五、自动光学检查、对象分割和检测
在第 4 章,深入研究直方图和过滤器中,我们了解了直方图和过滤器,它们使我们能够理解图像操作并创建照片应用。
在本章中,我们将介绍目标分割和检测的基本概念。 这意味着隔离图像中出现的对象以供将来处理和分析。
本章介绍以下主题:
- 去噪
- 灯光/背景移除基础知识
- 阈值设置
- 用于对象分割的连通分量
- 寻找轮廓以进行对象分割
许多行业使用复杂的计算机视觉系统和硬件。 计算机视觉试图发现问题并将生产过程中产生的错误降至最低,从而提高最终产品的质量。
在此区域中,此计算机视觉任务的名称为自动光学检测(AOI)。 这个名字出现在印刷电路板制造商的检查中,一个或多个摄像头扫描每个电路,以检测关键故障和质量缺陷。 这个术语被用于其他制造业,这样他们就可以使用光学摄像系统和计算机视觉算法来提高产品质量。 如今,光学检测根据需要使用不同的摄像机类型(红外或 3D 摄像机),复杂的算法被用于数千个行业的不同目的,如缺陷检测、分类等。
技术要求
本章要求熟悉基本的 C++ 编程语言。 本章中使用的所有代码都可以从以下 giHub 链接下载:https://github.com/PacktPublishing/Building-Computer-Vision-Projects-with-OpenCV4-and-CPlusPlus/tree/master/Chapter05。 该代码可以在任何操作系统上执行,尽管它只在 Ubuntu 上进行了测试。
请查看以下视频,了解实际操作中的代码: http://bit.ly/2DRbMbz
隔离场景中的对象
在本章中,我们将介绍 AOI 算法的第一步,并尝试分离场景中的不同部分或对象。 我们将以三种对象类型(螺丝、密封环和螺母)的对象检测和分类为例,在本章和第 6 章、学习对象分类中对其进行开发。
假设我们在一家生产这三种产品的公司。 它们都在同一条载带上。 我们的目标是检测载带中的每个物体,并对每个物体进行分类,以便机器人将每个物体放到正确的架子上:
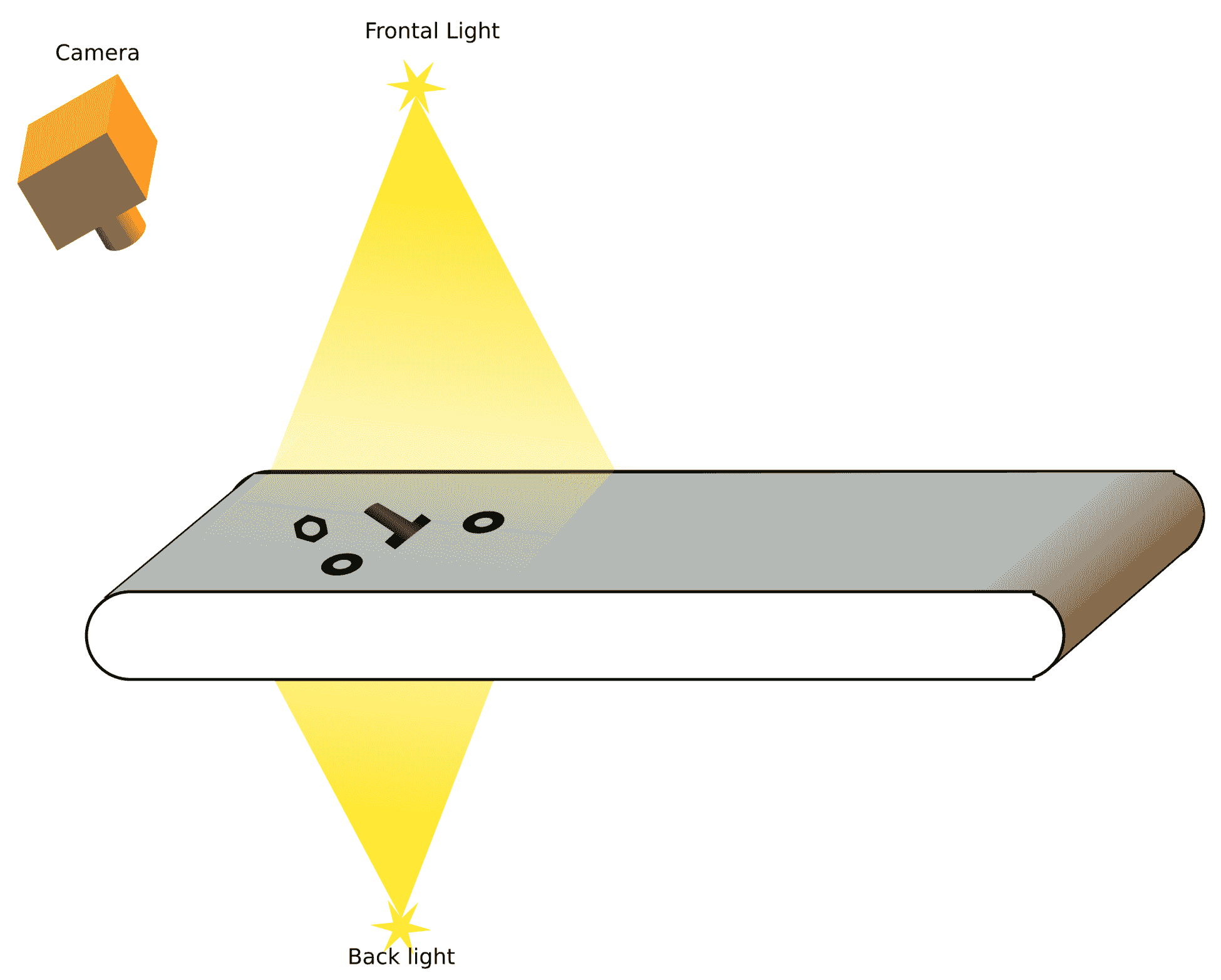
在本章中,我们将学习如何隔离每个对象并检测其在图像中的位置(以像素为单位)。 在下一章中,我们将学习如何对每个孤立的物体进行分类,以识别它是螺母、螺丝还是密封圈。
在下面的屏幕截图中,我们显示了我们想要的结果,其中左侧图像中有几个对象。 在右图中,我们用不同的颜色绘制了每一个,显示了不同的特征,如面积、高度、宽度和轮廓大小:

为了达到这一结果,我们将遵循不同的步骤,使我们能够更好地理解和组织我们的算法。 我们可以在下图中看到这些步骤:
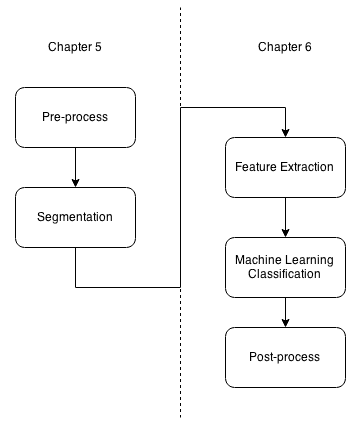
我们的申请将分为两章。 在本章中,我们将开发和理解预处理和分割步骤。 在第 6 章,学习对象分类中,我们将提取每个分割对象的特征,并训练我们的机器学习系统/算法如何识别每个对象类。
我们的预处理步骤将分为另外三个子集:
- 噪声消除
- 光移除
- 二值化
在分段步骤中,我们将使用两种不同的算法:
- 轮廓检测
- 连通分量提取(标记)
我们可以在下图中看到这些步骤和应用流程:

现在,是开始预处理步骤的时候了,这样我们就可以通过去除噪声和光照效果来获得最佳的二值化图像。 这最大限度地减少了任何可能的检测错误。
为 AOI 创建应用
要创建我们的新应用,我们需要一些输入参数。 当用户执行应用时,除了要处理的输入图像外,所有这些都是可选的。 输入参数如下:
- 要处理的输入图像
- 光像图案
- 轻操作,用户可以在差或除操作之间进行选择
- 如果用户将
0设置为值,则应用差值运算 - 如果用户将
1设置为值,则应用除法运算 - 分段,用户可以在具有或不具有统计数据的连接组件之间进行选择,并查找等高线方法
- 如果用户将
1设置为输入值,则应用分段的连通分量方法 - 如果用户将
2设置为输入值,则应用带有统计区域的连通分量方法 - 如果用户将
3设置为输入值,则会应用查找等值线方法进行分段
要启用此用户选择,我们将使用带有以下键的command line parser类:
// OpenCV command line parser functions
// Keys accepted by command line parser
const char* keys =
{
"{help h usage ? | | print this message}"
"{@image || Image to process}"
"{@lightPattern || Image light pattern to apply to image input}"
"{lightMethod | 1 | Method to remove background light, 0 difference, 1 div }"
"{segMethod | 1 | Method to segment: 1 connected Components, 2 connected components with stats, 3 find Contours }"
};
我们将通过检查参数在main函数中使用command line parser类。 在阅读视频和摄像机部分的第 2 章,OpenCV基础简介中解释了CommandLineParser:
int main(int argc, const char** argv)
{
CommandLineParser parser(argc, argv, keys);
parser.about("Chapter 5\. PhotoTool v1.0.0");
//If requires help show
if (parser.has("help"))
{
parser.printMessage();
return 0;
}
String img_file= parser.get<String>(0);
String light_pattern_file= parser.get<String>(1);
auto method_light= parser.get<int>("lightMethod");
auto method_seg= parser.get<int>("segMethod");
// Check if params are correctly parsed in his variables
if (!parser.check())
{
parser.printErrors();
return 0;
}
解析命令行用户数据后,我们需要检查输入图像是否已正确加载。 然后,我们加载图像并检查其是否包含数据:
// Load image to process
Mat img= imread(img_file, 0);
if(img.data==NULL){
cout << "Error loading image "<< img_file << endl;
return 0;
}
现在,我们准备创建我们的 AOI 细分流程。 我们将从预处理任务开始。
对输入图像进行预处理
本节介绍在对象分割/检测上下文中可以应用于图像预处理的一些最常见的技术。 预处理是我们在开始工作并从中提取所需信息之前对新图像所做的第一个更改。 通常,在预处理步骤中,我们会尽量减少由相机镜头引起的图像噪声、光线条件或图像变形。 这些步骤在检测图像中的对象或片段时将误差降至最低。
去噪
如果我们不去除噪声,我们可以检测到比我们预期更多的目标,因为噪声通常表示为图像中的小点,并且可以被分割为一个目标。 传感器和扫描仪电路通常会产生此噪声。 这种亮度或颜色的变化可以用不同的类型来表示,例如高斯噪声、尖峰噪声和散粒噪声。
可以使用不同的技术来消除噪音。 这里,我们将使用平滑操作,但根据噪声类型的不同,有些比另一些要好。 中值滤波器通常用于去除胡椒噪声;例如,请考虑下图:
前一幅图像是带有盐和胡椒噪声的原始输入。 如果我们应用中间模糊,我们会得到一个很棒的结果,其中会丢失一些小细节。 例如,我们丢失了螺钉的边缘,但我们保持了完美的边缘。 请参见下图中的结果:
如果我们应用盒过滤器或高斯过滤器,噪声不会被去除,而是变得平滑,对象的细节也会丢失和平滑。 有关结果,请参见下图:
OpenCV 提供了medianBlur函数,它需要三个参数:
- 具有
1、3或4通道图像的输入图像。 当内核大小大于5时,图像深度只能为CV_8U。 -
输出图像,它是应用与输入相同类型和深度的中间模糊的结果图像。
-
内核大小,它是大于
1的奇数孔径大小,例如 3、5、7 等等。
以下代码用于消除噪音:
Mat img_noise;
medianBlur(img, img_noise, 3);
使用用于分割的光图案去除背景
在这一部分中,我们将开发一个基本算法,使我们能够使用灯光模式删除背景。 这种预处理可以给我们更好的分割效果。 无噪声的输入图像如下:

如果我们应用一个基本阈值,我们将获得如下图像结果:
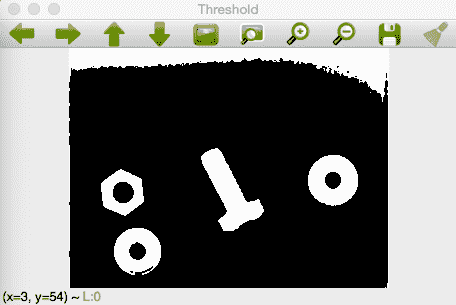
我们可以看到上面的图像伪像有很多白噪声。 如果我们应用光模式和背景去除技术,我们可以得到令人惊叹的结果,我们可以看到在图像的顶部没有像以前的阈值操作那样的伪影,当我们需要分割的时候,我们会得到更好的结果。 我们可以在下图中看到背景去除和阈值处理的结果:
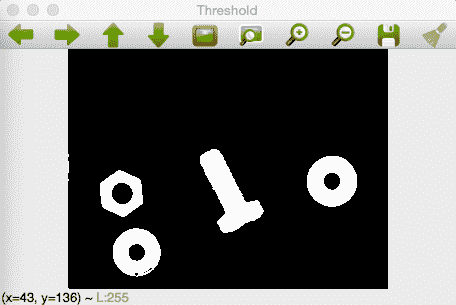
现在,我们如何才能将光线从我们的图像中移除呢? 这很简单:我们只需要一张没有任何物体的场景照片,从与拍摄其他图像完全相同的位置和照明条件下拍摄;这是 AOI 中的一种非常常见的技术,因为外部条件是受监督和众所周知的。 本例的图像结果类似于下图:

现在,使用一个简单的数学运算,我们可以移除这个光图案。 删除它有两个选项:
- 差异 / 不同 / 争执
- 分歧 / 除 / 部分 / 部门
差异选项是最简单的方法。 如果我们具有光图案L和图像画面I,则由此产生的移除R是它们之间的差值:
R= L-I
这种划分比较复杂,但同时也很简单。 如果我们具有光图案矩阵L和图像画面矩阵I,则结果去除R如下:
R= 255*(1-(I/L))
在这种情况下,我们将图像除以光图案,并假设如果我们的光图案是白色的,并且对象比背景载体带更暗,则图像像素值始终等于或低于光像素值。 我们从I/L得到的结果介于0和1之间。 最后,我们将该除法的结果倒置以得到相同的颜色方向范围,并将其乘以255以得到0-255范围内的值。
在我们的代码中,我们将使用以下参数创建一个名为removeLight的新函数:
- 用于移除灯光/背景的输入图像
- 光图案,
Mat - 一种方法,用
0值表示差,1表示除法
结果是一个没有光/背景的新图像矩阵。 下面的代码通过使用灯光图案实现背景的移除:
Mat removeLight(Mat img, Mat pattern, int method)
{
Mat aux;
// if method is normalization
if(method==1)
{
// Require change our image to 32 float for division
Mat img32, pattern32;
img.convertTo(img32, CV_32F);
pattern.convertTo(pattern32, CV_32F);
// Divide the image by the pattern
aux= 1-(img32/pattern32);
// Convert 8 bits format and scale
aux.convertTo(aux, CV_8U, 255);
}else{
aux= pattern-img;
}
return aux;
}
让我们来探讨一下这个问题。 创建aux变量保存结果后,我们选择用户选择的方法并将参数传递给函数。 如果选择的方法是1,则应用除法。
除法需要 32 位浮点型图像,这样我们就可以划分图像,而不是将数字截断为整数。 第一步是将图像和光图案垫转换为 32 位浮点数。 要转换此格式的图像,可以使用Mat类的convertTo函数。 此函数接受四个参数;输出转换的图像和要转换为所需参数的格式,但您可以定义 alpha 和 beta 参数,这些参数允许您缩放和移动下一个函数后面的值,其中O是输出图像,I是输入图像:
O(x,y)=cast<Type>(αI(x,y)+β*)
下面的代码将图像更改为 32 位浮点:
// Required to change our image to 32 float for division
Mat img32, pattern32;
img.convertTo(img32, CV_32F);
pattern.convertTo(pattern32, CV_32F);
现在,我们可以对我们的矩阵执行如上所述的数学运算,方法是将图像除以图案并反转结果:
// Divide the image by the pattern
aux= 1-(img32/pattern32);
现在,我们有了结果,但需要将其返回到 8 位深度图像,然后像前面一样使用 Convert 函数转换图像的mat,并使用 alpha 参数从0缩放到255:
// Convert 8 bits format
aux.convertTo(aux, CV_8U, 255);
现在,我们可以将aux变量与结果一起返回。 对于差分方法,开发非常容易,因为我们不需要转换图像;我们只需要应用模式和图像之间的差异并返回它。 如果我们不假设图案等于或大于图像,则需要进行几次检查并截断值,这些值可以小于0或大于255:
aux= pattern-img;
以下图像是将图像灯光图案应用于我们的输入图像的结果:
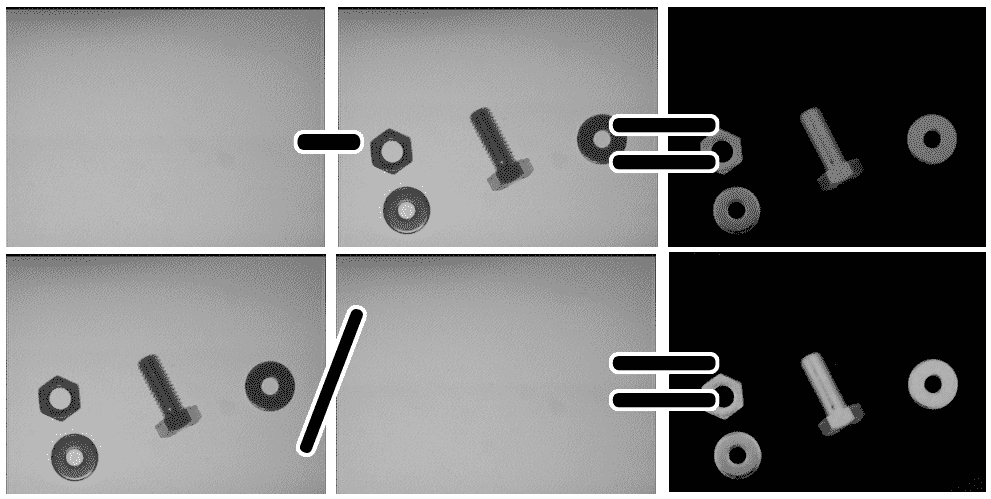
在我们得到的结果中,我们可以检查光线渐变和可能的伪影是如何被去除的。 但是当我们没有灯光/背景图案时会发生什么呢? 有几种不同的技术可以实现这一点;我们将在这里介绍最基本的一种。 使用滤镜,我们可以创建一个可以使用的滤镜,但有更好的算法来了解图像的背景,其中碎片出现在不同的区域。 这项技术有时需要背景估计图像初始化,我们的基本方法可以很好地发挥作用。 这些高级技术将在第 8 章、视频监控、背景建模和形态运算中进行探讨。 为了估计背景图像,我们将使用具有较大内核大小的模糊来应用于我们的输入图像。 这是在光学字符识别(OCR)中使用的常用技术,其中字母相对于整个文档较薄且较小,允许我们对图像中的光图案进行近似。 我们可以在左手图像中看到灯光/背景图案重建,在右手图像中可以看到地面实况:

我们可以看到灯光图案有一些细微的差异,但这一结果足以去除背景。 当使用不同的图像时,我们也可以在下图中看到结果。 在下图中,描述了应用原始输入图像和使用前一种方法计算的估计背景图像之间的图像差的结果:

calculateLightPattern函数创建此灯光图案或背景近似值:
Mat calculateLightPattern(Mat img)
{
Mat pattern;
// Basic and effective way to calculate the light pattern from one image
blur(img, pattern, Size(img.cols/3,img.cols/3));
return pattern;
}
此基本函数通过使用相对于图像大小较大的内核大小来对输入图像应用模糊。 从代码来看,它是原来宽度和高度的。
**# 阈值设置
在去除背景之后,我们只需要对图像进行二值化,以便将来进行分割。 我们要用 Threshold 来做这件事。 Threshold是一个简单的函数,它将每个像素的值设置为最大值(例如 255)。 如果像素的值大于阈值值,或者如果像素的值小于阈值值,则它将被设置为最小值(0):
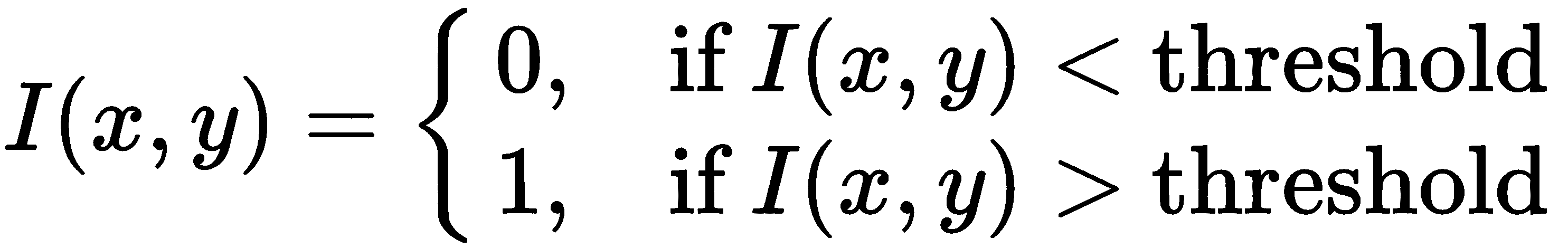
现在,我们将使用两个不同的threshold值来应用threshold函数:当我们移除灯光/背景时,我们将使用 30threshold值,因为所有不感兴趣的区域都是黑色的。 这是因为我们应用了背景移除。 当我们不使用灯光移除方法时,我们还将使用中值threshold(140),因为我们使用的是白色背景。 最后一个选项用于允许我们在删除和不删除背景的情况下检查结果:
// Binarize image for segment
Mat img_thr;
if(method_light!=2){
threshold(img_no_light, img_thr, 30, 255, THRESH_BINARY);
}else{
threshold(img_no_light, img_thr, 140, 255, THRESH_BINARY_INV);
}
现在,我们将继续我们应用中最重要的部分:分割。 这里我们将使用两种不同的方法或算法:连通分量和查找轮廓。
分割我们的输入图像
现在,我们将介绍两种分割阈值图像的技术:
- 连接的组件
- 查找等高线
使用这两种技术,我们可以提取图像中出现目标对象的每个感兴趣区域(ROI)。 在我们的例子中,这些是螺母、螺丝和环。
连通分量算法
连通分量算法是一种非常常用的算法,用于分割和识别二值图像中的部分。 连通分量是一种迭代算法,其目的是使用八个或四个连通性像素来标记图像。 如果两个像素具有相同的值并且是相邻像素,则这两个像素是相连的。 在图像中,每个像素都有八个相邻像素:
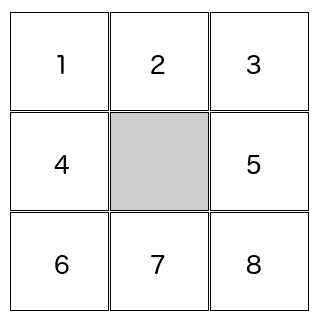
四连通性意味着,如果2、4、5和7邻居的值与中心像素相同,则它们只能连接到中心。 通过八个连接,如果1、2、3、4、5、6、7和8邻居的值与中心像素相同,则可以连接它们。 我们可以从四连通性算法和八连通性算法中看出以下示例的不同之处。 我们将把每种算法应用于下一幅二值化图像。 我们使用了一幅小的9x9图像,并放大显示了连接组件的工作原理以及四连接和八连接之间的区别:
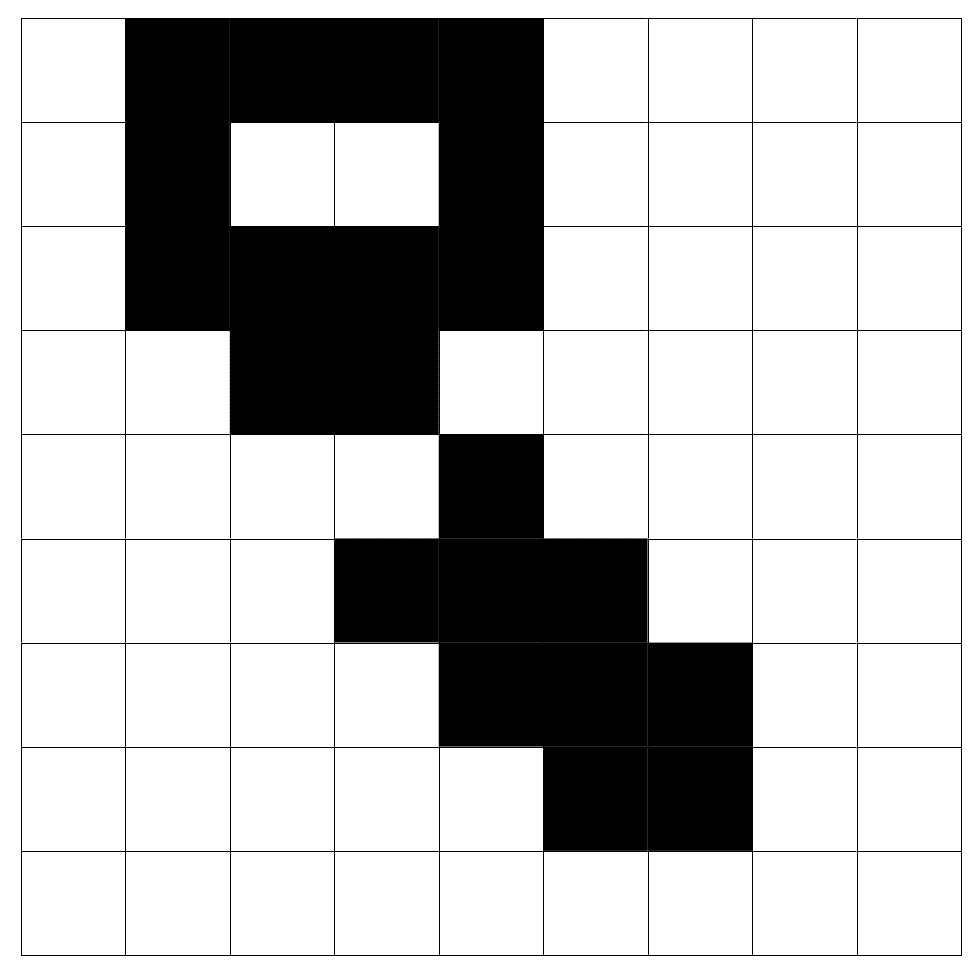
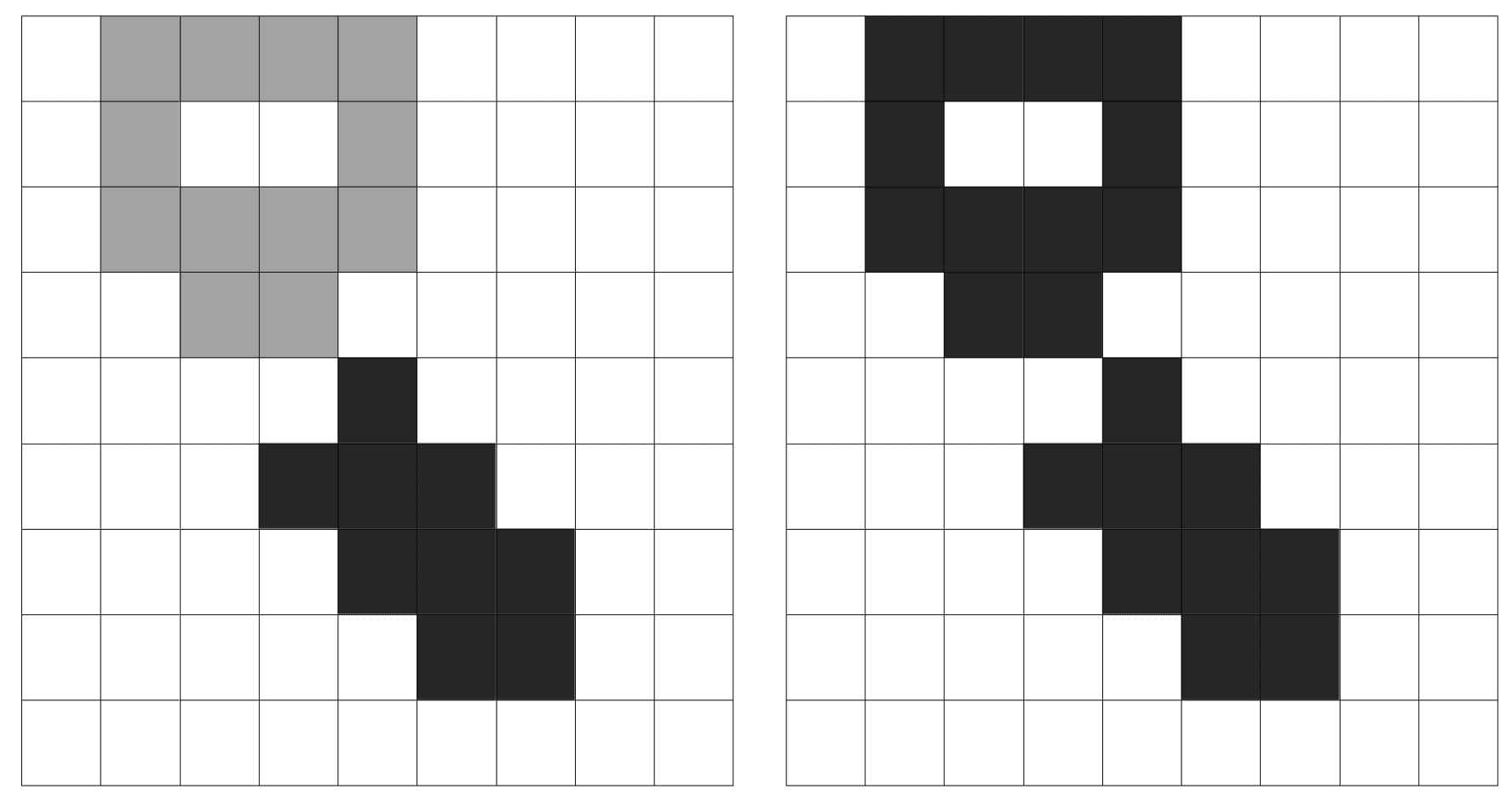
四连通性算法检测到两个对象;我们可以在左图中看到这一点。 八连通性算法只检测一个对象(右侧图像),因为两个对角线像素是相连的。 八连通性处理对角线连通性,这是与四连通性相比的主要区别,因为在四连通性中只考虑垂直和水平像素。 我们可以在下图中看到结果,其中每个对象都有不同的灰色值:
OpenCV 为我们带来了具有两种不同功能的连通分量算法:
connectedComponents(图像,标签,连接性=8,类型=CV_32S)connectedComponentsWithStats(图像,标签,统计信息,质心,连接性=8,类型=CV_32S)
这两个函数都返回一个带有检测到的标签数量的整数,其中 Label0表示背景。 这两个函数之间的区别基本上在于返回的信息。 让我们检查一下每一台的参数。 connectedComponents函数为我们提供以下参数:
- Image:要标记的输入图像。
- 标签:与输入图像大小相同的输出垫,其中每个像素都有其标签值,其中所有 OS 表示背景,值为
1的像素表示第一个连接的组件对象,依此类推。 - 连接性:表示我们要使用的连接性的两个可能值
8或4。 - 类型:我们要使用的标签图像的类型。 只允许两种类型:
CV32_S和CV16_U。 默认情况下,这是CV32_S。 connectedComponentsWithStats函数还定义了两个参数。 以下是统计数据和质心:- Stats:这是一个输出参数,为我们提供每个标签的以下统计值(包括背景):
CC_STAT_LEFT:连接组件对象最左侧的x坐标CC_STAT_TOP:连接的组件对象的最上面的y坐标CC_STAT_WIDTH:由其边界框定义的连接组件对象的宽度CC_STAT_HEIGHT:由其边界框定义的连接组件对象的高度CC_STAT_AREA:连接组件对象的像素数(面积)
- 质心:质心指向每个标签的浮动类型,包括考虑用于另一个连接组件的背景。
- Stats:这是一个输出参数,为我们提供每个标签的以下统计值(包括背景):
在我们的示例应用中,我们将创建两个函数,以便可以应用这两个 OpenCV 算法。 然后,我们将在具有基本连通分量算法的带有彩色对象的新图像中向用户显示所获得的结果。 如果我们使用 stats 方法选择连通组件,我们将在每个对象上绘制返回此函数的相应计算区域。
让我们定义连通组件函数的基本绘图:
void ConnectedComponents(Mat img)
{
// Use connected components to divide our image in multiple connected component objects
Mat labels;
auto num_objects= connectedComponents(img, labels);
// Check the number of objects detected
if(num_objects < 2 ){
cout << "No objects detected" << endl;
return;
}else{
cout << "Number of objects detected: " << num_objects - 1 << endl;
}
// Create output image coloring the objects
Mat output= Mat::zeros(img.rows,img.cols, CV_8UC3);
RNG rng(0xFFFFFFFF);
for(auto i=1; i<num_objects; i++){
Mat mask= labels==i;
output.setTo(randomColor(rng), mask);
}
imshow("Result", output);
}
首先,我们调用 OpenCVconnectedComponents函数,该函数返回检测到的对象数量。 如果对象的数量少于两个,这意味着只检测到背景对象,然后我们不需要绘制任何东西,就可以完成。 如果算法检测到多个对象,我们会显示控制台上检测到的对象数量:
Mat labels;
auto num_objects= connectedComponents(img, labels);
// Check the number of objects detected
if(num_objects < 2){
cout << "No objects detected" << endl;
return;
}else{
cout << "Number of objects detected: " << num_objects - 1 << endl;
现在,我们要用不同的颜色在新图像中绘制所有检测到的对象。 在此之后,我们需要创建一个具有相同输入大小和三个通道的新黑色图像:
Mat output= Mat::zeros(img.rows,img.cols, CV_8UC3);
我们将循环遍历除0值之外的每个标签,因为这是背景:
for(int i=1; i<num_objects; i++){
要从标签图像中提取每个对象,我们可以使用比较为每个i标签创建一个蒙版,并将其保存在新图像中:
Mat mask= labels==i;
最后,我们使用mask为输出图像设置伪随机颜色:
output.setTo(randomColor(rng), mask);
}
在循环所有图像之后,我们的输出中有所有检测到的不同颜色的对象,我们只需在窗口中显示输出图像:
imshow("Result", output);
这是使用不同颜色或灰度值绘制每个对象的结果:
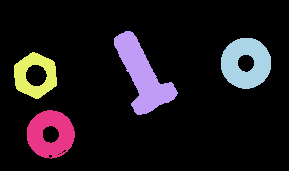
现在,我们将解释如何将连通分量与statsOpenCV 算法一起使用,并在生成的图像中显示更多信息。 以下函数实现此功能:
void ConnectedComponentsStats(Mat img)
{
// Use connected components with stats
Mat labels, stats, centroids;
auto num_objects= connectedComponentsWithStats(img, labels, stats, centroids);
// Check the number of objects detected
if(num_objects < 2 ){
cout << "No objects detected" << endl;
return;
}else{
cout << "Number of objects detected: " << num_objects - 1 << endl;
}
// Create output image coloring the objects and show area
Mat output= Mat::zeros(img.rows,img.cols, CV_8UC3);
RNG rng( 0xFFFFFFFF );
for(auto i=1; i<num_objects; i++){
cout << "Object "<< i << " with pos: " << centroids.at<Point2d>(i) << " with area " << stats.at<int>(i, CC_STAT_AREA) << endl;
Mat mask= labels==i;
output.setTo(randomColor(rng), mask);
// draw text with area
stringstream ss;
ss << "area: " << stats.at<int>(i, CC_STAT_AREA);
putText(output,
ss.str(),
centroids.at<Point2d>(i),
FONT_HERSHEY_SIMPLEX,
0.4,
Scalar(255,255,255));
}
imshow("Result", output);
}
让我们来理解一下这段代码。 正如我们在非统计函数中所做的那样,我们调用了 Connected Components 算法,但在这里,我们使用stats函数来执行此操作,以检查我们是否检测到多个对象:
Mat labels, stats, centroids;
auto num_objects= connectedComponentsWithStats(img, labels, stats, centroids);
// Check the number of objects detected
if(num_objects < 2){
cout << "No objects detected" << endl;
return;
}else{
cout << "Number of objects detected: " << num_objects - 1 << endl;
}
现在,我们又有了两个输出结果:统计数据和质心变量。 然后,对于每个检测到的标签,我们将通过命令行显示质心和区域:
for(auto i=1; i<num_objects; i++){
cout << "Object "<< i << " with pos: " << centroids.at<Point2d>(i) << " with area " << stats.at<int>(i, CC_STAT_AREA) << endl;
您可以检查对 stats 变量的调用,以使用列常量stats.at<int>(I, CC_STAT_AREA)提取区域。 现在,像以前一样,我们在输出图像上绘制标有i的对象:
Mat mask= labels==i;
output.setTo(randomColor(rng), mask);
最后,在每个分割对象的质心位置,我们希望在生成的图像上绘制一些信息(如面积)。 为此,我们使用putText函数的 STATS 和质心变量。 首先,我们必须创建一个stringstream,以便可以添加统计区域信息:
// draw text with area
stringstream ss;
ss << "area: " << stats.at<int>(i, CC_STAT_AREA);
然后,我们需要使用putText,使用质心作为文本位置:
putText(output,
ss.str(),
centroids.at<Point2d>(i),
FONT_HERSHEY_SIMPLEX,
0.4,
Scalar(255,255,255));
此函数的结果如下所示:
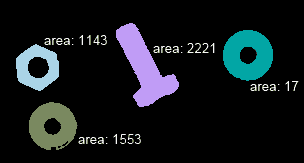
FindContours 算法
在分割对象时,findContours算法是最常用的 OpenCV 算法之一。 这是因为此算法是从 1.0 版开始包含在 OpenCV 中的,它为开发人员提供了更多信息和描述符,包括形状、拓扑组织等:
void findContours(InputOutputArray image, OutputArrayOfArrays contours, OutputArray hierarchy, int mode, int method, Point offset=Point())
下面我们来解释一下每个参数:
- 图像:输入二进制图像。
- 轮廓:轮廓的输出,其中每个检测到的轮廓都是点的矢量。
- 层次:这是保存等高线层次的可选输出向量。 这是图像的拓扑结构,在这里我们可以得到每个轮廓之间的关系。 层次表示为四个索引的向量,它们是(下一个轮廓、上一个轮廓、第一个子轮廓、父轮廓)。 在给定的等高线与其他等高线没有关系的情况下,给出负指数。 更详细的解释可以在https://docs.opencv.org/3.4/d9/d8b/tutorial_py_contours_hierarchy.html找到。
- 模式:此方法用于检索轮廓:
RETR_EXTERNAL仅检索外部轮廓。RETR_LIST检索所有等高线,而不建立层次。RETR_CCOMP检索具有两个层次(外部和孔)的所有等高线。 如果另一个对象在一个洞内,则将其放在层次的顶部。RETR_TREE检索所有等高线,在等高线之间创建完整层次。
- 方法:这允许我们使用近似方法检索轮廓的形状:
- 如果设置了
CV_CHAIN_APPROX_NONE,则不会对等高线应用任何近似,并存储等高线的点。 CV_CHAIN_APPROX_SIMPLE压缩所有水平、垂直和对角线段,仅存储起点和终点。CV_CHAIN_APPROX_TC89_L1和CV_CHAIN_APPROX_TC89_KCOS应用特尔钦链近似算法。
- 如果设置了
- 偏移:这是一个可选的点值,用于移动所有等高线。 当我们在 ROI 中工作并需要检索全球位置时,这是非常有用的。
Note: The input image is modified by the findContours function. Create a copy of your image before sending it to this function if you need it.
现在我们已经知道了findContours函数的参数,让我们将其应用到我们的示例中:
void FindContoursBasic(Mat img)
{
vector<vector<Point> > contours;
findContours(img, contours, RETR_EXTERNAL, CHAIN_APPROX_SIMPLE);
Mat output= Mat::zeros(img.rows,img.cols, CV_8UC3);
// Check the number of objects detected
if(contours.size() == 0 ){
cout << "No objects detected" << endl;
return;
}else{
cout << "Number of objects detected: " << contours.size() << endl;
}
RNG rng(0xFFFFFFFF);
for(auto i=0; i<contours.size(); i++){
drawContours(output, contours, i, randomColor(rng));
imshow("Result", output);
}
}
让我们逐行解释我们的实现。
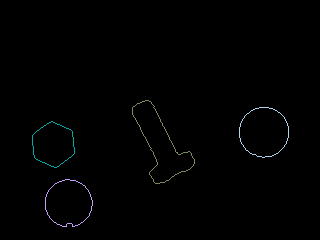
在我们的例子中,我们不需要任何层次结构,所以我们只需要检索所有可能对象的外部轮廓。 为此,我们可以使用RETR_EXTERNAL模式,并使用CHAIN_APPROX_SIMPLE方法进行基本轮廓编码:
vector<vector<Point> > contours;
vector<Vec4i> hierarchy;
findContours(img, contours, RETR_EXTERNAL, CHAIN_APPROX_SIMPLE);
就像我们之前看到的连通组件示例一样,我们首先检查我们检索到了多少轮廓。 如果没有,则退出我们的函数:
// Check the number of objects detected
if(contours.size() == 0){
cout << "No objects detected" << endl;
return;
}else{
cout << "Number of objects detected: " << contours.size() << endl;
}
最后,我们为每个检测到的物体画出轮廓线。 我们用不同的颜色将其绘制在输出图像中。 为此,OpenCV 提供了一个函数来绘制查找等高线图像的结果:
for(auto i=0; i<contours.size(); i++)
drawContours(output, contours, i, randomColor(rng));
imshow("Result", output);
}
drawContours函数允许以下参数:
- Image:绘制轮廓的输出图像。
- 轮廓:轮廓的向量。
- 等高线索引:指示要绘制的等高线的数字。 如果该值为负,则绘制所有等高线。
- 颜色:绘制轮廓的颜色。
- 厚度:如果为负值,则用所选颜色填充轮廓。
- Line type:这指定我们是要使用抗锯齿绘制,还是要使用其他绘制方法。
- Hierarchy:这是一个可选参数,只有在要绘制一些等高线时才需要。
- 最大级别:这是一个可选参数,只有当 Hierarchy 参数可用时才会考虑该参数。 如果设置为
0,则只绘制指定的等高线。 如果为1,该函数还会绘制当前等高线和嵌套的等高线。 如果将其设置为2,则算法将绘制所有指定的等高线层次。 - 偏移量:这是用于移动等高线的可选参数。
我们的示例结果如下图所示:
简略的 / 概括的 / 简易判罪的 / 简易的
在本章中,我们探讨了在摄像机拍摄不同对象的受控情况下对象分割的基础知识。 在这里,我们学习了如何去除背景和光线,以便更好地对图像进行二值化,从而将噪声降至最低。 在对图像进行二值化之后,我们了解了三种不同的算法,这些算法可用于分割和分离图像中的每个对象,从而使我们能够隔离每个对象以操作或提取特征。
我们可以在下图中看到整个过程:

最后,我们提取了一幅图像上的所有对象。 您需要这样做才能继续下一章,在下一章中,我们将提取每个对象的特征来训练机器学习系统。
在下一章中,我们将预测图像中任何物体的类别,然后呼叫机器人或任何其他系统来挑选它们中的任何一个,或者检测不在正确载体带上的物体。 然后,我们将研究如何通知一个人来取它。**
