十一、使用 Tesseract 的文本识别
在第 10 章,开发用于文本识别的分割算法中,我们介绍了非常基本的 OCR 处理函数。 虽然它们对于扫描或拍照的文档非常有用,但在处理随意出现在图片中的文本时几乎毫无用处。
在本章中,我们将探索 OpenCV 4.0 文本模块,该模块专门处理场景文本检测。 使用此接口,可以检测网络摄像头视频中出现的文本,或者分析拍摄的图像(如街景或监控摄像头拍摄的图像),以实时提取文本信息。 这允许创建范围广泛的应用,从可访问性到营销,甚至是机器人领域。
在本章结束时,您将能够执行以下操作:
- 了解什么是场景文本识别
- 了解 Text API 的工作原理
- 使用 OpenCV 4.0 Text API 检测文本
- 将检测到的文本提取到图像中
- 使用 Text API 和 Tesseract 集成来识别字母
技术要求
本章要求熟悉基本的 C++ 编程语言。 本章使用的所有代码都可以从以下 giHub 链接下载:https://github.com/PacktPublishing/Building-Computer-Vision-Projects-with-OpenCV4-and-CPlusPlus/tree/master/Chapter11。 该代码可以在任何操作系统上执行,尽管它只在 Ubuntu 上进行了测试。
请查看以下视频,了解实际操作中的代码: http://bit.ly/2Slht5A
Text API 的工作原理
Text API 实现了Lukás Neumann和Jiri Matas在 2012 年计算机视觉和模式识别(CVPR)会议期间在文章Real-Time Scene Text Location and Recognition中提出的算法。 该算法代表了场景文本检测的显著提高,在 CVPR 数据库和 Google Street View 数据库中都执行了最先进的检测。 在使用 API 之前,让我们先来看看这个算法是如何在幕后工作的,以及它是如何解决场景文本检测问题的。
Remember: The OpenCV 4.0 text API does not come with the standard OpenCV modules. It's an additional module that's present in the OpenCV contrib package. If you installed OpenCV using the Windows Installer, you should take a look back at Chapter 1, Getting Started with OpenCV; this will guide you on how to install these modules.
场景检测问题
检测场景中随机出现的文本是一个比看起来更难的问题。 在与识别的扫描文本进行比较时,需要考虑以下几个新变量:
- 三维性:文本可以是任何比例、方向或视角。 此外,文本可能被部分遮挡或中断。 从字面上看,它可能出现在图像中的区域有数千个。
- Varity:文本可以有几种不同的字体和颜色。 字体可能有轮廓边框。 背景可以是深色、浅色或复杂的图像。
- 照明和阴影:太阳光的位置和外观颜色随时间变化。 雾或雨等不同的天气条件会产生噪音。 即使在封闭的空间里,照明也可能是个问题,因为光线会反射到彩色物体上,并照射到文本上。
- 模糊:文本可能出现在未通过镜头自动对焦确定优先级的区域。 模糊在移动相机、透视文本或有雾的情况下也很常见。
下面的图片来自谷歌街景,说明了这些问题。 请注意,其中几种情况是如何在一张图像中同时发生的:

由于存在2n个像素子集,n是图像中的像素数,因此执行文本检测来处理此类情况可能会证明计算代价很高。
为了降低复杂性,通常使用两种策略:
- 使用滑动窗口仅搜索图像矩形的子集:此策略只是将子集的数量减少到较小的数量。 根据所考虑的文本的复杂程度,区域的数量会有所不同。 与还处理旋转、倾斜、透视等的算法相比,仅处理文本旋转的算法可能使用较小的值。 这种方法的优点在于它的简单性,但它们通常仅限于很小范围的字体,而且通常限于特定单词的词典。
- 连通分量分析的使用:此方法假设像素可以分组为具有相似属性的区域。 这些地区被认为有更高的机会被识别为人物。 这种方法的优点是它不依赖于几个文本属性(方向、比例、字体等),而且它们还提供了可用于将文本裁剪到 OCR 的分割区域。 这是我们在第 10 章,开发用于文本识别的分割算法中使用的方法。 照明也可能影响结果,例如,如果阴影投射在字母上,会产生两个截然不同的区域。 但是,由于场景检测通常用于移动车辆(例如,无人机或汽车)和视频,因此文本最终将被检测到,因为这些照明条件会因帧而异。
OpenCV 4.0 算法通过执行连通分量分析和搜索极值区域来使用第二种策略。
极值区域
极值区域是以几乎均匀的强度为特征的连通区域,周围环绕着对比鲜明的背景。 一个区域的稳定性可以通过计算该区域对阈值变化的抵抗力来衡量。 这种差异可以用一种简单的算法来测量:
- 应用阈值,生成图像A。 检测其连接的像素区域(极值区域)。
- 将阈值增加一个增量,生成图像B。 检测其连接的像素区域(极值区域)。
- 将图像B与A进行比较。 如果图像 A 中的某个区域与图像B中的相同区域相似,则将其添加到树中的同一分支。 相似性的标准可能因实现而异,但通常与图像区域或一般形状有关。 如果图像A中的区域似乎在图像B中被拆分,则在树中为新区域创建两个新分支,并将其与前一个分支相关联。
- 设置A=B并返回步骤 2,直到应用最大阈值。
这将组装一个区域树,如下所示:

对方差的抵抗力是通过计算同一级别中有多少个节点来确定的。 通过分析这棵树,还可以确定个最稳定的极值区域(MSERs),即该区域在各种阈值下保持稳定的区域。 在上图中,很明显这些区域将包含字母O、N和Y。 最大极值区域的主要缺点是它们在存在模糊的情况下很弱。 OpenCV 在Feature 2d模块中提供了一个 MSER 特性检测器。 极值区域很有趣,因为它们对光照、比例和方向都有很强的不变性。 它们也是很好的文本候选者,因为它们在使用的字体类型方面也是不变的,即使在设置了字体样式的情况下也是如此。 还可以分析每个区域以确定其边界省略,并且可以具有仿射变换和数值确定的面积等属性。 最后,值得一提的是,整个过程速度很快,这使得它成为实时应用的一个非常好的候选者。
极值区域滤波
虽然 MSER 是定义哪些极端区域值得使用的常用方法,但Neumann和Matas算法使用不同的方法,将所有极端区域提交给经过字符检测训练的顺序分类器。 此分类器在两个不同的阶段工作:
- 第一阶段递增地计算每个区域的描述符(边界框、周长、面积和欧拉数)。 这些描述符被提交给分类器,该分类器估计该区域成为字母表中的字符的可能性有多大。 然后,仅为阶段 2 选择高概率区域。
- 在这一阶段中,计算了整体面积比、凸壳比、外边界拐点个数等特征。 这提供了更详细的信息,允许分类器丢弃非文本字符,但它们的计算速度也要慢得多。
在 OpenCV 下,此过程在名为ERFilter的类中实现。 还可以使用不同的图像单通道投影,例如R、G、B、亮度或灰度转换来提高字符识别率。 最后,必须将所有字符分组为文本块(例如单词或段落)。 OpenCV 3.0 为此提供了两种算法:
- 修剪穷举搜索:同样是由Mattas在 2011 年提出的,该算法不需要任何先前的训练或分类,但仅限于水平对齐的文本
- 定向文本的分层方法:它处理任意方向的文本,但需要经过训练的分类器
Note that since these operations require classifiers, it is also necessary to provide a trained set as input. OpenCV 4.0 provides some of these trained sets in the following sample package: https://github.com/opencv/opencv_contrib/tree/master/modules/text/samples. This also means that this algorithm is sensitive to the fonts used in classifier training.
在下面的视频中可以看到该算法的演示,该视频由诺伊曼本人提供:https://www.youtube.com/watch?v=ejd5gGea2Fo&Feature=youtu.be。 一旦文本被分割,它只需要被发送到像 Tesseract 这样的 OCR,类似于我们在第 10 章,开发用于文本识别的分割算法中所做的工作。 唯一的区别是,现在我们将使用 OpenCV 文本模块类与 Tesseract 交互,因为它们提供了一种封装我们正在使用的特定 OCR 引擎的方法。
使用 Text API
理论说得够多了。 现在我们来看看文本模块在实践中是如何工作的。 让我们研究一下如何使用它来执行文本检测、提取和识别。
文本检测
让我们从创建一个简单的程序开始,这样我们就可以使用ERFilters执行文本分割。 在本程序中,我们将使用文本 API 样本中训练好的分类器。 您可以从 OpenCV 资源库下载,但也可以在本书的配套代码中找到。
首先,我们首先包括所有必要的libs和usings:
#include "opencv2/highgui.hpp"
#include "opencv2/imgproc.hpp"
#include "opencv2/text.hpp"
#include <vector>
#include <iostream>
using namespace std;
using namespace cv;
using namespace cv::text;
回想一下极值区域过滤部分,ERFilter在每个图像通道中单独工作。 因此,我们必须提供一种在不同的单个通道cv::Mat中分离每个所需通道的方法。 这由separateChannels函数完成:
vector<Mat> separateChannels(const Mat& src)
{
vector<Mat> channels;
//Grayscale images
if (src.type() == CV_8U || src.type() == CV_8UC1) {
channels.push_back(src);
channels.push_back(255-src);
return channels;
}
//Colored images
if (src.type() == CV_8UC3) {
computeNMChannels(src, channels);
int size = static_cast<int>(channels.size())-1;
for (int c = 0; c < size; c++)
channels.push_back(255-channels[c]);
return channels;
}
//Other types
cout << "Invalid image format!" << endl;
exit(-1);
}
首先,我们验证图像是否已经是单通道图像(灰度图像)。 如果是这样,我们只需添加此图像-它不需要处理。 否则,我们检查它是否是RGB图像。 对于彩色图像,我们调用computeNMChannels函数将图像分割成几个通道。 该函数定义如下:
void computeNMChannels(InputArray src, OutputArrayOfArrays channels, int mode = ERFILTER_NM_RGBLGrad);
以下是其参数:
src:源输入数组。 它必须是 8UC3 型彩色图像。channels:将用结果通道填充的Mats的向量。mode:定义将计算哪些通道。 可以使用两个可能的值:ERFILTER_NM_RGBLGrad:指示算法是否使用 RGB 颜色、亮度和渐变幅值作为通道(默认)ERFILTER_NM_IHSGrad:指示是否按图像的强度、色调、饱和度和渐变大小分割图像
我们还附加了向量中所有颜色分量的负片。 由于图像将有三个不同的通道(R、G和B),这通常就足够了。 也可以添加未翻转的通道,就像我们对去灰度化图像所做的那样,但我们最终会得到 6 个通道,这可能会占用大量的计算机资源。 当然,如果这会带来更好的结果,您可以自由地使用您的图像进行测试。 最后,如果提供了另一种图像,该函数将终止程序并显示错误消息。
Negatives are appended, so the algorithms will cover both bright text in a dark background and dark text in a bright background. There is no sense in adding a negative for the gradient magnitude.
让我们继续主要方法。 我们将使用此程序对easel.png图像进行分割,该图像随源代码提供:

这张照片是我走在街上时用手机相机拍的。 让我们对此进行编码,以便您也可以通过在第一个程序参数中提供其名称来轻松地使用不同的图像:
int main(int argc, const char * argv[])
{
const char* image = argc < 2 ? "easel.png" : argv[1];
auto input = imread(image);
接下来,我们将通过调用separateChannels函数将图像转换为灰度并分隔其通道:
Mat processed;
cvtColor(input, processed, COLOR_RGB2GRAY);
auto channels = separateChannels(processed);
如果要使用彩色图像中的所有通道,只需将此代码摘录的前两行替换为以下内容:
Mat processed = input;
我们需要分析六个通道(RGB 和反转),而不是两个(灰色和反转)。 事实上,处理时间所增加的,远较我们所能得到的改善为多。 有了通道后,我们需要为算法的两个阶段创建ERFilters。 幸运的是,OpenCV 文本贡献模块提供了这样的功能:
// Create ERFilter objects with the 1st and 2nd stage classifiers
auto filter1 = createERFilterNM1(
loadClassifierNM1("trained_classifierNM1.xml"), 15, 0.00015f,
0.13f, 0.2f,true,0.1f);
auto filter2 = createERFilterNM2(
loadClassifierNM2("trained_classifierNM2.xml"),0.5);
对于第一阶段,我们调用loadClassifierNM1函数来加载先前训练的分类模型。 包含训练数据的.xml 是其唯一参数。 然后,我们调用createERFilterNM1来创建将执行分类的ERFilter类的实例。 该函数具有以下签名:
Ptr<ERFilter> createERFilterNM1(const Ptr<ERFilter::Callback>& cb, int thresholdDelta = 1, float minArea = 0.00025, float maxArea = 0.13, float minProbability = 0.4, bool nonMaxSuppression = true, float minProbabilityDiff = 0.1);
此函数的参数如下:
cb:分类模型。 这与我们使用loadCassifierNM1函数加载的模型相同。thresholdDelta:每次算法迭代中要加到阈值的量。 默认值为1,但我们在示例中将使用15。minArea:可以找到文本的极值区域(ER)的最小区域。 这是通过图像大小的百分比来衡量的。 面积小于此值的 ERR 会立即被丢弃。maxArea:ER 中可以找到文本的最大区域。 这也是通过图像大小的百分比来衡量的。 面积大于这一范围的 ER 会立即被丢弃。minProbability:区域必须是字符才能进入下一阶段的最小概率。nonMaxSupression:用于指示是否在每个分支概率中执行非最大抑制。minProbabilityDiff:最小和最大极值区域之间的最小概率差。
第二阶段的过程与此类似。 我们调用loadClassifierNM2来加载第二阶段的分类器模型,调用createERFilterNM2来创建第二阶段分类器。 该函数只接受加载的分类模型的输入参数和区域被视为字符所必须达到的最小概率。 因此,让我们在每个通道中调用这些算法来识别所有可能的文本区域:
//Extract text regions using Newmann & Matas algorithm
cout << "Processing " << channels.size() << " channels...";
cout << endl;
vector<vector<ERStat> > regions(channels.size());
for (int c=0; c < channels.size(); c++)
{
cout << " Channel " << (c+1) << endl;
filter1->run(channels[c], regions[c]);
filter2->run(channels[c], regions[c]);
}
filter1.release();
filter2.release();
在前面的代码中,我们使用了ERFilter类的run函数。 此函数接受两个参数:
- 输入通道:包括要处理的图像。
- 区域:在第一阶段算法中,此参数将填充检测到的区域。 在第二阶段(由
filter2执行),此参数必须包含在阶段 1 中选择的区域。这些区域将由阶段 2 处理和过滤。
最后,我们释放这两个过滤器,因为程序中将不再需要它们。 最后的分割步骤是将所有 ERRegion 分组为可能的单词,并定义它们的边界框。 这可以通过调用erGrouping函数来完成:
//Separate character groups from regions
vector< vector<Vec2i> > groups;
vector<Rect> groupRects;
erGrouping(input, channels, regions, groups, groupRects, ERGROUPING_ORIENTATION_HORIZ);
此函数具有以下签名:
void erGrouping(InputArray img, InputArrayOfArrays channels, std::vector<std::vector<ERStat> > ®ions, std::vector<std::vector<Vec2i> > &groups, std::vector<Rect> &groups_rects, int method = ERGROUPING_ORIENTATION_HORIZ, const std::string& filename = std::string(), float minProbablity = 0.5);
让我们来看看每个参数的含义:
img:输入图像,也称为原始图像。regions:提取区域的单通道图像的矢量。groups:分组区域的索引的输出向量。 每组区域包含单个单词的所有极值区域。groupRects:带有检测到的文本区域的矩形列表。method:这是分组的方法。 它可以是以下任一项:ERGROUPING_ORIENTATION_HORIZ:默认值。 这只会按照Neumann和Matas最初提出的方法,通过进行详尽的搜索来生成具有水平方向的文本组。ERGROUPING_ORIENTATION_ANY:这将使用单一链接聚类和分类器生成具有任意方向的文本的组。 如果使用此方法,则必须在下一个参数中提供分类器模型的文件名。Filename:分类器模型的名称。 仅当选择了ERGROUPING_ORIENTATION_ANY时才需要此选项。minProbability:检测到的接受组的最小概率。 仅当选择了ERGROUPING_ORIENTATION_ANY时才需要此选项。
代码还提供了对第二个方法的调用,但它被注释掉了。 您可以在两者之间切换以测试这一点。 只需注释上一个调用,并取消对此调用的注释:
erGrouping(input, channels, regions,
groups, groupRects, ERGROUPING_ORIENTATION_ANY,
"trained_classifier_erGrouping.xml", 0.5);
对于此调用,我们还使用了文本模块示例包中提供的默认训练分类器。 最后,我们绘制区域框并显示结果:
// draw groups boxes
for (const auto& rect : groupRects)
rectangle(input, rect, Scalar(0, 255, 0), 3);
imshow("grouping",input);
waitKey(0);
此程序输出以下结果:

您可以查看detection.cpp文件中的整个源代码。
While most OpenCV text module functions are written to support both grayscale and colored images as its input parameter, at the time of writing this book, there were bugs preventing us from using grayscale images in functions such as erGrouping. For more information, take a look at the following GitHub link: https://github.com/Itseez/opencv_contrib/issues/309. Always remember that the OpenCV contrib modules package is not as stable as the default OpenCV packages.
文本提取
既然我们已经检测到区域,我们必须在将文本提交给 OCR 之前对其进行裁剪。 我们可以简单地使用像getRectSubpix或Mat::copy这样的函数,将每个区域矩形用作感兴趣的区域(ROI),但是,由于字母倾斜,一些不需要的文本也可能被裁剪。 例如,如果我们仅根据给定的矩形提取 ROI,则其中一个区域的外观如下所示:

幸运的是,ERFilter为我们提供了一个名为ERStat的对象,它包含每个极端区域内的像素。 有了这些像素,我们就可以使用 OpenCV 的floodFill函数来重建每个字母。 此函数能够基于种子点绘制相似颜色的像素,就像大多数绘图应用的bucket工具一样。 函数签名如下所示:
int floodFill(InputOutputArray image, InputOutputArray mask, Point seedPoint, Scalar newVal,
CV_OUT Rect* rect=0, Scalar loDiff = Scalar(), Scalar upDiff = Scalar(), int flags = 4 );
让我们了解一下这些参数以及它们的使用方法:
image:输入图像。 我们将使用拍摄极端区域的通道图像。 除非提供了FLOODFILL_MASK_ONLY,否则这是该函数通常执行泛洪填充的位置。 在这种情况下,图像保持不变,绘制发生在蒙版中。 这正是我们要做的。mask:蒙版必须是比输入图像大两行两列的图像。 当整体填充绘制像素时,它会验证蒙版中相应的像素是否为零。 在这种情况下,它将绘制该像素并将其标记为 1(或传递到标志中的另一个值)。 如果像素不为零,则整体应用填充不会绘制像素。 在我们的例子中,我们将提供一个空白蒙版,这样每个字母都会被绘制到蒙版中。seedPoint:起点。 它类似于您想要使用图形应用的Bucket工具时单击的位置。newVal:重新绘制的像素的新值。loDiff和upDiff:这些参数表示正在处理的像素与其相邻像素之间的上下差异。 如果邻居落在这个范围内,它就会被画出来。 如果使用FLOODFILL_FIXED_RANGE标志,则将使用种子点和正在处理的像素之间的差值。rect:这是一个可选参数,用于限制将应用泛洪填充的区域。flags:该值由位掩码表示:- 标志的最低有效 8 位包含连接值。 值
4表示将使用所有四个边缘像素,值8表示还必须考虑对角线像素。 我们将使用4作为此参数。 - 接下来的 8 到 16 位包含一个从
1到255的值,用于填充掩码。 因为我们想用白色填充蒙版,所以我们将使用255 << 8作为此值。 - 正如我们已经描述的,可以通过添加
FLOODFILL_FIXED_RANGE和FLOODFILL_MASK_ONLY标志来设置另外两位。
- 标志的最低有效 8 位包含连接值。 值
我们将创建一个名为drawER的函数。 此函数将接收四个参数:
- 具有所有已处理通道的矢量
ERStat区域- 必须抽签的组
- 组矩形
此函数将返回包含由该组表示的单词的图像。 让我们通过创建遮罩图像并定义标志来开始此函数:
Mat out = Mat::zeros(channels[0].rows+2, channels[0].cols+2, CV_8UC1);
int flags = 4 //4 neighbors
+ (255 << 8) //paint mask in white (255)
+ FLOODFILL_FIXED_RANGE //fixed range
+ FLOODFILL_MASK_ONLY; //Paint just the mask
然后,我们将遍历每组。 有必要找出地区指数及其地位。 这个极端的区域有可能是根,它不包含任何点。 在本例中,我们将忽略它:
for (int g=0; g < group.size(); g++)
{
int idx = group[g][0];
auto er = regions[idx][group[g][1]];
//Ignore root region
if (er.parent == NULL)
continue;
现在,我们可以从ERStat对象读取像素坐标。 它由像素数表示,从上到下,从左到右计数。 此线性索引必须转换为行(y)和列(z)表示法,使用与我们在第 2 章,OpenCV基础简介中看到的公式类似的公式:
int px = er.pixel % channels[idx].cols;
int py = er.pixel / channels[idx].cols;
Point p(px, py);
然后,我们可以调用floodFill函数。 ERStat对象为我们提供了要在loDiff参数中使用的值:
floodFill(
channels[idx], out, //Image and mask
p, Scalar(255), //Seed and color
nullptr, //No rect
Scalar(er.level),Scalar(0), //LoDiff and upDiff
flags //Flags
在对组中的所有区域执行此操作后,我们将以一个比原始图像稍大的图像结束,该图像的背景为黑色,单词为白色字母。 现在,让我们只裁剪字母的区域。 由于给出了区域矩形,我们首先将其定义为感兴趣的区域:
out = out(rect);
然后,我们将找到所有非零像素。 这是我们将在minAreaRect函数中使用的值,以获得围绕字母旋转的矩形。 最后,我们将借用上一章的deskewAndCrop函数为我们裁剪和旋转图像:
vector<Point> points;
findNonZero(out, points);
//Use deskew and crop to crop it perfectly
return deskewAndCrop(out, minAreaRect(points));
}
这是画架图像处理的结果:

文本识别
在第 10 章,开发用于文本识别的分割算法中,我们直接使用了 Tesseract API 来识别文本区域。 这一次,我们将使用 OpenCV 类来实现相同的目标。
在 OpenCV 中,所有特定于 OCR 的类都派生自BaseOCR虚拟类。 此类为 OCR 执行方法本身提供公共接口。 特定的实现必须从该类继承。 默认情况下,文本模块提供三种不同的实现:OCRTesseract、OCRHMMDecoder和OCRBeamSearchDecoder。
下面的类图描述了此层次结构:
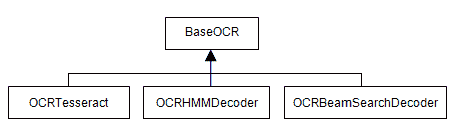
使用这种方法,我们可以将创建 OCR 机制的代码部分与执行本身分开。 这使得将来更容易更改 OCR 实现。
因此,让我们从创建一个方法开始,该方法决定我们将基于字符串使用哪个实现。 我们目前只支持 Tesseract,但您可以查看本章的代码,其中还提供了HMMDecoder的演示。 此外,我们接受字符串参数中的 OCR 引擎名称,但我们可以通过从外部 JSON 或 XML 配置文件中读取它来提高应用的灵活性:
cv::Ptr<BaseOCR> initOCR2(const string& ocr) { if (ocr == "tesseract") { return OCRTesseract::create(nullptr, "eng+por"); } throw string("Invalid OCR engine: ") + ocr; }
您可能已经注意到,该函数返回Ptr<BaseOCR>。 现在,看一下突出显示的代码。 它调用create方法来初始化 Tesseract OCR 实例。 我们来看看它的官方签名,因为它允许几个具体的参数:
Ptr<OCRTesseract> create(const char* datapath=NULL,
const char* language=NULL,
const char* char_whitelist=NULL,
int oem=3, int psmode=3);
让我们分析一下这些参数中的每一个:
datapath:这是根目录的tessdata文件的路径。 路径必须以反斜杠/字符结束。tessdata目录包含您安装的语言文件。 将nullptr传递给此参数将使 Tesseract 在其安装目录中进行搜索,该目录通常是该文件夹所在的位置。 在部署应用时,通常会将此值更改为args[0],并在应用路径中包含tessdata文件夹。language:这是一个带有语言代码的三个字母的单词(例如,Eng 代表英语,POR 代表葡萄牙语,Hin 代表印地语)。 Tesseract 支持使用+符号加载多语言代码。 因此,通过eng+por将加载英语和葡萄牙语。 当然,您只能使用以前安装的语言,否则加载将失败。 Languageconfig文件可以指定必须一起加载两种或两种以上语言。 为了防止出现这种情况,您可以使用波浪号~。 例如,您可以使用hin+~eng来保证英语不会加载印地语,即使它被配置为这样做。whitelist:这是设置为识别的字符。 在传递nullptr的情况下,字符将为0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ。oem:这些是将使用的 OCR 算法。 它可以具有下列值之一:OEM_TESSERACT_ONLY:仅使用 Tesseract。 这是最快的方法,但精度也较低。OEM_CUBE_ONLY:使用多维数据集引擎。 它更慢,但更精确。 只有当您的语言经过培训以支持此引擎模式时,这才会起作用。 要检查是否如此,请在tessdata文件夹中查找您的语言的.cube文件。 对英语的支持是有保证的。OEM_TESSERACT_CUBE_COMBINED:组合 Tesseract 和 Cube 以实现最佳的 OCR 分类。 该引擎具有最好的精确度和最慢的执行时间。OEM_DEFAULT:根据语言配置文件或命令行配置文件推断策略,如果两者都不存在,则使用OEM_TESSERACT_ONLY。
psmode:这是分段模式。 它可以是以下任一项:PSM_OSD_ONLY:使用此模式,Tesseract 将只运行其预处理算法来检测方向和脚本检测。PSM_AUTO_OSD:这告诉 Tesseract 使用方向和脚本检测进行自动页面分割。PSM_AUTO_ONLY:执行页面分割,但避免执行定向、脚本检测或 OCR。 这是默认值。PSM_AUTO:执行页面分割和 OCR,但避免执行方向或脚本检测。PSM_SINGLE_COLUMN:假设可变大小的文本显示在单个列中。PSM_SINGLE_BLOCK_VERT_TEXT:将图像视为垂直对齐的单个统一文本块。PSM_SINGLE_BLOCK:假定为单个文本块。 这是默认配置。 我们将使用这个标志,因为我们的预处理阶段保证了这个条件。PSM_SINGLE_LINE:表示图像仅包含一行文本。PSM_SINGLE_WORD:表示图像只包含一个单词。PSM_SINGLE_WORD_CIRCLE:表示图像只是一个排列在圆圈中的单词。PSM_SINGLE_CHAR:表示图像包含单个字符。
对于最后两个参数,建议您使用#includeTesseract 目录来使用常量名称,而不是直接插入它们的值。 最后一步是在我们的主函数中添加文本检测。 为此,只需将以下代码添加到 Main 方法的末尾:
auto ocr = initOCR("tesseract");
for (int i = 0; i < groups.size(); i++)
{
auto wordImage = drawER(channels, regions, groups[i],
groupRects[i]);
string word;
ocr->run(wordImage, word);
cout << word << endl;
}
在这段代码中,我们首先调用initOCR方法创建一个 Tesseract 实例。 请注意,如果我们选择不同的 OCR 引擎,剩余的代码将不会更改,因为 Run 方法签名由BaseOCR类保证。 接下来,我们迭代每个检测到的ERFilter组。 由于每组代表一个不同的单词,我们将执行以下操作:
- 调用前面创建的
drawER函数来创建包含该单词的图像。 - 创建一个名为
word的文本字符串,并调用run函数来识别单词 image。 识别的单词将存储在字符串中。 - 在屏幕上打印文本字符串。
让我们来看看run方法签名。 此方法在BaseOCR类中定义,对于所有特定的 OCR 实现都是相同的-即使是将来可能实现的实现:
virtual void run(Mat& image, std::string& output_text,
std::vector<Rect>* component_rects=NULL,
std::vector<std::string>* component_texts=NULL,
std::vector<float>* component_confidences=NULL, int component_level=0) = 0;
当然,这是一个纯虚函数,必须由每个特定类实现(比如我们刚才使用的OCRTesseract类):
image:输入图像。 它必须是 RGB 或灰度图像。component_rects:我们可以提供一个向量,用 OCR 引擎检测到的每个组件(单词或文本行)的边界框填充。component_texts:如果给定,此向量将填充 OCR 检测到的每个组件的文本字符串。component_confidences:如果给定,向量将用浮点数填充,每个分量的置信度值。component_level:定义什么是组件。 它可以具有值OCR_LEVEL_WORD(默认情况下)或OCR_LEVEL_TEXT_LINE。
If necessary, you may prefer changing the component level to a word or line in the run() method instead of doing the same thing in the psmode parameter of the create() function. This is preferable since the run method will be supported by any OCR engine that decides to implement the BaseOCR class. Always remember that the create() method is where vendor-specific configurations are set.
以下是程序的最终输出:
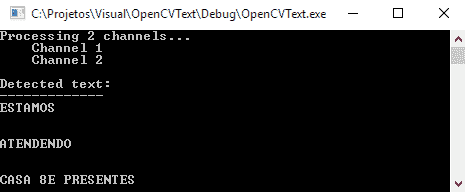
尽管与&符号有一点混淆,但每个单词都被完全识别。 您可以在本章的代码文件中查看ocr.cpp文件中的整个源代码。
简略的 / 概括的 / 简易判罪的 / 简易的
在本章中,我们看到场景文本识别比处理扫描文本要困难得多。 我们研究了文本模块如何使用Newmann和Matas算法进行极值区域识别。 我们还了解了如何通过floodFill函数使用此 API 将文本提取到图像中,并将其提交给 Tesseract OCR。 最后,我们学习了 OpenCV 文本模块如何与 Tesseract 和其他 OCR 引擎集成,以及如何使用它的类来识别图像中所写的内容。
在下一章中,我们将向您介绍 OpenCV 中的深度学习。 您将通过使用只看一次(YOLO)算法了解对象检测和分类。
