十七、基于 DNN 模块的人脸检测与识别
在本章中,我们将学习人脸检测和识别的主要技术。 人脸检测是在整个图像中定位人脸的过程。 在本章中,我们将介绍不同的人脸检测技术,从使用具有 Haar 特征的级联分类器的经典算法到使用深度学习的新技术。 人脸识别是识别出现在图像中的人的过程。在本章中,我们将讨论以下主题:
- 基于不同方法的人脸检测
- 人脸预处理
- 从收集到的人脸训练机器学习算法
- 人脸识别
- 最后的润色
人脸检测与人脸识别简介
人脸识别是给已知人脸贴上标签的过程。 就像人类只通过看到他们的脸就能识别他们的家人、朋友和名人一样,在计算机视觉中有很多识别人脸的技术。
这些步骤通常涉及四个主要步骤,定义如下:
- 人脸检测:这是在图像中定位人脸区域(以下截图中心附近的大矩形)的基本过程。 这一步并不关心这个人是谁,只关心它是一张人脸。
- 人脸预处理:这是调整人脸图像,使其看起来更清晰、更接近其他人脸(以下截图中央上方的小灰度人脸)的最新流程。
- 收集和学习人脸:这是一个保存许多预处理过的人脸(对于每个应该识别的人),然后学习如何识别它们的过程。
- 人脸识别:这是检查采集到的哪些人与摄像头中的人脸最相似的最新流程(下面截图右上角的一个小矩形)。
Note that the phrase face recognition is often used by the general public to refer to finding the positions of faces (that is, face detection, as described in step 1), but this book will use the formal definition of face recognition referring to step 4, and face detection referring to Step 1.
下面的屏幕截图显示了最终的WebcamFaceRec人项目,包括右上角的一个小矩形,突出显示了被识别的人。 此外,请注意预处理后的人脸(标记该人脸的矩形顶部中心的小人脸)旁边的置信条,在本例中,它显示出大约 70%的置信度,表明它已经识别出正确的人:

当前的人脸检测技术在现实世界中是相当可靠的,而当前的人脸识别技术在现实世界中使用时可靠性要低得多。 例如,很容易找到显示人脸识别准确率超过 95%的研究论文,但当你自己测试同样的算法时,你可能经常会发现准确率低于 50%。 这是因为目前的人脸识别技术对图像中的精确条件非常敏感,例如照明类型、光照和阴影方向、人脸的准确方向、人脸的表情以及人的当前情绪,这是因为人脸识别技术对图像中的确切条件非常敏感,例如光照类型、光照和阴影的方向、人脸的确切方向、人脸的表情以及人的当前情绪。 如果在训练(采集图像)和测试(从摄像头图像)时都保持不变,那么人脸识别应该会工作得很好,但如果训练时人站在房间灯光的左侧,然后在用摄像头测试时站在右边,可能会产生相当糟糕的结果。 因此,用于训练的数据集非常重要。
脸部预处理旨在通过确保脸部始终看起来具有相似的亮度和对比度,或许还能确保脸部特征始终处于同一位置(例如将眼睛和/或鼻子与某些位置对齐)来减少这些问题。 一个好的人脸预处理阶段将有助于提高整个人脸识别系统的可靠性,因此本章将重点介绍人脸预处理方法。
尽管媒体大肆宣扬使用人脸识别进行安全保护,但目前的人脸识别方法本身不太可能足够可靠,适用于任何真正的安全系统。 然而,它们可以用于不需要高可靠性的目的,比如为进入房间的不同人播放个性化音乐,或者机器人看到你时会叫你的名字。 人脸识别还有各种实用的扩展,如性别识别、年龄识别和情感识别。
人脸检测
直到 2000 年,有许多不同的技术用于寻找人脸,但它们要么非常慢,要么非常不可靠,要么两者兼而有之。 一个重大的变化出现在 2001 年,当时 Viola 和 Jones 发明了基于 Haar 的级联分类器用于目标检测,2002 年 Lienhart 和 Maydt 对其进行了改进。 结果是一种既快速(它可以用 VGA 网络摄像头在典型的桌面上实时检测人脸)又可靠(它能正确检测大约 95%的正面人脸)的物体检测器。 这种物体检测器彻底改变了人脸识别领域(以及整个机器人和计算机视觉领域),因为它最终实现了实时人脸检测和人脸识别,特别是当 Lienhart 自己编写了 OpenCV 免费提供的物体检测器时! 它不仅适用于正面,也适用于侧视图面(称为纵断面)、眼睛、嘴巴、鼻子、公司徽标和许多其他对象。
此对象检测器在 OpenCV v2.0 中进行了扩展,在 Ahonen、Hahad 和 Pietikäinen 于 2006 年所做工作的基础上也使用了 LBP 功能进行检测,因为基于 LBP 的检测器可能比基于 Haar 的检测器快好几倍,并且不存在许多 Haar 检测器所具有的许可问题。
OpenCV 实现了从 V3.4 到 V4.0 的深度学习,在这一章中,我们将展示如何使用单镜头多盒检测器和(SSD)算法进行人脸检测。
基于 Haar 的人脸检测器的基本思想是,如果你看大多数正面脸,眼睛的区域应该比额头和脸颊暗,嘴巴的区域应该比脸颊暗,以此类推。 它通常会进行大约 20 个阶段的比较,以确定它是否是一张脸,但它必须在图像中的每一个可能的位置,以及每种可能的脸大小上进行比较,所以实际上,它通常会对每张图像进行数千次检查。 基于 LBP 的人脸检测器的基本思想类似于基于 Haar 的人脸检测器,但它使用像素强度比较的直方图,例如边缘、角点和平坦区域。
无需让人决定哪种比较最适合定义人脸,基于 Haar 和 LBP 的人脸检测器都可以自动训练,从一大组图像中找到人脸,并将信息存储为 XML 文件,供以后使用。这两种人脸检测器都可以被自动训练,从一大组图像中找到人脸,并将信息存储为 XML 文件,以供以后使用。 这些级联分类器检测器通常使用至少 1,000 个独特的人脸图像和 10,000 个非人脸图像(例如,树木、汽车和文本的照片)进行训练,即使在多核台式机上,训练过程也可能需要很长时间(LBP 通常需要几个小时,而 Haar!则需要一周)。 幸运的是,OpenCV 附带了一些经过预先训练的 Haar 和 LBP 检测器供您使用! 事实上,您只需将不同的级联分类器 XML 文件加载到对象检测器中,然后根据您选择的 XML 文件在 Haar 和 LBP 检测器之间进行选择,就可以检测正脸、侧面(侧视)脸、眼睛或鼻子。
利用 OpenCV 级联分类器实现人脸检测
如前所述,OpenCV v2.4 附带了各种经过预先训练的 XML 检测器,您可以将其用于不同的目的。 下表列出了一些最常用的 XML 文件:
| 级联分类器的类型 | XML 文件名 |
| 人脸检测器(默认) | haarcascade_frontalface_default.xml |
| 人脸检测器(FAST HAAR) | haarcascade_frontalface_alt2.xml |
| 人脸检测器(快速 LBP) | lbpcascade_frontalface.xml |
| 侧面(侧视)人脸检测器 | haarcascade_profileface.xml |
| 眼睛探测器(左右分开) | haarcascade_lefteye_2splits.xml |
| 口腔探测仪 | haarcascade_mcs_mouth.xml |
| 鼻部探测器 | haarcascade_mcs_nose.xml |
| 全人探测器 | haarcascade_fullbody.xml |
基于 HAAR 的检测器存储在 OpenCV 根文件夹的data/haarcascades文件夹中,基于 LBP 的检测器存储在 OpenCV 根文件夹的datal/bpcascades文件夹中,例如:C:\\opencv\\data\\lbpcascades。
对于我们的人脸识别项目,我们想要检测正面人脸,所以让我们使用 LBP 人脸检测器,因为它速度最快,而且不存在专利许可问题。 请注意,OpenCV v2.x 附带的预先训练的 LBP 人脸检测器没有像预先训练的 Haar 人脸检测器一样进行调整,因此如果您想要更可靠的人脸检测,那么您可能需要训练自己的 LBP 人脸检测器或使用 Haar 人脸检测器。
加载用于目标或人脸检测的 Haar 或 LBP 检测器
要执行对象或人脸检测,首先必须使用 OpenCV 的CascadeClassifier类加载预先训练好的 XML 文件,如下所示:
CascadeClassifier faceDetector;
faceDetector.load(faceCascadeFilename);
只需给出一个不同的文件名,就可以加载 Haar 或 LBP 检测器。 使用这种方法时,一个非常常见的错误是提供了错误的文件夹或文件名,但是根据您的构建环境的不同,load()方法要么返回false,要么生成 C++ 异常(并退出程序并返回 Assert 错误)。 因此,最好用一个try... catch块包围load()方法,并在出现错误时向用户显示一条错误消息。 许多初学者会跳过错误检查,但在某些内容加载不正确时向用户显示帮助消息是至关重要的;否则,您可能需要花费很长时间来调试代码的其他部分,然后才能最终意识到某些内容没有加载。 可以显示一条简单的错误消息,如下所示:
CascadeClassifier faceDetector;
try {
faceDetector.load(faceCascadeFilename);
} catch (cv::Exception e) {}
if ( faceDetector.empty() ) {
cerr << "ERROR: Couldn't load Face Detector (";
cerr << faceCascadeFilename << ")!" << endl;
exit(1);
}
访问网络摄像头
要从计算机的网络摄像头甚至视频文件中抓取帧,您只需调用带有摄像头编号或视频文件名的VideoCapture::open()函数,然后使用 C++ 流运算符抓取帧,如第第 13 章第章中的访问网络摄像头一节中所述,在 Raspberry Pi 上执行Cartoonizer and Skin Color Analysis(Raspberry PI中的Cartoonizer and Skin Color Analysis)。
使用 Haar 或 LBP 分类器检测对象
现在我们已经加载了分类器(只在初始化期间加载了一次),我们可以使用它来检测每个新摄像机帧中的人脸。 但首先,我们应该通过执行以下步骤对摄像头图像进行一些初始处理,仅用于人脸检测:
- 灰度颜色转换:人脸检测仅适用于灰度图像。 所以我们应该把彩色相机的画面转换成灰度。
- 缩小相机图像:人脸检测的速度取决于输入图像的大小(对于大图像非常慢,但对于小图像很快),但是即使在低分辨率下,检测仍然相当可靠。 因此,我们应该将摄像机图像缩小到更合理的大小(或者在检测器中使用较大的值
minFeatureSize,如以下各节所述)。 - 直方图均衡:人脸检测在弱光条件下不太可靠。 因此,需要对图像进行直方图均衡化,以提高图像的对比度和亮度。
灰度颜色转换
我们可以使用cvtColor()函数轻松地将 RGB 彩色图像转换为灰度图像。 但是,只有当我们知道我们有彩色图像(即,它不是灰度相机),并且我们必须指定输入图像的格式(通常台式机上是三通道 BGR 或移动设备上是四通道 BGRA)时,我们才应该这样做。 因此,我们应该允许三种不同的输入颜色格式,如以下代码所示:
Mat gray;
if (img.channels() == 3) {
cvtColor(img, gray, COLOR_BGR2GRAY);
}
else if (img.channels() == 4) {
cvtColor(img, gray, COLOR_BGRA2GRAY);
}
else {
// Access the grayscale input image directly.
gray = img;
}
缩小摄像机图像
我们可以使用resize()函数将图像缩小到一定的大小或比例因子。 人脸检测通常对任何大小大于 240 x 240 像素的图像都非常有效(除非您需要检测远离摄像头的人脸),因为它会查找任何大于minFeatureSize像素(通常为 20 x 20 像素)的人脸。 因此,让我们将摄像头图像缩小到 320 像素宽;输入是 VGA 网络摄像头还是 500 万像素高清摄像头都无关紧要。 记住和放大检测结果也很重要,因为如果在缩小的图像中检测人脸,那么结果也会缩小。 请注意,您可以在检测器中使用一个较大的值,而不是缩小输入图像。 我们还必须确保图像不会变得更胖或更瘦。 例如,一张 800x400 的宽屏图像缩小到 300x200 会让人看起来很瘦。 因此,我们必须保持输出的纵横比(宽高比)与输入相同。 让我们计算一下图像宽度要缩小多少,然后对高度应用相同的比例因子,如下所示:
const int DETECTION_WIDTH = 320;
// Possibly shrink the image, to run much faster.
Mat smallImg;
float scale = img.cols / (float) DETECTION_WIDTH;
if (img.cols > DETECTION_WIDTH) {
// Shrink the image while keeping the same aspect ratio.
int scaledHeight = cvRound(img.rows / scale);
resize(img, smallImg, Size(DETECTION_WIDTH, scaledHeight));
}
else {
// Access the input directly since it is already small.
smallImg = img;
}
直方图均衡
使用equalizeHist()函数,我们可以轻松地执行直方图均衡化,以提高图像的对比度和亮度。 有时这会让图像看起来很奇怪,但一般来说,它应该会提高亮度和对比度,并有助于人脸检测。 equalizeHist()函数的用法如下:
// Standardize the brightness & contrast, such as
// to improve dark images.
Mat equalizedImg;
equalizeHist(inputImg, equalizedImg);
检测人脸
现在我们已经将图像转换为灰度,缩小了图像,并均衡了直方图,接下来我们就可以使用CascadeClassifier::detectMultiScale()函数检测人脸了! 我们传递给此函数的参数很多,如下所示:
minFeatureSize:此参数确定我们关心的最小人脸大小,通常为 20x20 或 30x30 像素,但这取决于您的使用案例和图像大小。 如果您在网络摄像头或智能手机上执行人脸检测,其中人脸始终离摄像头很近,则可以将其放大到 80 x 80 以获得更快的检测速度,或者如果您想要检测较远的人脸,如与朋友一起在海滩上,则将其保留为 20 x 20。searchScaleFactor:此参数确定要查找多少个不同大小的人脸;通常情况下,如果检测良好,则为1.1;如果检测更快,则为1.2,这样就不会经常找到人脸。minNeighbors:此参数确定检测器应在多大程度上确定它已检测到人脸;它的值通常为 13,但如果您想要更可靠的人脸,即使没有检测到许多人脸,也可以将其设置得更高。flags:此参数允许您指定是查找所有面(默认),还是仅查找最大的面(CASCADE_FIND_BIGGEST_OBJECT)。 如果你只寻找最大的脸,它应该跑得更快。 您还可以添加其他几个参数,使检测速度提高约 1%或 2%,如CASCADE_DO_ROUGH_SEARCH或CASCADE_SCALE_IMAGE。
参数detectMultiScale()函数的输出将是参数cv::Rect类型对象的参数std::vector。 例如,如果它检测到两个面,那么它将在输出中存储一个由两个矩形组成的数组。 detectMultiScale()函数的用法如下:
int flags = CASCADE_SCALE_IMAGE; // Search for many faces.
Size minFeatureSize(20, 20); // Smallest face size.
float searchScaleFactor = 1.1f; // How many sizes to search.
int minNeighbors = 4; // Reliability vs many faces.
// Detect objects in the small grayscale image.
std::vector<Rect> faces;
faceDetector.detectMultiScale(img, faces, searchScaleFactor,
minNeighbors, flags, minFeatureSize);
我们可以通过查看存储在矩形向量中的元素数量(即,通过使用objects.size()函数)来查看是否检测到任何人脸。
正如前面提到的,如果我们给人脸检测器一个缩小的图像,结果也会缩小,所以如果我们想要看到原始图像的人脸区域,就需要放大它们。 我们还需要确保图像边界上的面完全位于图像内,因为如果发生这种情况,OpenCV 现在将引发异常,如以下代码所示:
// Enlarge the results if the image was temporarily shrunk.
if (img.cols > scaledWidth) {
for (auto& object:objects ) {
object.x = cvRound(object.x * scale);
object.y = cvRound(object.y * scale);
object.width = cvRound(object.width * scale);
object.height = cvRound(object.height * scale);
}
}
// If the object is on a border, keep it in the image.
for (auto& object:objects) {
if (object.x < 0)
object.x = 0;
if (object.y < 0)
object.y = 0;
if (object.x + object.width > img.cols)
object.x = img.cols - object.width;
if (object.y + object.height > img.rows)
object.y = img.rows - object.height;
}
请注意,前面的代码将查找图像中的所有面孔,但如果您只关心一个面孔,则可以按如下方式更改flags变量:
int flags = CASCADE_FIND_BIGGEST_OBJECT |
CASCADE_DO_ROUGH_SEARCH;
WebcamFaceRec项目包括 OpenCV 的 Haar 或 LBP 探测器的包装,以便更容易在图像中找到人脸或眼睛,例如:
Rect faceRect; // Stores the result of the detection, or -1\.
int scaledWidth = 320; // Shrink the image before detection.
detectLargestObject(cameraImg, faceDetector, faceRect, scaledWidth);
if (faceRect.width > 0)
cout << "We detected a face!" << endl;
现在我们有了一个脸部矩形,我们可以通过多种方式使用它,比如从原始图像中提取或裁剪脸部。 下面的代码允许我们访问人脸:
// Access just the face within the camera image.
Mat faceImg = cameraImg(faceRect);
下图显示了人脸检测器给出的典型矩形区域:

利用 OpenCV 深度学习模块实现人脸检测
从 OpenCV3.4 开始,深度学习模块可以作为补充资源(https://github.com/opencv/opencv_contrib),但是从 4.0 版开始,深度学习是 OpenCV 核心的一部分。 这意味着 OpenCV 深度学习运行稳定,维护良好。
我们可以使用基于 SSD 和深度学习算法的预先训练的 Caffe 模型来进行人脸识别。 该算法允许我们在单个深度学习网络中检测一幅图像中的多个对象,并为每个检测到的对象返回一个类和边界框。
要加载预先训练的 Caffe 模型,我们需要加载两个文件:
- Proto 文件或配置模型;在我们的示例中,该文件保存在
data/deploy.prototxt中 - 二进制训练模型,其中包含每个变量的权重;在我们的示例中,文件保存在
data/res10_300x300_ssd_iter_140000_fp16.caffemodel中
下面的代码允许我们将模型加载到 OpenCV 中:
dnn::Net net = readNetFromCaffe("data/deploy.prototxt", "data/res10_300x300_ssd_iter_14000_fp16.caffemodel");
加载深度学习网络后,根据我们用摄像头捕捉到的每一帧,我们必须将其转换为深度学习网络可以理解的斑点图像。 我们必须按如下方式使用blobFromImage命令函数:
Mat inputBlob = blobFromImage(frame, 1.0, Size(300, 300), meanVal, false, false);
其中,第一个参数是输入图像,第二个参数是每个像素值的缩放因子,第三个参数是输出空间大小,第四个参数是要从每个通道减去的Scalar值,第五个参数是交换B和R通道的标志,最后一个参数,如果我们将最后一个参数设置为 true,它将在调整大小后裁剪图像。
现在,我们已经为深度神经网络准备了输入图像;要将其设置为网络,我们必须调用以下函数:
net.setInput(inputBlob);
最后,我们可以调用网络进行如下预测:
Mat detection = net.forward();
人脸预处理
如前所述,人脸识别极易受到光照条件、人脸朝向、人脸表情等变化的影响,因此尽可能减少这些差异非常重要。 否则,人脸识别算法通常会认为在相同条件下两个不同人的脸之间比同一人的两幅图像之间有更多的相似性。
最简单的人脸预处理方法就是使用equalizeHist()函数应用直方图均衡化,就像我们刚才对人脸检测所做的那样。 对于照明和位置条件不会有太大变化的某些项目来说,这可能就足够了。 但是为了在真实世界中的可靠性,我们需要许多复杂的技术,包括人脸特征检测(例如,检测眼睛、鼻子、嘴巴和眉毛)。 为简单起见,本章将只使用眼睛检测,而忽略其他人脸特征,如嘴巴和鼻子,这些特征用处较小。
下图显示了使用本节将介绍的技术的典型预处理人脸的放大视图:

眼睛检测
眼睛检测对于人脸的预处理也非常有用,因为对于正脸,你总是可以假设一个人的眼睛应该是水平的,在脸部的相对两侧,并且应该在脸部内有一个相当标准的位置和大小,尽管人脸表情、光照条件、相机属性、到相机的距离等都发生了变化。
当人脸检测器说它检测到了一张脸,而它实际上是另一张脸时,丢弃假阳性也很有用。 人脸检测器和两个眼睛检测器同时被愚弄的情况很少见,因此如果只处理带有一个检测到的人脸和两个检测到的眼睛的图像,那么它就不会有太多的假阳性(但也会给出更少的人脸进行处理,因为眼睛检测器不会像人脸检测器那样频繁地工作)。
OpenCV v2.4 附带的一些预先训练的眼睛检测器可以检测眼睛是睁开的还是闭着的,而有些只能检测睁开的眼睛。
检测眼睛睁开或闭上的眼睛检测器如下:
haarcascade_mcs_lefteye.xml(andhaarcascade_mcs_righteye.xml)haarcascade_lefteye_2splits.xml(andhaarcascade_righteye_2splits.xml)
仅检测睁开眼睛的眼睛检测器如下:
haarcascade_eye.xmlhaarcascade_eye_tree_eyeglasses.xml
As the open or closed eye detectors specify which eye they are trained on, you need to use a different detector for the left and the right eye, whereas the detectors for just open eyes can use the same detector for left or right eyes.
The haarcascade_eye_tree_eyeglasses.xml detector can detect the eyes if the person is wearing glasses, but is not reliable if they don't wear glasses.
If the XML filename says left eye, it means the actual left eye of the person, so in the camera image it would normally appear on the right-hand side of the face, not on the left-hand side!
The list of four eye detectors mentioned is ranked in approximate order from most reliable to least reliable, so if you know you don't need to find people with glasses, then the first detector is probably the best choice.
眼睛搜索区域
对于眼睛检测,重要的是裁剪输入图像以仅显示大致的眼睛区域,就像做人脸检测,然后裁剪到左眼应该位于的小矩形(如果您使用的是左眼检测器),右眼检测器的右矩形也是如此。
如果你只是在整张脸或整张照片上做眼睛检测,那么速度会慢得多,可靠性也会差得多。 不同的眼睛检测器更适合人脸的不同区域;例如,如果只在实际眼睛周围非常紧密的区域进行搜索,则haarcascade_eye.xml检测器的工作效果最好,而当眼睛周围有较大区域时,haarcascade_mcs_lefteye.xml和haarcascade_lefteye_2splits.xml的检测效果最好。
下表列出了使用检测到的人脸矩形内的相对坐标(EYE_SX是眼睛搜索x位置,EYE_SY是眼睛搜索y位置,EYE_SW是眼睛搜索宽度,EYE_SH是眼睛搜索高度)对不同眼睛检测器(使用 LBP 脸部检测器时)的脸部的一些较好的搜索区域:(EYE_SX是眼睛搜索x位置,EYE_SY是眼睛搜索y位置,EYE_SW是眼睛搜索宽度,EYE_SH是眼睛搜索高度):
| 级联分类器 | EYE_SX | EYE_SY | EYE_SW | EYE_SH |
| haarcascade_eye.xml | 0.16 | 0.26 | 0.30 | 0.28 |
| haarcascade_mcs_lefteye.xml | 0.10 | 0.19 | 0.40 | 0.36 |
| haarcascade_lefteye_2splits.xml | 0.12 | 0.17 | 0.37 | 0.36 |
以下是从检测到的人脸中提取左眼和右眼区域的源代码:
int leftX = cvRound(face.cols * EYE_SX);
int topY = cvRound(face.rows * EYE_SY);
int widthX = cvRound(face.cols * EYE_SW);
int heightY = cvRound(face.rows * EYE_SH);
int rightX = cvRound(face.cols * (1.0-EYE_SX-EYE_SW));
Mat topLeftOfFace = faceImg(Rect(leftX, topY, widthX, heightY));
Mat topRightOfFace = faceImg(Rect(rightX, topY, widthX, heightY));
下图显示了不同人眼检测器的理想搜索区域,其中,文件haarcascade_eye.xml和文件haarcascade_eye_tree_eyeglasses.xml的搜索区域最小,文件haarcascade_mcs_*eye.xml和文件haarcascade_*eye_2splits.xml的搜索区域最大。 请注意,还会显示检测到的人脸矩形,以便了解眼睛搜索区域与检测到的人脸矩形相比有多大:

下表列出了使用眼睛搜索区域时不同眼睛检测器的近似检测特性:
| 级联分类器 | 可靠性 | 速度 | *发现眼睛 | 眼镜 |
| haarcascade_mcs_lefteye.xml | 80% | 18 毫秒 | 打开或关闭 | 完全不 / 决不 / 不 |
| haarcascade_lefteye_2splits.xml | 60% | 7 毫秒 | 打开或关闭 | 完全不 / 决不 / 不 |
| haarcascade_eye.xml | 40% | 5 毫秒 | 仅打开 | 完全不 / 决不 / 不 |
| haarcascade_eye_tree_eyeglasses.xml | 15% | 10 毫秒 | 仅打开 | 肯定的回答 / 赞成 / 是 |
可靠性数值表示在未戴眼镜且双眼睁开的情况下,在 LBP 正面人脸检测后检测双眼的频率。 如果闭上眼睛,可靠性可能会下降,如果戴上眼镜,可靠性和速度都会下降。
速度对于在英特尔酷睿 i7 2.2 GHz(平均为 1,000 张照片)上缩放到 320 x 240 像素大小的图像,其值以毫秒为单位。 发现眼睛时的速度通常比没有眼睛时快得多,因为它必须扫描整个图像,但haarcascade_mcs_lefteye.xml仍然比其他眼睛检测器慢得多。
例如,如果您将一张照片缩小到 320 x 240 像素,对其执行直方图均衡化,使用 LBP 正面人脸检测器获取人脸,然后使用 LBPhaarcascade_mcs_lefteye.xml值从人脸提取左眼区域和右眼区域,然后对每个眼睛区域执行直方图均衡化。 然后,如果你在左眼(实际上在图像的右上角)使用haarcascade_mcs_lefteye.xml检测器,在右眼(图像的左上角)使用haarcascade_mcs_righteye.xml检测器,每个眼睛检测器应该可以在大约 90%的带有 LBP 检测到的正面的照片中工作。 因此,如果你想检测两只眼睛,那么它应该在大约 80%的带有 LBP 检测到的正面脸的照片中起作用。
请注意,虽然不建议在检测人脸之前缩小摄像头图像,但您应该在完全摄像头分辨率下检测眼睛,因为眼睛显然会比人脸小得多,所以您需要尽可能获得更高的分辨率。
Based on the table, it seems that when choosing an eye detector to use, you should decide whether you want to detect closed eyes or only open eyes. And remember that you can even use one eye detector, and if it does not detect an eye, then you can try with another one.
For many tasks, it is useful to detect eyes whether they are open or closed, so if speed is not crucial, it is best to search with the mcs_*eye detector first, and if it fails, then search with the eye_2splits detector.
But for face recognition, a person will appear quite different if their eyes are closed, so it is best to search with the plain haarcascade_eye detector first, and if it fails, then search with the haarcascade_eye_tree_eyeglasses detector.
我们可以使用与人脸检测相同的detectLargestObject()函数来搜索眼睛,但我们没有在眼睛检测之前要求缩小图像,而是指定了完整的眼睛区域宽度,以获得更好的眼睛检测。 使用一个检测器搜索左眼很容易,如果失败,则尝试另一个检测器(右眼也是如此)。 眼睛检测如下:
CascadeClassifier eyeDetector1("haarcascade_eye.xml");
CascadeClassifier eyeDetector2("haarcascade_eye_tree_eyeglasses.xml");
...
Rect leftEyeRect; // Stores the detected eye.
// Search the left region using the 1st eye detector.
detectLargestObject(topLeftOfFace, eyeDetector1, leftEyeRect,
topLeftOfFace.cols);
// If it failed, search the left region using the 2nd eye
// detector.
if (leftEyeRect.width <= 0)
detectLargestObject(topLeftOfFace, eyeDetector2,
leftEyeRect, topLeftOfFace.cols);
// Get the left eye center if one of the eye detectors worked.
Point leftEye = Point(-1,-1);
if (leftEyeRect.width <= 0) {
leftEye.x = leftEyeRect.x + leftEyeRect.width/2 + leftX;
leftEye.y = leftEyeRect.y + leftEyeRect.height/2 + topY;
}
// Do the same for the right eye
...
// Check if both eyes were detected.
if (leftEye.x >= 0 && rightEye.x >= 0) {
...
}
在检测到人脸和双眼之后,我们将结合以下步骤进行人脸预处理:
- 几何变换和裁剪:此过程包括缩放、旋转和平移图像以使眼睛对齐,然后从人脸图像中移除前额、下巴、耳朵和背景。
- 左右两侧的单独直方图均衡:此过程独立地标准化脸部左右两侧的亮度和对比度。
- 平滑:此过程使用双边滤波器降低图像噪声。
- 椭圆蒙版:椭圆蒙版从脸部图像中去除一些剩余的毛发和背景。
下面的照片显示了应用于检测到的人脸的人脸预处理步骤 1至步骤 4。 请注意,最终的照片在脸部两侧的亮度和对比度都很好,而原始照片的亮度和对比度却不好:

几何变换
重要的是,所有的脸都要对齐,否则人脸识别算法可能会比较鼻子的一部分和眼睛的一部分,以此类推。 我们刚才看到的人脸检测的输出将在一定程度上给出对齐的人脸,但它不是非常准确(即,人脸矩形不会总是从额头上的同一点开始)。
为了有更好的视觉对准,我们将使用眼睛检测来对齐人脸,这样检测到的两只眼睛的位置就会完美地排在所需的位置。 我们将使用warpAffine()函数进行几何变换,这是一个单独的操作,将执行以下四项操作:
- 旋转面,使两只眼睛水平
- 缩放面,使两只眼睛之间的距离始终相同
- 平移面,使眼睛始终水平居中,并位于所需高度
- 裁剪人脸的外部,因为我们要裁剪图像背景、头发、额头、耳朵和下巴
仿射扭曲采用仿射矩阵,该矩阵将检测到的两个眼睛位置转换为两个所需的眼睛位置,然后裁剪成所需的大小和位置。 要生成此仿射矩阵,我们将获得两个眼睛之间的中心,计算两个检测到的眼睛出现的角度,并查看它们之间的距离,如下所示:
// Get the center between the 2 eyes.
Point2f eyesCenter;
eyesCenter.x = (leftEye.x + rightEye.x) * 0.5f;
eyesCenter.y = (leftEye.y + rightEye.y) * 0.5f;
// Get the angle between the 2 eyes.
double dy = (rightEye.y - leftEye.y);
double dx = (rightEye.x - leftEye.x);
double len = sqrt(dx*dx + dy*dy);
// Convert Radians to Degrees.
double angle = atan2(dy, dx) * 180.0/CV_PI;
// Hand measurements shown that the left eye center should
// ideally be roughly at (0.16, 0.14) of a scaled face image.
const double DESIRED_LEFT_EYE_X = 0.16;
const double DESIRED_RIGHT_EYE_X = (1.0f - 0.16);
// Get the amount we need to scale the image to be the desired
// fixed size we want.
const int DESIRED_FACE_WIDTH = 70;
const int DESIRED_FACE_HEIGHT = 70;
double desiredLen = (DESIRED_RIGHT_EYE_X - 0.16);
double scale = desiredLen * DESIRED_FACE_WIDTH / len;
现在,我们可以对脸部进行变换(旋转、缩放和平移),以使检测到的两只眼睛位于理想脸部中所需的眼睛位置,如下所示:
// Get the transformation matrix for the desired angle & size.
Mat rot_mat = getRotationMatrix2D(eyesCenter, angle, scale);
// Shift the center of the eyes to be the desired center.
double ex = DESIRED_FACE_WIDTH * 0.5f - eyesCenter.x;
double ey = DESIRED_FACE_HEIGHT * DESIRED_LEFT_EYE_Y -
eyesCenter.y;
rot_mat.at<double>(0, 2) += ex;
rot_mat.at<double>(1, 2) += ey;
// Transform the face image to the desired angle & size &
// position! Also clear the transformed image background to a
// default grey.
Mat warped = Mat(DESIRED_FACE_HEIGHT, DESIRED_FACE_WIDTH,
CV_8U, Scalar(128));
warpAffine(gray, warped, rot_mat, warped.size());
左右两侧分开的直方图均衡化
在现实世界的条件下,半边脸的光线很强,而另一半的光线很弱,这是很常见的。 这对人脸识别算法有很大的影响,因为同一张脸的左右两侧看起来就像是非常不同的人。 因此,我们将在脸部的左右半部分分别进行直方图均衡化,以获得标准化的脸部两侧的亮度和对比度。
如果我们简单地在左半部分应用直方图均衡,然后在右半部分应用直方图均衡,我们将在中间看到一个非常明显的边缘,因为左右两侧的平均亮度可能不同。 因此,为了去除这一边缘,我们将从左侧或右侧向中心逐渐应用两个直方图均衡化,并将其与整个人脸直方图均衡化混合在一起。
然后,最左侧将使用左侧直方图均衡化,最右侧将使用右侧直方图均衡化,中心将使用左右两个值和整个人脸均衡值的平滑混合。
下面的屏幕截图显示了左均衡、全均衡和右均衡图像是如何混合在一起的:

要做到这一点,我们需要整张脸的复印件均衡化,以及左半面均衡化和右半面均衡化,具体操作如下:
int w = faceImg.cols;
int h = faceImg.rows;
Mat wholeFace;
equalizeHist(faceImg, wholeFace);
int midX = w/2;
Mat leftSide = faceImg(Rect(0,0, midX,h));
Mat rightSide = faceImg(Rect(midX,0, w-midX,h));
equalizeHist(leftSide, leftSide);
equalizeHist(rightSide, rightSide);
现在,我们将这三幅图像合并在一起。 由于图像较小,即使速度较慢,我们也可以使用image.at<uchar>(y,x)函数直接访问像素;因此,让我们通过直接访问三个输入图像和输出图像中的像素来合并这三个图像,如下所示:
for (int y=0; y<h; y++) {
for (int x=0; x<w; x++) {
int v;
if (x < w/4) {
// Left 25%: just use the left face.
v = leftSide.at<uchar>(y,x);
}
else if (x < w*2/4) {
// Mid-left 25%: blend the left face & whole face.
int lv = leftSide.at<uchar>(y,x);
int wv = wholeFace.at<uchar>(y,x);
// Blend more of the whole face as it moves
// further right along the face.
float f = (x - w*1/4) / (float)(w/4);
v = cvRound((1.0f - f) * lv + (f) * wv);
}
else if (x < w*3/4) {
// Mid-right 25%: blend right face & whole face.
int rv = rightSide.at<uchar>(y,x-midX);
int wv = wholeFace.at<uchar>(y,x);
// Blend more of the right-side face as it moves
// further right along the face.
float f = (x - w*2/4) / (float)(w/4);
v = cvRound((1.0f - f) * wv + (f) * rv);
}
else {
// Right 25%: just use the right face.
v = rightSide.at<uchar>(y,x-midX);
}
faceImg.at<uchar>(y,x) = v;
} // end x loop
} //end y loop
这种分开的直方图均衡化应该有助于显著降低不同光照对脸部左右两侧的影响,但我们必须理解,它不会完全消除单面光照的影响,因为脸部是一个复杂的 3D 形状,有很多阴影。
光滑的 / 平滑的 / 醇和的 / 不苦的
为了更好地减少像素噪声的影响,我们将在人脸上使用双边过滤器,因为双边过滤器非常擅长在保持边缘锐利的同时平滑图像的大部分。 直方图均衡会显著增加像素噪波,因此我们将使过滤器强度20.0增加以覆盖较大的像素噪波,并且只使用两个像素的邻域,因为我们希望对微小的像素噪波进行大量平滑,而不是对较大的图像区域进行大量平滑,如下所示:
Mat filtered = Mat(warped.size(), CV_8U);
bilateralFilter(warped, filtered, 0, 20.0, 2.0);
椭圆掩模
虽然我们在进行几何变换时已经移除了大部分图像背景、额头和头发,但我们可以应用椭圆形蒙版来移除一些角落区域,如颈部,这些区域可能在脸部的阴影中,特别是如果脸部没有完全直视相机的话。 为了创建蒙版,我们将在白色图像上绘制一个黑色填充的椭圆。 要执行此操作的一个椭圆的水平半径为 0.5(即,它完全覆盖了面的宽度),垂直半径为 0.8(因为面通常比宽高),并居中于坐标 0.5,0.4,如下面的屏幕截图所示,其中椭圆遮罩已从面中移除了一些不需要的角:

我们可以在调用cv::setTo()函数时应用遮罩,该函数通常会将整个图像设置为某个像素值,但由于我们将给出遮罩图像,因此它只会将某些部分设置为给定的像素值。 我们将用灰色填充图像,使其与脸部其他部分的对比度较小,如下所示:
// Draw a black-filled ellipse in the middle of the image.
// First we initialize the mask image to white (255).
Mat mask = Mat(warped.size(), CV_8UC1, Scalar(255));
double dw = DESIRED_FACE_WIDTH;
double dh = DESIRED_FACE_HEIGHT;
Point faceCenter = Point( cvRound(dw * 0.5),
cvRound(dh * 0.4) );
Size size = Size( cvRound(dw * 0.5), cvRound(dh * 0.8) );
ellipse(mask, faceCenter, size, 0, 0, 360, Scalar(0),
CV_FILLED);
// Apply the elliptical mask on the face, to remove corners.
// Sets corners to gray, without touching the inner face.
filtered.setTo(Scalar(128), mask);
下面放大的屏幕截图显示了所有人脸预处理阶段的样本结果。 请注意,在不同亮度、不同脸部旋转、不同摄像头角度、不同背景、不同灯光位置等情况下,人脸识别的一致性要高得多。 无论是在收集用于训练的人脸时,还是在尝试识别输入人脸时,预处理后的人脸都将用作人脸识别阶段的输入:
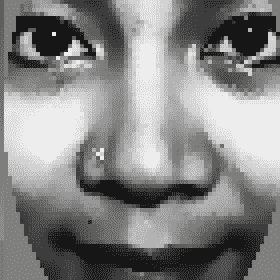
收集人脸并从中学习
收集人脸可以很简单,只需将每个新预处理的人脸图像放入摄像机中的一组预处理人脸中,以及将标签放入一个数组中(以指定该人脸来自哪个人)。 例如,您可以使用第一人称的 10 个预处理人脸和第二个人的 10 个预处理人脸,因此人脸识别算法的输入将是一个由 20 个预处理人脸组成的数组和一个由 20 个整数组成的数组(其中前 10 个数字是 0,后面 10 个数字是 1)。
然后,人脸识别算法将学习如何区分不同人的脸。 这称为训练阶段,收集的面称为训练集。 在人脸识别算法完成训练后,您可以将生成的知识保存到文件或内存中,然后使用它来识别摄像机前看到的是哪个人。 这称为测试阶段。 如果直接从相机输入使用它,则预处理的面将被称为测试图像,如果您使用多个图像(例如,来自图像文件的文件夹)进行测试,则它将被称为测试集。
重要的是,您要提供一个良好的培训集,涵盖您预期的测试集中可能发生的变化类型。 例如,如果您只测试直视正面的人脸(例如 ID 照片),那么您只需要为训练图像提供正面正视的人脸。 但如果这个人可能看向左边或上面,那么你应该确保训练集也包括这样做的人的脸,否则人脸识别算法将很难识别他们,因为他们的脸看起来会有很大的不同。 这也适用于其他因素,例如人脸表情(例如,如果人在训练集中总是微笑,但在测试集中没有微笑)或照明方向(例如,强光在训练集中在左侧,但在测试集中在右侧),则人脸识别算法将难以识别它们。 我们刚才看到的人脸预处理步骤将有助于减少这些问题,但它肯定不会消除这些因素,特别是人脸所看的方向,因为它对人脸所有元素的位置有很大影响。
One way to obtain a good training set that will cover many different real-world conditions is for each person to rotate their head from looking left, to up, to right, to down, then looking directly straight. Then, the person tilts their head sideways and then up and down, while also changing their facial expression, such as alternating between smiling, looking angry, and having a neutral face. If each person follows a routine such as this while collecting faces, then there is a much better chance of recognizing everyone in real-world conditions. For even better results, it should be performed again with one or two more locations or directions, such as by turning the camera around 180 degrees, walking in the opposite direction, and then repeating the whole routine, so that the training set would include many different lighting conditions.
因此,一般来说,每个人有 100 张训练脸可能比每个人只有 10 张训练脸效果更好,但如果所有 100 张脸看起来几乎一样,那么它的表现仍然会很差,因为更重要的是训练集有足够的多样性来覆盖测试集,而不是只有大量的脸。 因此,为了确保训练集中的人脸不会太相似,我们应该在每个收集到的人脸之间添加明显的延迟。 例如,如果相机以每秒 30 帧的速度运行,那么当人没有时间四处走动时,它可能会在短短几秒钟内采集 100 张脸,所以最好是在人移动脸的时候每秒只采集一张脸。 改进训练集中变化的另一种简单方法是仅在脸部与先前收集的脸部显著不同时才收集脸部。
采集预处理后的人脸进行训练
为了确保收集新面孔之间至少有一秒的差距,我们需要更好地衡量已经过去了多少时间。 此操作如下所示:
// Check how long since the previous face was added.
double current_time = (double)getTickCount();
double timeDiff_seconds = (current_time -
old_time) / getTickFrequency();
要逐个像素比较两个图像的相似性,您可以找到相对的 L2 误差,这只需要将一幅图像减去另一幅图像,将其平方值相加,然后求出它的平方根。 因此,如果这个人根本没有移动,从前一张脸中减去当前脸应该会给出一个非常小的数字,但如果他们只是在任何方向上稍微移动了一下,减去像素就会得到一个很大的数字,所以 L2 误差会很大。 由于结果是对所有像素求和,因此该值将取决于图像分辨率。 所以要得到平均误差,我们应该用这个值除以图像中的总像素数。 让我们将其放在一个方便的函数getSimilarity()中,如下所示:
double getSimilarity(const Mat A, const Mat B) {
// Calculate the L2 relative error between the 2 images.
double errorL2 = norm(A, B, CV_L2);
// Scale the value since L2 is summed across all pixels.
double similarity = errorL2 / (double)(A.rows * A.cols);
return similarity;
}
...
// Check if this face looks different from the previous face.
double imageDiff = MAX_DBL;
if (old_prepreprocessedFaceprepreprocessedFace.data) {
imageDiff = getSimilarity(preprocessedFace,
old_prepreprocessedFace);
}
如果图像移动不多,则相似度通常小于 0.2,如果图像确实移动,则相似度高于 0.4,因此让我们使用 0.3 作为收集新人脸的阈值。
我们可以使用许多技巧来获得更多的训练数据,例如使用镜像人脸、添加随机噪波、将人脸移动几个像素、按一定比例缩放人脸或将人脸旋转几度(即使我们在预处理人脸时特别尝试消除这些影响!)。 让我们将镜像的脸添加到训练集,这样我们既有更大的训练集,又减少了不对称脸的问题,或者如果用户在训练期间总是稍微向左或向右,但不是测试。 此操作如下所示:
// Only process the face if it's noticeably different from the
// previous frame and there has been a noticeable time gap.
if ((imageDiff > 0.3) && (timeDiff_seconds > 1.0)) {
// Also add the mirror image to the training set.
Mat mirroredFace;
flip(preprocessedFace, mirroredFace, 1);
// Add the face & mirrored face to the detected face lists.
preprocessedFaces.push_back(preprocessedFace);
preprocessedFaces.push_back(mirroredFace);
faceLabels.push_back(m_selectedPerson);
faceLabels.push_back(m_selectedPerson);
// Keep a copy of the processed face,
// to compare on next iteration.
old_prepreprocessedFace = preprocessedFace;
old_time = current_time;
}
这将收集预处理后的人脸的前std::vector个数组、前preprocessedFaces、前和后faceLabels数组,以及该人的标签或 ID 号(假设它在整数*m_selectedPerson变量中)。
为了让用户更明显地看到我们已经将他们的当前面孔添加到集合中,您可以通过在整个图像上显示一个大的白色矩形来提供视觉通知,或者只显示他们的面孔一小部分时间,这样他们就会意识到已经拍摄了一张照片。 有了 OpenCV 的 C++ 接口,你可以使用+重载的cv::Mat运算符为图像中的每个像素添加一个值,并将其裁剪为 255(使用saturate_cast,这样它就不会从白色溢出到黑色!)。 假设displayedFrame将是应该显示的彩色摄像机框架的副本,请在前面的人脸采集代码之后插入以下内容:
// Get access to the face region-of-interest.
Mat displayedFaceRegion = displayedFrame(faceRect);
// Add some brightness to each pixel of the face region.
displayedFaceRegion += CV_RGB(90,90,90);
从采集到的人脸训练人脸识别系统
在你收集了足够的人脸让每个人都能识别之后,你必须训练系统使用适合人脸识别的机器学习算法来学习数据。 文献中有很多不同的人脸识别算法,其中最简单的是特征脸和人工神经网络。 特征脸往往比人工神经网络工作得更好,尽管它很简单,但它的工作能力几乎与许多更复杂的人脸识别算法一样好,因此它作为初学者的基本人脸识别算法非常受欢迎,也成为新算法的比较对象。
任何希望进一步研究人脸识别的电子读者,建议阅读以下内容背后的理论:
- 特征脸(也称为主成分分析)(PCA)
- FisherFaces(也称为线性判别分析)(LDA)
- 其他经典的人脸识别算法(许多都可以在http://www.facerec.org/algorithms/上找到)
- 较新的人脸识别算法在最近的计算机视觉研究论文中(如http://www.cvpapers.com/的 CCVPR 和 ICCV),因为每年发表的人脸识别论文数以百计
然而,您不需要理解这些算法的理论就可以像本书中所示那样使用它们。 由于 OpenCV 团队和 Philipp Wagner 在libfacerec中的贡献,OpenCV v2.4.1 提供了一种简单而通用的方法,可以使用几种不同的算法中的一种(甚至可以在运行时选择)来执行人脸识别,而不必了解它们是如何实现的。 您可以使用Algorithm::getList()函数在您的 OpenCV 版本中查找可用的算法,例如使用以下代码:
vector<string> algorithms;
Algorithm::getList(algorithms);
cout << "Algorithms: " << algorithms.size() << endl;
for (auto& algorithm:algorithms) {
cout << algorithm << endl;
}
以下是 OpenCV v2.4.1 中提供的三种人脸识别算法:
FaceRecognizer.Eigenfaces:特征脸,也被称为 PCA,1991 年首次被土耳其人和宾特兰人使用FaceRecognizer.Fisherfaces渔脸,又称 LDA,由 Belhumeur、Hespanha 和 Kriegman 于 1997 年发明FaceRecognizer.LBPH:局部二进制模式直方图,由 Ahonen、Hahad 和 Pietikäinen 于 2004 年发明
More information on these face recognition algorithm implementations can be found with documentation, samples, and Python equivalents for each of them on Philipp Wagner's websites (http://bytefish.de/blog and http://bytefish.de/dev/libfacerec/).
这些新的人脸识别算法可以通过 OpenCV 的contrib模块中的FaceRecognizer类获得。 由于动态链接,您的程序可能链接到contrib模块,但实际上并未在运行时加载(如果它被认为不是必需的)。 因此,建议在尝试访问FaceRecognizer算法之前调用cv::initModule_contrib()函数。 此功能仅在 OpenCV v2.4.1 中可用,因此它还可确保您在编译时至少可以使用人脸识别算法:
// Load the "contrib" module is dynamically at runtime.
bool haveContribModule = initModule_contrib();
if (!haveContribModule) {
cerr << "ERROR: The 'contrib' module is needed for ";
cerr << "FaceRecognizer but hasn't been loaded to OpenCV!";
cerr << endl;
exit(1);
}
要使用其中一种人脸识别算法,我们必须使用cv::Algorithm::create<FaceRecognizer>()函数创建一个FaceRecognizer对象。 我们将想要作为字符串使用的人脸识别算法的名称传递给这个create函数。 这将使我们能够访问该算法(如果该算法在 OpenCV 版本中可用)。 因此,它可以用作运行时错误检查,以确保用户拥有 OpenCV v2.4.1 或更高版本。 这方面的一个示例如下所示:
string facerecAlgorithm = "FaceRecognizer.Fisherfaces";
Ptr<FaceRecognizer> model;
// Use OpenCV's new FaceRecognizer in the "contrib" module:
model = Algorithm::create<FaceRecognizer>(facerecAlgorithm);
if (model.empty()) {
cerr << "ERROR: The FaceRecognizer [" << facerecAlgorithm;
cerr << "] is not available in your version of OpenCV. ";
cerr << "Please update to OpenCV v2.4.1 or newer." << endl;
exit(1);
}
一旦我们加载了FaceRecognizer算法,我们只需使用收集的人脸数据调用FaceRecognizer::train()函数,如下所示:
// Do the actual training from the collected faces.
model->train(preprocessedFaces, faceLabels);
这一行代码将运行您选择的整个人脸识别训练算法(例如,Eogen Faces、FisherFaces 或可能的其他算法)。 如果你只有几个人的脸不到 20 张,那么这个训练应该很快就会回来,但是如果你有很多人脸多的话,可能需要几秒钟,甚至几分钟的时间,才能处理完所有的数据。
查看学到的知识
虽然没有必要,但查看人脸识别算法在学习训练数据时生成的内部数据结构非常有用,特别是如果您了解所选算法背后的理论并想要验证它是否有效,或者找出它没有如您所希望的那样工作的原因。 对于不同的算法,内部数据结构可能不同,但幸运的是,对于 Eogen Faces 和 FisherFaces,内部数据结构是相同的,所以让我们只看这两个。 它们都基于一维特征向量矩阵,在作为 2D 图像查看时,这些矩阵看起来有点像人脸;因此,通常在使用特征脸算法时将特征向量称为特征脸,或者在使用鱼脸算法时将特征向量称为 Fisherfaces。
简单地说,特征脸的基本原理是,它会计算一组特殊的图像(特征脸),以及混合比率(特征值),当它们以不同的方式组合时,可以生成训练集中的每一幅图像,但也可以用来区分训练集中的许多人脸图像。 例如,如果训练集中的一些脸有胡子,而另一些脸没有,那么至少有一个特征脸显示胡子,因此有胡子的训练脸对于该特征脸将具有较高的混合比率,以表明它们包含胡子,而没有胡子的脸对于该特征向量的混合比率将会较低。在训练集中,如果训练集中的一些脸有胡子,则至少有一个特征脸显示有胡子,因此,有胡子的训练脸对于该特征向量具有较高的混合比率,以表明它们包含胡子,而没有胡子的脸对于该特征向量具有较低的混合比率。
如果训练集有 5 个人,每个人有 20 个人脸,那么将有 100 个特征脸和特征值来区分训练集中的 100 个人脸,实际上这些将被排序,所以前几个特征脸和特征值将是最关键的区分符,而最后几个特征脸和特征值将仅仅是实际上无助于区分数据的随机像素噪声。 因此,通常的做法是丢弃一些最后的特征面,而只保留前 50 个左右的特征面。
相比之下,FisherFaces 的基本原理是不为训练集中的每幅图像计算特殊的特征向量和特征值,而是只为每个人计算一个特殊的特征向量和特征值。 因此,在上一个有 5 个人,每个人有 20 个脸的示例中,特征脸算法将使用 100 个特征脸和特征值,而 Fisherfaces 算法将只使用 5 个 Fisherface 和特征值。
要访问 Eogen Faces 和 FisherFaces 算法的内部数据结构,我们必须使用cv::Algorithm::get()函数在运行时获取它们,因为在编译时无法访问它们。 数据结构在内部用作数学计算的一部分,而不是用于图像处理,因此它们通常存储为通常介于 0.0 和 1.0 之间的浮点数,而不是范围从0到255的 8 位浮点数uchar,类似于常规图像中的像素。 此外,它们通常是 1D 行或列矩阵,或者它们构成更大矩阵的许多 1D 行或列之一。 因此,在可以显示许多这些内部数据结构之前,必须将它们重塑为正确的矩形形状,并将它们转换为介于0和255之间的 8 位*uchar像素。 由于矩阵数据的范围可能在 0.0 到 1.0 之间,或者-1.0 到 1.0 之间,或者其他任何范围,您可以使用带cv::NORM_MINMAX选项的函数来确保它输出 0 到 255 之间的数据,而不管输入范围是什么。 让我们创建一个函数来执行此重塑为矩形并转换为 8 位像素的操作,如下所示:
// Convert the matrix row or column (float matrix) to a
// rectangular 8-bit image that can be displayed or saved.
// Scales the values to be between 0 to 255\.
Mat getImageFrom1DFloatMat(const Mat matrixRow, int height)
{
// Make a rectangular shaped image instead of a single row.
Mat rectangularMat = matrixRow.reshape(1, height);
// Scale the values to be between 0 to 255 and store them
// as a regular 8-bit uchar image.
Mat dst;
normalize(rectangularMat, dst, 0, 255, NORM_MINMAX,
CV_8UC1);
return dst;
}
为了更容易调试 OpenCV 代码,在内部调试cv::Algorithm命令数据结构时,我们可以使用命令ImageUtils.cpp命令和命令ImageUtils.h命令文件轻松地显示有关命令cv::Mat命令结构的信息,如下所示:
Mat img = ...;
printMatInfo(img, "My Image");
您将在控制台上看到类似以下内容的打印内容:
My Image: 640w480h 3ch 8bpp, range[79,253][20,58][18,87]
这告诉您它是 640 个元素宽,480 个元素高(即,640 x 480 图像或 480 x 640 矩阵,取决于您如何查看它),每个像素有三个通道,每个通道 8 位(即,一个常规的 BGR 图像),并且它显示图像中每个颜色通道的最小值和最大值。
It is also possible to print the actual contents of an image or matrix by using the printMat() function instead of the printMatInfo() function. This is quite handy for viewing matrices and multichannel-float matrices, as these can be quite tricky to view for beginners.
The ImageUtils code is mostly for OpenCV's C interface, but is gradually including more of the C++ interface over time. The most recent version can be found at http://shervinemami.info/openCV.html.
平均脸部
特征脸算法和 Fisherfaces 算法都是先计算平均人脸,即所有训练图像的数学平均值,这样就可以从每幅人脸图像中减去平均图像,从而获得更好的人脸识别结果。 那么,让我们来看一下我们训练集中的平均脸部。 在特征脸模型和 Fisherfaces 实现中,平均脸被命名为mean*,如下所示:
Mat averageFace = model->get<Mat>("mean");
printMatInfo(averageFace, "averageFace (row)");
// Convert a 1D float row matrix to a regular 8-bit image.
averageFace = getImageFrom1DFloatMat(averageFace, faceHeight);
printMatInfo(averageFace, "averageFace");
imshow("averageFace", averageFace);
现在,您应该会在屏幕上看到与下面(放大)的照片类似的平均人脸图像,这是一个男人、一个女人和一个婴儿的组合。 您还应该看到控制台上显示的类似文本:
averageFace (row): 4900w1h 1ch 64bpp, range[5.21,251.47]
averageFace: 70w70h 1ch 8bpp, range[0,255]
该图像将如以下屏幕截图所示:

请注意,averageFace (row)是 64 位浮点数的单行矩阵,而averageFace是 8 位像素的矩形图像,覆盖了从 0 到 255 的整个范围
。
特征值、特征面和鱼子面
让我们来看看特征值中的实际分量和值(以文本形式),如下所示:
Mat eigenvalues = model->get<Mat>("eigenvalues");
printMat(eigenvalues, "eigenvalues");
对于特征脸,每个脸都有一个特征值表,所以如果我们有三个人,每个人有四个脸,我们就会得到一个具有 12 个特征值的列向量,从最好到最差排序如下:
eigenvalues: 1w18h 1ch 64bpp, range[4.52e+04,2.02836e+06]
2.03e+06
1.09e+06
5.23e+05
4.04e+05
2.66e+05
2.31e+05
1.85e+05
1.23e+05
9.18e+04
7.61e+04
6.91e+04
4.52e+04
对于 FisherFaces,每个额外的人只有一个特征值,所以如果有三个人,每个人有四个脸,我们只得到一个行向量,其中有两个特征值,如下所示:
eigenvalues: 2w1h 1ch 64bpp, range[152.4,316.6]
317, 152
要查看特征向量(如特征面或鱼脸图像),必须从大的特征向量矩阵中按列提取它们。 由于 OpenCV 和 C/C++ 中的数据通常以行为主的顺序存储在矩阵中,这意味着要提取一列,我们应该使用Mat::clone()函数来确保数据是连续的,否则我们不能将数据整形为矩形。 一旦我们有了一个连续的列,Mat,我们就可以使用getImageFrom1DFloatMat()*函数来显示特征向量,就像我们对平均人脸所做的那样:
// Get the eigenvectors
Mat eigenvectors = model->get<Mat>("eigenvectors");
printMatInfo(eigenvectors, "eigenvectors");
// Show the best 20 Eigenfaces
for (int i = 0; i < min(20, eigenvectors.cols); i++) {
// Create a continuous column vector from eigenvector #i.
Mat eigenvector = eigenvectors.col(i).clone();
Mat eigenface = getImageFrom1DFloatMat(eigenvector,
faceHeight);
imshow(format("Eigenface%d", i), eigenface);
}
下面的屏幕截图将特征向量显示为图像。 您可以看到,对于三个有四张脸的人,有 12 个特征脸(屏幕截图的左侧),或两个渔夫脸(屏幕截图的右侧):
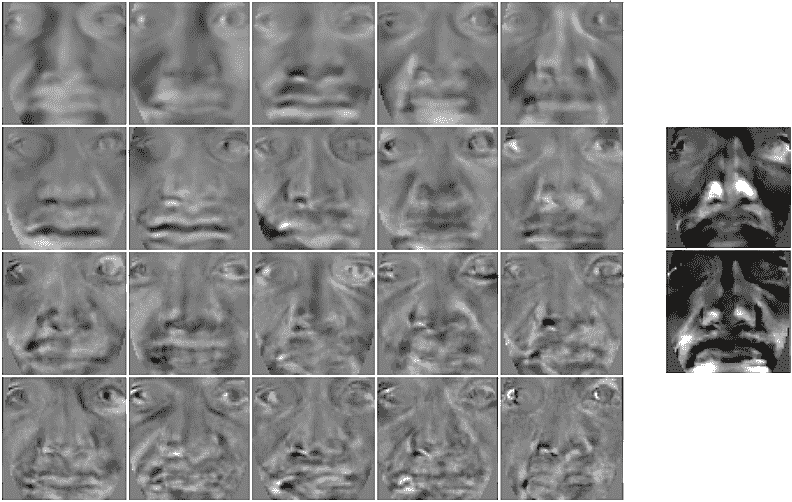
请注意,特征脸和渔夫脸看起来都与某些人脸特征相似,但它们看起来并不真的像脸。 这很简单,因为从它们中减去了平均脸,所以它们只显示了每个特征脸与平均脸的差异。 编号显示的是哪个特征面,因为它们总是从最重要的特征面到最不重要的特征面排序,如果您有 50 个或更多的特征面,那么后面的特征面通常只会显示随机的图像噪声,因此应该被丢弃。
人脸识别
现在我们已经用我们的一组训练图像和人脸标签训练了特征脸或 FisherFaces 机器学习算法,我们终于准备好从人脸图像中找出一个人是谁了! 最后一步被称为人脸识别或人脸识别。
人脸识别技术--从人脸识别人
多亏了 OpenCV 的FaceRecognizer类,我们可以简单地通过调用人脸图像
上的FaceRecognizer::predict()函数来识别照片中的人,如下所示:
int identity = model->predict(preprocessedFace);
这个identity的值将是我们最初收集人脸样本进行训练时使用的标签号,例如,第一人称为零,第二人称为一,依此类推。
这种识别的问题是,它总是能预测出某个给定的人,即使输入的照片是一个不知名的人,或者是一辆汽车。 它仍然会告诉你哪个人是照片中最有可能的人,所以很难相信结果! 解决方案是获得一个置信度度量,这样我们就可以判断结果的可靠性,如果置信度似乎太低,那么我们就假设他是一个未知的人。
人脸验证-确认这就是被认领的人
为了确认预测结果是可靠的,还是应该被认为是一个未知的人,我们执行人脸验证测试(也称为人脸认证),以获得显示单张人脸图像是否与声称的人相似的可信度度量(而不是我们刚刚执行的人脸识别,将单张人脸图像与多人进行比较)。
OpenCV 的FaceRecognizer类可以在调用predict()函数时返回置信度度量,但不幸的是,置信度度量只是基于特征子空间中的距离,因此不是很可靠。 我们将使用的方法是使用第个特征向量和第二个特征值来重建人脸图像,并将重建的图像与输入图像进行比较。 如果该人的许多人脸包括在训练集中,则根据学习的特征向量和特征值进行重建应该工作得相当好,但是如果该人在训练集中没有任何人脸(或者没有任何具有与测试图像相似的光照和人脸表情的人脸),则重建的人脸看起来将与输入人脸非常不同,这表明它可能是未知的人脸。
记住,我们在前面说过,特征脸和鱼脸算法是基于这样的概念,即图像可以粗略地表示为一组特征向量(特殊人脸图像)和特征值(混合比率)。 因此,如果我们将所有的特征向量与训练集中某个人脸的特征值相结合,那么我们应该可以得到与原始训练图像相当接近的复制品。 这同样适用于与训练集相似的其他图像;如果我们将训练的特征向量与来自相似测试图像的特征值相结合,我们应该能够重建某种程度上是测试图像的复制品的图像。
再一次,OpenCV 的FaceRecognizer类通过使用subspaceProject()函数投影到特征空间和subspaceReconstruct()函数从特征空间返回到图像空间,使得从任何输入图像生成重建脸变得非常容易。 诀窍在于,我们需要将其从浮点行矩阵转换为矩形 8 位图像(就像我们在显示平均人脸和特征脸时所做的那样),但我们不想对数据进行标准化,因为它已经处于与原始图像进行比较的理想比例。 如果对数据进行归一化处理,其亮度和对比度将与输入图像不同,仅用 L2 相对误差来比较图像的相似性将变得困难。 此操作如下所示:
// Get some required data from the FaceRecognizer model.
Mat eigenvectors = model->get<Mat>("eigenvectors");
Mat averageFaceRow = model->get<Mat>("mean");
// Project the input image onto the eigenspace.
Mat projection = subspaceProject(eigenvectors, averageFaceRow,
preprocessedFace.reshape(1,1));
// Generate the reconstructed face back from the eigenspace.
Mat reconstructionRow = subspaceReconstruct(eigenvectors,
averageFaceRow, projection);
// Make it a rectangular shaped image instead of a single row.
Mat reconstructionMat = reconstructionRow.reshape(1,
faceHeight);
// Convert the floating-point pixels to regular 8-bit uchar.
Mat reconstructedFace = Mat(reconstructionMat.size(), CV_8U);
reconstructionMat.convertTo(reconstructedFace, CV_8U, 1, 0);
下面的屏幕截图显示了两个典型的重建面。 左边的脸重建得很好,因为它来自一个已知的人,而右边的脸重建得很差,因为它来自一个未知的人,或者是一个已知的人,但光照条件/人脸表情/脸部方向未知:
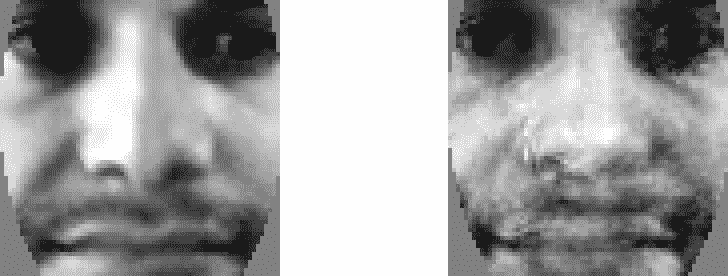
我们现在可以通过使用我们之前创建的用于比较两幅图像的getSimilarity()函数来计算这张重建的人脸与之前输入的人脸有多相似,其中小于 0.3 的值表示这两张图像非常相似。 对于本征面,每个面都有一个特征向量,因此重建效果很好,因此我们通常可以使用 0.5 的阈值,但是 Fisherfaces 对每个人只有一个特征向量,所以重建不会很好地工作,因此需要更高的阈值,比如 0.7。 此操作如下所示:
similarity = getSimilarity(preprocessedFace, reconstructedFace);
if (similarity > UNKNOWN_PERSON_THRESHOLD) {
identity = -1; // Unknown person.
}
现在,您只需将身份打印到控制台,或者在您的想象力允许的任何地方使用它! 请记住,此人脸识别方法和此人脸验证方法仅在您针对其进行培训的条件下才是可靠的。 因此,为了获得良好的识别准确性,您需要确保每个人的训练集涵盖您期望测试的所有照明条件、人脸表情和角度。 脸部预处理阶段有助于减少光照条件和面内旋转(如果人的头朝左肩或右肩倾斜)的一些差异,但对于其他差异,如面外旋转(如果人的头朝向左手边或右手边),只有在训练集中覆盖良好的情况下才能起作用。
点睛之笔-保存和加载文件
您可以添加一个基于命令行的方法来处理输入文件并将其保存到磁盘,甚至可以将人脸检测、人脸预处理和/或人脸识别作为 Web 服务来执行。 对于这些类型的项目,使用save类的save函数和load函数可以很容易地添加所需的功能。 您可能还希望保存训练过的数据,然后在程序启动时加载它。
将训练好的模型保存到 XML 或 YML 文件非常容易,如下所示:
model->save("trainedModel.yml");
如果以后要向训练集添加更多数据,则可能还需要保存预处理的面和标签的阵列。
例如,下面是一些示例代码,用于从文件加载经过训练的模型。 请注意,您必须指定最初用于创建训练模型的人脸识别算法(例如,FaceRecognizer.Eigenfaces或FaceRecognizer.Fisherfaces):
string facerecAlgorithm = "FaceRecognizer.Fisherfaces";
model = Algorithm::create<FaceRecognizer>(facerecAlgorithm);
Mat labels;
try {
model->load("trainedModel.yml");
labels = model->get<Mat>("labels");
} catch (cv::Exception &e) {}
if (labels.rows <= 0) {
cerr << "ERROR: Couldn't load trained data from "
"[trainedModel.yml]!" << endl;
exit(1);
}
画龙点睛-打造漂亮的交互式图形用户界面
虽然本章到目前为止给出的代码对于整个人脸识别系统来说已经足够了,但仍然需要一种方法来将数据输入系统并使用它。 许多用于研究的人脸识别系统会选择理想的输入为文本文件,列出静态图像文件在计算机上的存储位置,以及其他重要数据,如人的真实姓名或身份,或许还有人脸区域的真实像素坐标(如人脸和眼睛中心实际位置的基本事实)。 这可能是手动收集的,也可能是由另一个人脸识别系统收集的。
然后,理想的输出将是将识别结果与基本事实进行比较的文本文件,从而可以获得用于将人脸识别系统与其他人脸识别系统进行比较的统计数据。
然而,由于本章中的人脸识别系统是为学习和实际娱乐目的而设计的,而不是与最新的研究方法竞争,因此拥有易于使用的 GUI 是有用的,它允许从网络摄像头实时交互地进行人脸采集、培训和测试。 因此,本节将向您展示一个提供这些功能的交互式 GUI。 读者应该使用本书附带的图形用户界面,或者根据自己的目的对其进行修改,或者忽略该图形用户界面而设计自己的图形用户界面来执行到目前为止讨论的人脸识别技术。
因为我们需要 GUI 来执行多个任务,所以让我们创建一组 GUI 将具有的模式或状态,用户可以使用按钮或鼠标单击来更改模式:
- 启动:此状态加载并初始化数据和网络摄像头。
- 检测:此状态检测人脸并对其进行预处理,直到用户单击添加人员按钮。
- Collection:此状态收集当前用户的面孔,直到用户单击窗口中的任何位置。 这也显示了每个人的最新面孔。 用户单击现有人员之一或单击添加人员按钮,即可为不同的人员收集人脸。
- 训练:在这种状态下,系统在所有收集的人的所有收集的人脸的帮助下进行训练。
- 识别:这包括突出显示被识别的人并显示置信度。 用户单击其中一个人员或单击添加人员按钮返回到模式 2(集合)。
要退出,用户可以随时按窗口中的Esc键。 让我们还添加一个重新启动新的人脸识别系统的删除所有功能模式,以及一个切换显示额外调试信息的功能调试功能按钮。 我们可以创建一个枚举的mode变量来显示当前模式。
绘制 GUI 元素
为了在屏幕上显示当前模式,让我们创建一个轻松绘制文本的函数。 OpenCV 有一个cv::putText()功能,有几种字体和抗锯齿功能,但要把文本放在你想要的位置可能会很棘手。 幸运的是,还有一个用于计算文本周围边界框的函数--cv::getTextSize(),因此我们可以创建一个包装器函数,使放置文本变得更容易。
我们希望能够沿着窗口的任何边缘放置文本,确保它完全可见,并且还允许将多行或多个单词彼此相邻放置,而不会覆盖。 下面是一个包装器函数,它允许您指定左对齐或右对齐,以及指定上对齐或下对齐,并返回边界框,以便我们可以轻松地在窗口的任何角落或边缘绘制多行文本:
// Draw text into an image. Defaults to top-left-justified
// text, so give negative x coords for right-justified text,
// and/or negative y coords for bottom-justified text.
// Returns the bounding rect around the drawn text.
Rect drawString(Mat img, string text, Point coord, Scalar
color, float fontScale = 0.6f, int thickness = 1,
int fontFace = FONT_HERSHEY_COMPLEX);
现在要在 GUI 上显示当前模式,因为窗口的背景将是摄像机提要,如果我们简单地在摄像机提要上绘制文本,它很可能与摄像机背景的颜色相同! 所以,让我们只画一个黑色的文本阴影,距离我们想要绘制的前景文本只有一个像素。 我们还在下面画一条有帮助的文本线,这样用户就知道要遵循的步骤。 以下是如何使用drawString()函数绘制一些文本的示例:
string msg = "Click [Add Person] when ready to collect faces.";
// Draw it as black shadow & again as white text.
float txtSize = 0.4;
int BORDER = 10;
drawString (displayedFrame, msg, Point(BORDER, -BORDER-2),
CV_RGB(0,0,0), txtSize);
Rect rcHelp = drawString(displayedFrame, msg, Point(BORDER+1,
-BORDER-1), CV_RGB(255,255,255), txtSize);
以下部分屏幕截图显示了覆盖在摄像机图像上的 GUI 窗口底部的模式和信息:

我们提到我们需要几个 GUI 按钮,所以让我们创建一个函数来轻松绘制 GUI 按钮,如下所示:
// Draw a GUI button into the image, using drawString().
// Can give a minWidth to have several buttons of same width.
// Returns the bounding rect around the drawn button.
Rect drawButton(Mat img, string text, Point coord,
int minWidth = 0)
{
const int B = 10;
Point textCoord = Point(coord.x + B, coord.y + B);
// Get the bounding box around the text.
Rect rcText = drawString(img, text, textCoord,
CV_RGB(0,0,0));
// Draw a filled rectangle around the text.
Rect rcButton = Rect(rcText.x - B, rcText.y - B,
rcText.width + 2*B, rcText.height + 2*B);
// Set a minimum button width.
if (rcButton.width < minWidth)
rcButton.width = minWidth;
// Make a semi-transparent white rectangle.
Mat matButton = img(rcButton);
matButton += CV_RGB(90, 90, 90);
// Draw a non-transparent white border.
rectangle(img, rcButton, CV_RGB(200,200,200), 1, LINE_AA);
// Draw the actual text that will be displayed.
drawString(img, text, textCoord, CV_RGB(10,55,20));
return rcButton;
}
现在,我们使用drawButton()函数创建几个可点击的 GUI 按钮,
将始终显示在 GUI 的左上角,如下面的
部分屏幕截图所示:

正如我们提到的,GUI 程序有一些模式可以切换(作为有限状态机),从启动模式开始。 我们将当前模式存储为参数m_mode变量。
启动模式
在启动模式下,我们只需要加载 XML 检测器文件来检测人脸和眼睛,并初始化网络摄像头,这一点我们已经介绍过了。 让我们还创建一个带有鼠标回调函数的主 GUI 窗口,每当用户在窗口中移动或单击鼠标时,OpenCV 都会调用该函数。 可能还需要将相机分辨率设置为合理的值;例如,如果相机支持,则分辨率为 640 x 480。 此操作如下所示:
// Create a GUI window for display on the screen.
namedWindow(windowName);
// Call "onMouse()" when the user clicks in the window.
setMouseCallback(windowName, onMouse, 0);
// Set the camera resolution. Only works for some systems.
videoCapture.set(CAP_PROP_FRAME_WIDTH, 640);
videoCapture.set(CAP_PROP_FRAME_HEIGHT, 480);
// We're already initialized, so let's start in Detection mode.
m_mode = MODE_DETECTION;
检测模式
在检测模式中,我们想要连续检测人脸和眼睛,在它们周围画矩形或圆圈来显示检测结果,并显示当前预处理的人脸。 事实上,无论我们处于哪种模式,我们都希望显示这些内容。 检测模式唯一的特别之处在于,当用户单击添加人员按钮时,它将切换到下一个模式(集合)。
如果您还记得检测步骤,在本章中,我们检测阶段的输出如下所示:
Mat preprocessedFace:预处理的人脸(如果检测到人脸和眼睛 )Rect faceRect:检测到的人脸区域坐标Point leftEye,rightEye:检测到的左眼和右眼中心坐标
因此,我们应该检查是否返回了经过预处理的人脸,如果检测到,则在人脸和眼睛周围画一个矩形和圆圈,如下所示:
bool gotFaceAndEyes = false;
if (preprocessedFace.data)
gotFaceAndEyes = true;
if (faceRect.width > 0) {
// Draw an anti-aliased rectangle around the detected face.
rectangle(displayedFrame, faceRect, CV_RGB(255, 255, 0), 2,
CV_AA);
// Draw light-blue anti-aliased circles for the 2 eyes.
Scalar eyeColor = CV_RGB(0,255,255);
if (leftEye.x >= 0) { // Check if the eye was detected
circle(displayedFrame, Point(faceRect.x + leftEye.x,
faceRect.y + leftEye.y), 6, eyeColor, 1, LINE_AA);
}
if (rightEye.x >= 0) { // Check if the eye was detected
circle(displayedFrame, Point(faceRect.x + rightEye.x,
faceRect.y + rightEye.y), 6, eyeColor, 1, LINE_AA);
}
}
我们将在窗口的顶部中心覆盖当前预处理的面,如下所示:
int cx = (displayedFrame.cols - faceWidth) / 2;
if (preprocessedFace.data) {
// Get a BGR version of the face, since the output is BGR.
Mat srcBGR = Mat(preprocessedFace.size(), CV_8UC3);
cvtColor(preprocessedFace, srcBGR, COLOR_GRAY2BGR);
// Get the destination ROI.
Rect dstRC = Rect(cx, BORDER, faceWidth, faceHeight);
Mat dstROI = displayedFrame(dstRC);
// Copy the pixels from src to dst.
srcBGR.copyTo(dstROI);
}
// Draw an anti-aliased border around the face.
rectangle(displayedFrame, Rect(cx-1, BORDER-1, faceWidth+2,
faceHeight+2), CV_RGB(200,200,200), 1, LINE_AA);
下面的屏幕截图显示了在检测模式下显示的 GUI。 预处理后的人脸显示在上方中心,并标记检测到的人脸和眼睛:

采集模式
当用户单击“添加人”按钮以表示他们想要开始为新的人收集面孔时,我们进入收集模式。 如前所述,我们将面集合限制为每秒一个面,然后仅当它与之前收集的面有明显变化时才进行。 记住,我们决定不仅要收集经过预处理的人脸,还要收集经过预处理的人脸的镜像。
在集合模式中,我们希望显示每个已知人员的最新面孔,并让用户单击其中一个人向其添加更多面孔,或单击添加人员按钮将新的人员添加到集合中。 用户必须单击窗口中间的某个位置才能继续进入下一模式(培训模式)。
因此,首先我们需要参考为每个人收集的最新面孔。 我们将通过更新整数的前m_latestFaces数组来实现这一点,该数组只存储来自大的前preprocessedFaces前数组的每个人的数组索引(即所有人的所有面孔的集合)。 由于我们还将镜像面存储在该数组中,因此我们希望引用倒数第二个面,而不是最后一个面。 此代码应附加到将新面(和镜像面)添加到第一preprocessedFaces数组的代码中:
// Keep a reference to the latest face of each person.
m_latestFaces[m_selectedPerson] = preprocessedFaces.size() - 2;
我们只需记住,无论何时添加或删除新的人员(例如,由于用户单击了添加人员按钮),都要始终扩大或缩小m_latestFaces成员数组。 现在,让我们在窗口的右侧(稍后在收集模式和识别模式下)显示每个收集到的人的最新面孔,如下所示:
m_gui_faces_left = displayedFrame.cols - BORDER - faceWidth;
m_gui_faces_top = BORDER;
for (int i=0; i<m_numPersons; i++) {
int index = m_latestFaces[i];
if (index >= 0 && index < (int)preprocessedFaces.size()) {
Mat srcGray = preprocessedFaces[index];
if (srcGray.data) {
// Get a BGR face, since the output is BGR.
Mat srcBGR = Mat(srcGray.size(), CV_8UC3);
cvtColor(srcGray, srcBGR, COLOR_GRAY2BGR);
// Get the destination ROI
int y = min(m_gui_faces_top + i * faceHeight,
displayedFrame.rows - faceHeight);
Rect dstRC = Rect(m_gui_faces_left, y, faceWidth,
faceHeight);
Mat dstROI = displayedFrame(dstRC);
// Copy the pixels from src to dst.
srcBGR.copyTo(dstROI);
}
}
}
我们还希望突出显示当前正在收集的人员,在他们的人脸周围使用粗红色边框。 此操作如下所示:
if (m_mode == MODE_COLLECT_FACES) {
if (m_selectedPerson >= 0 &&
m_selectedPerson < m_numPersons) {
int y = min(m_gui_faces_top + m_selectedPerson *
faceHeight, displayedFrame.rows - faceHeight);
Rect rc = Rect(m_gui_faces_left, y, faceWidth, faceHeight);
rectangle(displayedFrame, rc, CV_RGB(255,0,0), 3, LINE_AA);
}
}
下面的部分屏幕截图显示了收集了几个人的面孔时的典型显示。 用户可以点击右上角的任何一个人来收集该人的更多面孔:

培训模式
当用户最终点击窗口中间时,人脸识别算法将开始对所有收集到的人脸进行训练。 但重要的是要确保收集到足够的面孔或人,否则程序可能会崩溃。 一般来说,这只需要确保训练集中至少有一张脸(这意味着至少有一个人)。 但 FisherFaces 算法寻找人与人之间的比较,因此如果训练集中的人少于两人,它也会崩溃。 因此,我们必须检查所选的人脸识别算法是否为 FisherFaces。 如果是,那么我们至少需要两个有脸的人,否则我们需要至少有一个有脸的人。 如果没有足够的数据,程序将返回到收集模式,以便用户可以在训练前添加更多人脸。
为了检查是否至少有两个人具有收集到的人脸,我们可以确保当用户点击添加人按钮时,只有在没有任何空的人(即添加了但还没有任何收集到的脸的人)的情况下才会添加一个新的人。 如果只有两个人,并且我们使用的是 Fisherfaces 算法,那么我们必须确保在收集模式期间为最后一个人设置了m_latestFaces引用。 然后,当仍然没有向该人添加任何面孔时,将其初始化为-1,一旦添加了该人的面孔,它将变为0或更高。 此操作如下所示:
// Check if there is enough data to train from.
bool haveEnoughData = true;
if (!strcmp(facerecAlgorithm, "FaceRecognizer.Fisherfaces")) {
if ((m_numPersons < 2) ||
(m_numPersons == 2 && m_latestFaces[1] < 0) ) {
cout << "Fisherfaces needs >= 2 people!" << endl;
haveEnoughData = false;
}
}
if (m_numPersons < 1 || preprocessedFaces.size() <= 0 ||
preprocessedFaces.size() != faceLabels.size()) {
cout << "Need data before it can be learnt!" << endl;
haveEnoughData = false;
}
if (haveEnoughData) {
// Train collected faces using Eigenfaces or Fisherfaces.
model = learnCollectedFaces(preprocessedFaces, faceLabels,
facerecAlgorithm);
// Now that training is over, we can start recognizing!
m_mode = MODE_RECOGNITION;
}
else {
// Not enough training data, go back to Collection mode!
m_mode = MODE_COLLECT_FACES;
}
培训可能需要几分之一秒,也可能需要几秒钟甚至几分钟,具体取决于收集的数据量。 一旦采集到的人脸训练完成,人脸识别系统将自动进入下识别模式。
识别模式
在识别模式下,预处理后的人脸旁边会显示一个置信度,这样用户就可以知道识别的可靠性有多高。 如果置信度高于未知阈值,则会在识别的人周围画一个绿色矩形,以方便显示结果。 如果用户点击添加人员按钮或现有人员之一,可以添加更多面孔进行进一步培训,这会导致程序返回到集合模式。
现在,我们已经获得了识别的身份和与重建的人脸的相似性,如前所述。 为了显示置信度,我们知道对于高置信度,L2 相似性值通常在 0 到 0.5 之间,对于低置信度,L2 相似性值通常在 0.5 到 1.0 之间,所以我们可以从 1.0 中减去它,得到 0.0 到 1.0 之间的置信度级别。
然后,我们只需使用置信度作为比率绘制一个填充矩形,如下图所示:
int cx = (displayedFrame.cols - faceWidth) / 2;
Point ptBottomRight = Point(cx - 5, BORDER + faceHeight);
Point ptTopLeft = Point(cx - 15, BORDER);
// Draw a gray line showing the threshold for "unknown" people.
Point ptThreshold = Point(ptTopLeft.x, ptBottomRight.y -
(1.0 - UNKNOWN_PERSON_THRESHOLD) * faceHeight);
rectangle(displayedFrame, ptThreshold, Point(ptBottomRight.x,
ptThreshold.y), CV_RGB(200,200,200), 1, CV_AA);
// Crop the confidence rating between 0 to 1 to fit in the bar.
double confidenceRatio = 1.0 - min(max(similarity, 0.0), 1.0);
Point ptConfidence = Point(ptTopLeft.x, ptBottomRight.y -
confidenceRatio * faceHeight);
// Show the light-blue confidence bar.
rectangle(displayedFrame, ptConfidence, ptBottomRight,
CV_RGB(0,255,255), CV_FILLED, CV_AA);
// Show the gray border of the bar.
rectangle(displayedFrame, ptTopLeft, ptBottomRight,
CV_RGB(200,200,200), 1, CV_AA);
为了突出显示被识别的人,我们在他们的脸部周围画了一个绿色矩形,如下所示:
if (identity >= 0 && identity < 1000) {
int y = min(m_gui_faces_top + identity * faceHeight,
displayedFrame.rows - faceHeight);
Rect rc = Rect(m_gui_faces_left, y, faceWidth, faceHeight);
rectangle(displayedFrame, rc, CV_RGB(0,255,0), 3, CV_AA);
}
以下部分屏幕截图显示了在识别模式下运行时的典型显示,在顶部中心显示了预处理后的人脸旁边的置信度测量仪,并在右上角突出显示了被识别的人:

检查和处理鼠标点击
现在我们已经绘制了所有的 GUI 元素,我们需要处理鼠标事件。 当我们初始化显示窗口时,我们告诉 OpenCV 我们想要一个对我们的onMouse函数的鼠标事件回调。
我们不关心鼠标移动,只关心鼠标单击,因此首先跳过不是鼠标左键单击的鼠标事件,如下所示:
void onMouse(int event, int x, int y, int, void*)
{
if (event != CV_EVENT_LBUTTONDOWN)
return;
Point pt = Point(x,y);
... (handle mouse clicks)
...
}
因为我们在绘制按钮时获得了绘制的矩形边界,所以我们只需通过调用 OpenCV 的inside()函数来检查鼠标单击位置是否在我们的任何按钮区域中。 现在,我们可以检查我们创建的每个按钮。
当用户单击“Add Person”按钮时,我们会向第一个m_numPersons个变量添加一个,在第二个m_latestFaces个变量中分配更多空间,选择要收集的新人员,然后开始收集模式(无论我们之前处于哪种模式)。
但有一个复杂的问题:为了确保训练时每个人至少有一张脸,我们只会在没有面孔为零的人的情况下为新人分配空间。 这将确保我们始终可以检查m_latestFaces[m_numPersons-1]的值,看看是否为每个人收集了一张脸。 此操作如下所示:
if (pt.inside(m_btnAddPerson)) {
// Ensure there isn't a person without collected faces.
if ((m_numPersons==0) ||
(m_latestFaces[m_numPersons-1] >= 0)) {
// Add a new person.
m_numPersons++ ;
m_latestFaces.push_back(-1);
}
m_selectedPerson = m_numPersons - 1;
m_mode = MODE_COLLECT_FACES;
}
此方法可用于测试是否有其他按钮单击,例如切换调试标志,如下所示:
else if (pt.inside(m_btnDebug)) {
m_debug = !m_debug;
}
要处理 Delete All 按钮,我们需要清空主循环本地的各种数据结构(即,无法从鼠标事件回调函数访问),因此我们切换到 Delete All 模式,然后可以从主循环中删除所有内容。 我们还必须处理用户单击主窗口(即,不是按钮)的问题。 如果他们单击右侧的某个人员,则我们希望选择该人员并切换到收集模式。 或者,如果他们在收集模式下单击主窗口,则我们希望切换到培训模式。 此操作如下所示:
else {
// Check if the user clicked on a face from the list.
int clickedPerson = -1;
for (int i=0; i<m_numPersons; i++) {
if (m_gui_faces_top >= 0) {
Rect rcFace = Rect(m_gui_faces_left,
m_gui_faces_top + i * faceHeight, faceWidth, faceHeight);
if (pt.inside(rcFace)) {
clickedPerson = i;
break;
}
}
}
// Change the selected person, if the user clicked a face.
if (clickedPerson >= 0) {
// Change the current person & collect more photos.
m_selectedPerson = clickedPerson;
m_mode = MODE_COLLECT_FACES;
}
// Otherwise they clicked in the center.
else {
// Change to training mode if it was collecting faces.
if (m_mode == MODE_COLLECT_FACES) {
m_mode = MODE_TRAINING;
}
}
}
简略的 / 概括的 / 简易判罪的 / 简易的
本章已经向您展示了创建实时人脸识别应用所需的所有步骤,并且只需使用基本算法,就可以进行足够的预处理,以允许训练集条件和测试集条件之间存在一些差异。 我们使用人脸检测来找出人脸在相机图像中的位置,然后进行几种形式的人脸预处理,以减少不同光照条件、相机和人脸方向以及人脸表情的影响。
然后,我们用采集到的经过预处理的人脸训练特征脸或 FisherFaces 机器学习系统,最后进行人脸识别,以确定进行人脸验证的人是谁,并提供一个置信度度量,以防是未知的人。
我们没有提供以离线方式处理图像文件的命令行工具,而是将上述所有步骤结合到一个独立的实时 GUI 程序中,以允许立即使用人脸识别系统。 您应该能够根据自己的目的修改系统的行为,例如允许自动登录到您的计算机上,或者如果您对提高识别可靠性感兴趣,那么您可以阅读有关人脸识别的最新进展的会议论文,以潜在地改进程序的每一步,直到它足够可靠,以满足您的特定需求。 例如,基于http://www.facerec.org/algorithms/和http://www.cvpapers.com的方法,您可以改进人脸预处理阶段,或者使用更先进的机器学习算法,或者更好的人脸验证算法。
参考文献
- 使用简单特征的增强级联的快速目标检测,P.Viola 和 M.J.Jones,IEEE 关于 CVPR 2001,第 1 卷, 第 511-518 页的论文集,第 1 卷, 第 511-518 页,第 1 卷, 第 511-518 页
- 一组扩展的用于快速目标检测的类 Haar 特征,R.Lienhart 和 J.Maydt,ICIP 2002 年 IEEE 会议论文集,第 1 卷,第 900-903 页
- 使用局部二值模式的人脸描述:在人脸识别中的应用,T.Ahonen,A.Hahad 和 M.Pietikäinen,IEEE Pami 2006 论文集,第 28 卷,第 12 期,第 2037-2041 页
- 学习 OpenCV:使用 OpenCV 库的计算机视觉,G.Bradski 和 A.Kaehler,第 186-190 页,O‘Reilly Media。
- 用于识别的特征脸,M.Turk 和 A.Pentland,认知神经科学杂志 3,第 71-86 页
- 特征脸与渔夫脸:使用类特定线性投影的识别,P.N.Belhumeur,J.Hespanha 和 D.Kriegman,IEEE 关于 Pami 1997 的会议论文集,第 19 卷,问题 7,第 711-720 页,Pami 1997,第 19 卷,问题 7,第 711-720 页
- 基于局部二值模式的人脸识别,T.Ahonen,A.Hahad 和 M.Pietikäinen,计算机视觉-ECCV 2004,第 469-48 页
