要的模块:
import cv2
import numpy as np
- 定义将 PCA 应用于轮廓点并确定新基础的函数:
def contours_pca(contours):
# join all contours points into the single matrix and remove unit dimensions
cnt_pts = np.vstack(contours).squeeze().astype(np.float32)
mean, eigvec = cv2.PCACompute(cnt_pts, None)
center = mean.squeeze().astype(np.int32)
delta = (150*eigvec).astype(np.int32)
return center, delta
- 定义一个函数,该函数显示将 PCA 应用于轮廓点的结果:
def draw_pca_results(image, contours, center, delta):
cv2.drawContours(image, contours, -1, (255, 255, 0))
cv2.line(image, tuple((center + delta[0])),
tuple((center - delta[0])),
(0, 255, 0), 2)
cv2.line(image, tuple((center + delta[1])),
tuple((center - delta[1])),
(0, 0, 255), 2)
cv2.circle(image, tuple(center), 20, (0, 255, 255), 2)
- 打开视频并逐帧分析。 对于每个框架,找到轮廓并将 PCA 应用于找到的轮廓。 然后,显示结果:
cap = cv2.VideoCapture("../data/opencv_logo.mp4")
while True:
status_cap, frame = cap.read()
if not status_cap:
break
frame = cv2.resize(frame, (0, 0), frame, 0.5, 0.5)
edges = cv2.Canny(frame, 250, 150)
_, contours, _ = cv2.findContours(edges, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
if len(contours):
center, delta = contours_pca(contours)
draw_pca_results(frame, contours, center, delta)
cv2.imshow('PCA', frame)
if cv2.waitKey(100) == 27:
break
cv2.destroyAllWindows()
工作原理
使用 PCA 跟踪对象方向的主要思想是在旋转过程中对象不会发生变化。 因为它是同一对象,但方向不同,所以它具有自己的基础,并且该基础与对象一起旋转。 因此,我们需要在每时每刻确定这个基础,以找到物体的方向。 如果我们有正确的数据要分析,PCA 可以找到这样的基础。 让我们使用对象轮廓的点。 当然,它们在旋转过程中会更改其绝对位置,但会与对象一起旋转。 在每个方向上,轮廓的点都沿最大方向变化。 而且由于旋转不会使轮廓倾斜或扭曲,因此这些方向随对象旋转。
顾名思义,cv2.PCACompute实现了 PCA。 它找到数据协方差矩阵的特征向量和特征值。 此函数有两个重载。 我们在前面的代码中使用的第一个选项接受一个要分析的数据矩阵,一个预先计算的平均值,一个写计算出的特征向量的矩阵以及一些要返回的向量。 最后两个参数是可选的,可以省略(在这种情况下,将返回所有向量)。 同样,如果没有预先计算的平均值,则可以将第二个参数设置为“无”。 在这种情况下,该函数也会计算平均值。 数据矩阵通常是一组样本。 每个样本具有多个维度D,并且总体上有N个样本。 在这种情况下,数据矩阵必须为NxD,N行也必须为NxD,并且每一行都是一个单独的样本。
如前所述,cv2.PCACompute存在第二个过载。 如前所述,它接受要分析的数据矩阵,并将预先计算的平均值作为前两个参数。 第三和第四参数是保留方差与存储计算向量的对象的比率。 该比率通过其方差确定要返回的向量数,比率越不平衡,保留的向量数就越大。 此参数允许您不固定向量的数量,而只保留方差最大的向量。
代码执行的结果是,您将获得类似于以下内容的图像:

线性方程组的求解系统(包括欠定和超定)
在本秘籍中,您将学习如何使用 OpenCV 求解线性方程组。 此功能是许多计算机视觉和机器学习算法的关键构建块。
准备
在继续此秘籍之前,您需要安装 OpenCV 3.3(或更高版本)Python API 包。
操作步骤
您需要完成以下步骤:
- 导入模块:
import cv2
import numpy as np
- 生成线性方程组:
N = 10
A = np.random.randn(N,N)
while np.linalg.matrix_rank(A) < N:
A = np.random.randn(N,N)
x = np.random.randn(N,1)
b = A @ x
- 求解线性方程组:
ok, x_est = cv2.solve(A, b)
print('Solved:', ok)
if ok:
print('Residual:', cv2.norm(b - A @ x_est))
print('Relative error:', cv2.norm(x_est - x) / cv2.norm(x))
- 构造一个超定线性方程组:
N = 10
A = np.random.randn(N*2,N)
while np.linalg.matrix_rank(A) < N:
A = np.random.randn(N*2,N)
x = np.random.randn(N,1)
b = A @ x
- 求解超定线性方程组:
ok, x_est = cv2.solve(A, b, flags=cv2.DECOMP_NORMAL)
print('\nSolved overdetermined system:', ok)
if ok:
print('Residual:', cv2.norm(b - A @ x_est))
print('Relative error:', cv2.norm(x_est - x) / cv2.norm(x))
- 构建一个不确定的线性方程组系统,该系统具有多个解决方案:
N = 10
A = np.random.randn(N,N*2)
x = np.random.randn(N*2,1)
b = A @ x
- 解决欠定线性方程组。 查找具有最小规范的解决方案:
w, u, v_t = cv2.SVDecomp(A, flags=cv2.SVD_FULL_UV)
mask = w > 1e-6
w[mask] = 1 / w[mask]
w_pinv = np.zeros((A.shape[1], A.shape[0]))
w_pinv[:N,:N] = np.diag(w[:,0])
A_pinv = v_t.T @ w_pinv @ u.T
x_est = A_pinv @ b
print('\nSolved underdetermined system')
print('Residual:', cv2.norm(b - A @ x_est))
print('Relative error:', cv2.norm(x_est - x) / cv2.norm(x))
工作原理
线性方程组可以使用 OpenCV 的cv2.solve函数求解。 它接受一个系数矩阵,系统的右侧和可选标志,然后返回一个解决方案(准确地说是成功指标和解决方案向量)。 如您在第一个示例中所看到的,它可用于解决具有独特解决方案的系统。
您可以指定cv2.DECOMP_NORMAL标志,在这种情况下,将构建内部标准化的线性方程组。 这可以用来解决带有一个或没有解的超定系统,在后一种情况下,返回最小二乘问题的解。
一个欠定的线性方程组没有或有多个解。 在前面的代码中,我们构建了具有多个解决方案的系统。 可以使用 Moore-Penrose 逆(代码中的A_pinv)找到具有最小范数的解。 由于存在多种解决方案,相对于我们用来生成系统右侧的解决方案,我们发现的解决方案可能会有更多错误。
这是预期输出的示例:
Solved: True
Residual: 2.7194799110210367e-15
Relative error: 1.1308382847616332e-15
Solved overdetermined system: True
Residual: 4.418021593470969e-15
Relative error: 5.810798787243048e-16
Solved underdetermined system
Residual: 9.296750665059115e-15
Relative error: 0.7288729621745673
求解多项式方程
在本秘籍中,您将学习如何使用 OpenCV 求解多项式方程。 这样的问题可能出现在诸如机器学习,计算代数和信号处理等领域。
准备
在继续此秘籍之前,您需要安装 OpenCV 3.3(或更高版本)Python API 包。
操作步骤
您需要完成以下步骤:
- 导入模块:
import cv2
import numpy as np
- 生成四次多项式方程:
N = 4
coeffs = np.random.randn(N+1,1)
- 找到复数域中的所有根:
retval, roots = cv2.solvePoly(coeffs)
- 检查根:
for i in range(N):
print('Root', roots[i],'residual:',
np.abs(np.polyval(coeffs[::-1], roots[i][0][0]+1j*roots[i][0][1])))
工作原理
度为n的多项式方程在复数域中始终具有n根(但是其中一些可以重复)。 使用cv2.solvePoly函数可以找到所有解决方案。 它采用方程系数并返回所有根。
这是预期输出的示例:
Root [[ 0.0494519 1.12199842]] residual: [ 1.50920942e-16]
Root [[-0.17045556 0\. ]] residual: [ 0.]
Root [[ 0.0494519 -1.12199842]] residual: [ 1.50920942e-16]
Root [[-8.1939051 0\. ]] residual: [ 1.80133686e-14]
使用单纯形法的线性规划
在本秘籍中,我们考虑优化问题的一种特殊情况,即线性约束问题。 这些任务意味着您需要考虑一组线性约束来优化(最大化或最小化)正变量的线性组合。 线性规划在计算机视觉中没有众所周知的直接应用,但是您可能会在以后遇到它。 因此,让我们看看如何使用 OpenCV 处理线性规划问题。
准备
在继续此秘籍之前,您需要安装 OpenCV 3.0(或更高版本)Python API 包。
操作步骤
您需要完成以下步骤:
- 导入模块:
import cv2
import numpy as np
- 为函数创建一个线性约束矩阵和权重,我们将对其进行优化:
m = 10
n = 10
constraints_mat = np.random.randn(m, n+1)
weights = np.random.randn(1, n)
- 通过调用
cv2.solveLP将单纯形方法应用于任务。 然后,解析结果:
solution = np.array((n, 1), np.float32)
res = cv2.solveLP(weights, constrains_mat, solution)
if res == cv2.SOLVELP_SINGLE:
print('The problem has the one solution')
elif res == cv2.SOLVELP_MULTI:
print('The problem has the multiple solutions')
elif res == cv2.SOLVELP_UNBOUNDED:
print('The solution is unbounded')
elif res == cv2.SOLVELP_UNFEASIBLE:
print('The problem doesnt\'t have any solutions')
工作原理
cv2.solveLP接受三个参数:函数的权重,线性约束矩阵和用于保存结果的 NumPy 数组对象。 权重由浮点值向量(N, 1)或(1, N)表示。 该向量的长度也意味着优化参数的数量。 线性约束矩阵是(M, N + 1)NumPy 数组,其中最后一列包含每个约束和每一行的常数项,最后一个元素除外,最后一个元素为相应的参数包含系数。 最后一个参数旨在存储解决方案(如果存在)。
通常,线性规划问题有四种可能的结果,它们可能只有一个解决方案,很多解决方案(在一定范围内),或者根本没有确定的解决方案。 在后一种情况下,问题可能是无限的或不可行的。 对于所有这四个结果,cv2.solveLP返回相应的值:cv2.SOLVELP_SINGLE,cv2.SOLVELP_MULTI,cv2.SOLVELP_UNBOUNDED或v2.SOLVELP_UNFEASIBLE。
