七、检测人脸部位和覆盖面具
在第 6 章和学习对象分类中,我们了解了对象分类以及如何使用机器学习来实现对象分类。 在本章中,我们将学习如何检测和跟踪不同的人脸部位。 我们将从了解人脸检测管道及其构建方式开始讨论。 然后,我们将使用此框架来检测人脸部分,如眼睛、耳朵、嘴巴和鼻子。 最后,我们将学习如何在直播视频中将有趣的面具覆盖在这些人脸部位上。
学完本章后,我们应该熟悉以下主题:
- 了解哈尔叶栅
- 整体图像以及我们为什么需要它们
- 构建通用人脸检测流水线
- 检测和跟踪来自网络摄像头的实时视频流中的人脸、眼睛、耳朵、鼻子和嘴巴
- 在视频中自动将口罩、太阳镜和滑稽的鼻子叠加在人的脸上
技术要求
本章要求基本熟悉 C++ 编程语言。 本章中使用的所有代码都可以从以下 gihub 链接下载:https://github.com/PacktPublishing/Building-Computer-Vision-Projects-with-OpenCV4-and-CPlusPlus/tree/master/Chapter07。这些代码可以在任何操作系统上执行,尽管它只在 Ubuntu 上测试过。
请查看以下视频,了解实际操作中的代码: http://bit.ly/2SlpTK6
了解哈尔叶栅
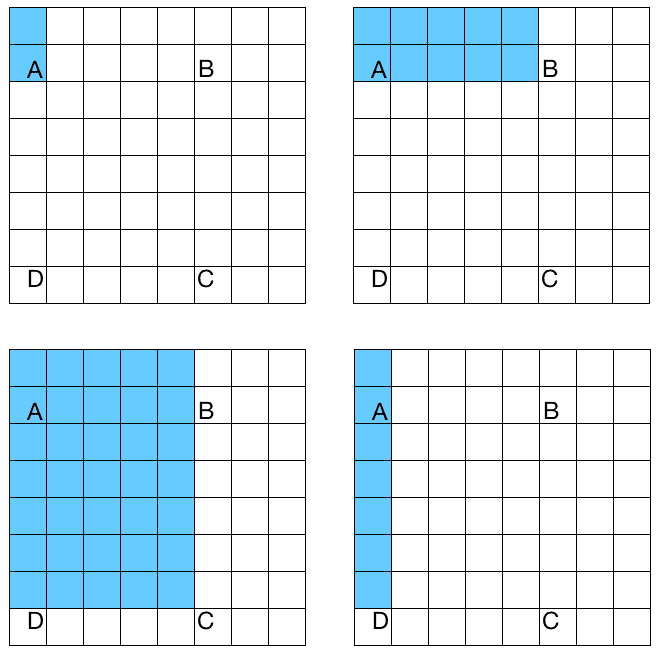
Haar 级联是基于 Haar 特征的级联分类器。 什么是级联分级机? 它只是一组可用于创建强分类器的弱分类器的串联。 我们所说的弱和强分类器是什么意思? 弱分类器是性能有限的分类器。 他们没有能力正确地对所有东西进行分类。 如果你让问题变得非常简单,他们可能会表现在可以接受的水平。 另一方面,强分类器非常擅长对我们的数据进行正确的分类。 在接下来的几个段落中,我们将看到这一切是如何结合在一起的。 Haar 级联的另一个重要部分是Haar 特性。 这些特征是矩形和图像上这些区域的差异的简单总和。 让我们考虑下图:
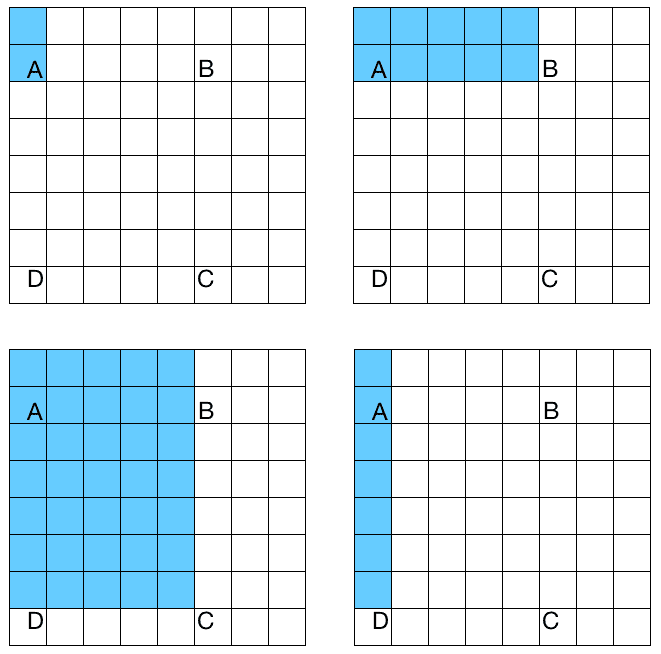
如果要计算 ABCD 区域的 Haar 特征,只需计算该区域的白色像素和蓝色像素之间的差值。 正如我们从这四个图中看到的,我们使用不同的模式来构建 Haar 特性。 还有很多其他的模式也在使用。 我们在多个尺度上这样做,以使系统尺度不变。 当我们说多个比例时,我们只是缩小图像以再次计算相同的特征。 这样,我们就可以使其对给定对象的大小变化具有健壮性。
As it turns out, this concatenation system is a very good method for detecting objects in an image. In 2001, Paul Viola and Michael Jones published a seminal paper where they described a fast and effective method for object detection. If you are interested in learning more about it, you can check out their paper at http://www.cs.ubc.ca/~lowe/425/slides/13-ViolaJones.pdf.
让我们更深入地了解他们到底做了什么。 他们基本上描述了一种使用增强型简单分类器级联的算法。 这个系统被用来构建一个性能非常好的强大分类器。 为什么他们用这些简单的量词,而不是复杂的量词,因为复杂的量词可以更准确? 嗯,使用这项技术,他们能够避免必须建立一个可以高精度执行的单一分类器的问题。 这些单步分类器往往比较复杂且计算密集。 他们的技术如此有效的原因是因为简单的量词可能是较弱的学习者,这意味着他们不需要变得复杂。 考虑构建表检测器的问题。 我们想要构建一个系统,该系统将自动学习表格的外观。 基于这些知识,它应该能够识别在任何给定图像中是否有表。 要建立这个系统,第一步是收集图像,这些图像可以用来训练我们的系统。 在机器学习领域,有很多技术可以用来训练这样的系统。 请记住,如果我们希望我们的系统运行良好,我们需要收集大量的表格和非表格图像。 在机器学习术语中,表格图像称为正样本,非表格图像称为负样本。 我们的系统将摄取这些数据,然后学习区分这两个类别。为了建立一个实时系统,我们需要保持分类器的精致和简单。 唯一令人担忧的是,简单的分类器不是很准确。 如果我们试图使它们更准确,那么这个过程最终将是计算密集型的,因此速度很慢。 这种精度和速度之间的权衡在机器学习中非常常见。 因此,我们通过连接一组弱分类器来创建一个强而统一的分类器来克服这个问题。 我们不需要弱分类器非常准确。 为了确保整体分类器的质量,Viola 和 Jones 在级联步骤中描述了一种巧妙的技术。 你可以通读这篇论文来了解整个系统。
现在我们已经了解了一般流程,让我们看看如何构建一个可以在实时视频中检测人脸的系统。 第一步是从所有图像中提取特征。 在这种情况下,算法需要这些功能来学习和理解人脸的样子。 他们在论文中使用了 Haar 特征来构建特征向量。 一旦我们提取了这些特征,我们就将它们通过一系列分类器。 我们只检查所有不同的矩形子区域,并不断丢弃其中没有人脸的区域。 这样,我们就可以快速得到最终答案,看看给定的矩形是否包含人脸。
什么是整体图像?
为了提取这些 Haar 特征,我们必须计算包含在图像的许多矩形区域中的像素值的总和。 为了使其具有比例不变性,我们需要在多个比例下计算这些面积(对于不同的矩形大小)。 如果实现得很幼稚,这将是一个计算非常密集的过程;因为我们将不得不迭代每个矩形的所有像素,包括多次读取相同的像素(如果它们包含在不同的重叠矩形中)。 如果你想构建一个可以实时运行的系统,你不能在计算上花费这么多时间。 在面积计算过程中,我们需要找到一种方法来避免这种巨大的冗余,因为我们在相同的像素上迭代了多次。 为了避免这种情况,我们可以使用一种叫做积分图像的东西。 这些图像可以在线性时间初始化(通过在图像上仅迭代两次),然后通过仅读取四个值来提供任意大小的任意矩形内的像素总和。 为了更好地理解它,我们来看下图:
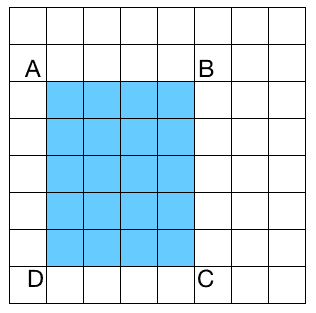
如果我们想要计算图表中任何矩形的面积,我们不必遍历该区域中的所有像素。 让我们考虑一个由图像中左上角的点和任意点 P 组成的矩形作为对角点。 设 AP表示该矩形的面积。 例如,在上图中,AB表示将左上点和B作为对角点形成的 5x2 矩形的面积。 为了清楚起见,让我们看一下下图:
让我们考虑一下上图中的左上角正方形。 蓝色像素表示左上角像素和点A之间的区域。 这由 AA表示。 其余的图表由各自的名称表示:AB、AC和 AD。 现在,如果我们要计算矩形的面积,如上图所示,我们将使用以下公式:
矩形面积:ABCD=AC-(AB+AD-AA)
这个特别的配方有什么特别之处? 众所周知,从图像中提取 Haar 特征包括计算这些求和,我们将不得不对图像中许多不同尺度的矩形进行求和。 很多这样的计算都是重复的,因为我们会一遍又一遍地重复相同的像素。 速度如此之慢,以至于建立一个实时系统是不可行的。 因此,我们需要这个公式。 如您所见,我们不必多次迭代相同的像素。 如果我们要计算任何矩形的面积,前面公式右侧的所有值在积分图像中都很容易得到。 我们只需选取正确的值,将它们替换到前面的方程式中,然后提取特征即可。
在直播视频中叠加口罩
OpenCV 提供了一个很好的人脸检测框架。 我们只需要加载级联文件,并使用它来检测图像中的人脸。 当我们从网络摄像头捕捉到视频流时,我们可以将滑稽的面具覆盖在我们的脸上。 它看起来如下所示:

让我们看一下代码的主要部分,看看如何在输入视频流的人脸覆盖这个蒙版。 在随本书提供的可下载代码包中提供了完整的代码:
#include "opencv2/core/utility.hpp"
#include "opencv2/objdetect/objdetect.hpp"
#include "opencv2/imgproc.hpp"
#include "opencv2/highgui.hpp"
using namespace cv;
using namespace std;
...
int main(int argc, char* argv[])
{
string faceCascadeName = argv[1];
// Variable declaration and initialization
...
// Iterate until the user presses the Esc key
while(true)
{
// Capture the current frame
cap >> frame;
// Resize the frame
resize(frame, frame, Size(), scalingFactor, scalingFactor, INTER_AREA);
// Convert to grayscale
cvtColor(frame, frameGray, COLOR_BGR2GRAY);
// Equalize the histogram
equalizeHist(frameGray, frameGray);
// Detect faces
faceCascade.detectMultiScale(frameGray, faces, 1.1, 2, 0|HAAR_SCALE_IMAGE, Size(30, 30) );
让我们停下来看看这里发生了什么。 我们开始读取网络摄像头的输入帧,并根据我们选择的大小调整它的大小。 捕获的帧是彩色图像,人脸检测工作在灰度图像上进行。 因此,我们将其转换为灰度并均衡直方图。 为什么我们需要使直方图均衡? 我们需要这样做,以补偿任何问题,如照明或饱和度。 如果图像太亮或太暗,检测效果会很差。 因此,我们需要均衡直方图,以确保我们的图像具有健康的像素值范围:
// Draw green rectangle around the face
for(auto& face:faces)
{
Rect faceRect(face.x, face.y, face.width, face.height);
// Custom parameters to make the mask fit your face. You may have to play around with them to make sure it works.
int x = face.x - int(0.1*face.width);
int y = face.y - int(0.0*face.height);
int w = int(1.1 * face.width);
int h = int(1.3 * face.height);
// Extract region of interest (ROI) covering your face
frameROI = frame(Rect(x,y,w,h));
在这一点上,我们知道脸在哪里了。 因此,我们提取感兴趣的区域以在正确的位置覆盖蒙版:
// Resize the face mask image based on the dimensions of the above ROI
resize(faceMask, faceMaskSmall, Size(w,h));
// Convert the previous image to grayscale
cvtColor(faceMaskSmall, grayMaskSmall, COLOR_BGR2GRAY);
// Threshold the previous image to isolate the pixels associated only with the face mask
threshold(grayMaskSmall, grayMaskSmallThresh, 230, 255, THRESH_BINARY_INV);
我们分离出与面罩相关的像素。 我们希望以这样一种方式覆盖蒙版,使其看起来不像一个矩形。 我们希望得到覆盖对象的精确边界,以便它看起来很自然。 现在让我们继续覆盖面具:
// Create mask by inverting the previous image (because we don't want the background to affect the overlay)
bitwise_not(grayMaskSmallThresh, grayMaskSmallThreshInv);
// Use bitwise "AND" operator to extract precise boundary of face mask
bitwise_and(faceMaskSmall, faceMaskSmall, maskedFace, grayMaskSmallThresh);
// Use bitwise "AND" operator to overlay face mask
bitwise_and(frameROI, frameROI, maskedFrame, grayMaskSmallThreshInv);
// Add the previously masked images and place it in the original frame ROI to create the final image
add(maskedFace, maskedFrame, frame(Rect(x,y,w,h)));
}
// code dealing with memory release and GUI
return 1;
}
代码里发生了什么?
首先要注意的是,这段代码有两个输入参数-face ascade XML文件和掩码图像。 您可以使用resources文件夹下提供的haarcascade_frontalface_alt.xml和facemask.jpg文件。 我们需要一个可用于检测图像中人脸的分类器模型,OpenCV 提供了一个可用于此目的的预构建 XML 文件。 我们使用faceCascade.load()函数加载 XML 文件,并检查文件是否加载正确。 我们启动视频捕获对象来捕获来自网络摄像头的输入帧。 然后我们将其转换为灰度以运行检测器。 函数的作用是提取输入图像中所有人脸的边界。 我们可能需要根据需要缩小图像,因此此函数中的第二个参数可以解决这一问题。 此比例因子是我们在每个比例下进行的跳跃;由于我们需要在多个比例下查找面,因此下一个大小将是当前大小的 1.1 倍。 最后一个参数是阈值,它指定保留当前矩形所需的相邻矩形的数量。 它可以用来增加人脸检测器的鲁棒性。 我们开始while循环,并在每一帧中持续检测人脸,直到用户按下Esc键。 一旦我们检测到一张脸,我们需要在它上面覆盖一个面具。 我们可能需要稍微修改一下尺寸,以确保面罩合身。 此自定义稍有主观性,它取决于所使用的遮罩。 现在我们已经提取了感兴趣的区域,我们需要将遮罩放置在该区域的顶部。 如果我们用白色背景覆盖面具,它看起来会很奇怪。 我们必须提取蒙版的精确曲线边界,然后将其覆盖。 我们希望头骨蒙版像素是可见的,其余区域应该是透明的。
正如我们所看到的,输入掩码的背景是白色的。 因此,我们通过对蒙版图像应用阈值来创建蒙版。 使用试错法,我们可以看到阈值240运行良好。 在图像中,强度值大于240的所有像素将变为0,所有其他像素将变为255。 就感兴趣的区域而言,我们必须将该区域内的所有像素都涂黑。 要做到这一点,我们只需使用刚刚创建的蒙版的反面。 在最后一步中,我们只需添加掩码版本即可生成最终输出图像。
戴上你的太阳镜
既然我们了解了如何检测人脸,我们就可以将这个概念推广到检测人脸的不同部位。 我们将在直播视频中使用眼睛探测器覆盖太阳镜。 重要的是要理解 Viola-Jones 框架可以应用于任何对象。 准确性和健壮性将取决于对象的唯一性。 例如,人脸有非常独特的特征,所以很容易训练我们的系统变得健壮。 另一方面,像毛巾这样的物体太通用了,没有明显的特征,所以很难构建一个健壮的毛巾检测器。 一旦你建造了眼睛探测器并覆盖了眼镜,它看起来就像这样:

让我们看一下代码的主要部分:
...
int main(int argc, char* argv[])
{
string faceCascadeName = argv[1];
string eyeCascadeName = argv[2];
// Variable declaration and initialization
....
// Face detection code
....
vector<Point> centers;
....
// Draw green circles around the eyes
for( auto& face:faces )
{
Mat faceROI = frameGray(face[i]);
vector<Rect> eyes;
// In each face, detect eyes eyeCascade.detectMultiScale(faceROI, eyes, 1.1, 2, 0 |CV_HAAR_SCALE_IMAGE, Size(30, 30));
正如我们在这里看到的,我们只在脸部区域运行眼睛检测器。 我们不需要在整张图片中搜索眼睛,因为我们知道眼睛总是在一张脸上:
// For each eye detected, compute the center
for(auto& eyes:eyes)
{
Point center( face.x + eye.x + int(eye.width*0.5), face.y + eye.y + int(eye.height*0.5) );
centers.push_back(center);
}
}
// Overlay sunglasses only if both eyes are detected
if(centers.size() == 2)
{
Point leftPoint, rightPoint;
// Identify the left and right eyes
if(centers[0].x < centers[1].x)
{
leftPoint = centers[0];
rightPoint = centers[1];
}
else
{
leftPoint = centers[1];
rightPoint = centers[0];
}
只有当我们找到这两只眼睛时,我们才能探测到它们并将它们储存起来。 然后我们使用它们的坐标来确定哪个是左眼,哪个是右眼:
// Custom parameters to make the sunglasses fit your face. You may have to play around with them to make sure it works.
int w = 2.3 * (rightPoint.x - leftPoint.x);
int h = int(0.4 * w);
int x = leftPoint.x - 0.25*w;
int y = leftPoint.y - 0.5*h;
// Extract region of interest (ROI) covering both the eyes
frameROI = frame(Rect(x,y,w,h));
// Resize the sunglasses image based on the dimensions of the above ROI
resize(eyeMask, eyeMaskSmall, Size(w,h));
在前面的代码中,我们调整了太阳镜的大小,以适应网络摄像头上我们的脸的比例。 让我们检查一下剩余的代码:
// Convert the previous image to grayscale
cvtColor(eyeMaskSmall, grayMaskSmall, COLOR_BGR2GRAY);
// Threshold the previous image to isolate the foreground object
threshold(grayMaskSmall, grayMaskSmallThresh, 245, 255, THRESH_BINARY_INV);
// Create mask by inverting the previous image (because we don't want the background to affect the overlay)
bitwise_not(grayMaskSmallThresh, grayMaskSmallThreshInv);
// Use bitwise "AND" operator to extract precise boundary of sunglasses
bitwise_and(eyeMaskSmall, eyeMaskSmall, maskedEye, grayMaskSmallThresh);
// Use bitwise "AND" operator to overlay sunglasses
bitwise_and(frameROI, frameROI, maskedFrame, grayMaskSmallThreshInv);
// Add the previously masked images and place it in the original frame ROI to create the final image
add(maskedEye, maskedFrame, frame(Rect(x,y,w,h)));
}
// code for memory release and GUI
return 1;
}
查看代码内部
您可能已经注意到,代码流看起来与我们在直播视频中的覆盖面膜部分中讨论的人脸检测代码类似。 我们加载了人脸检测级联分类器和眼睛检测级联分类器。 那么,为什么我们在检测眼睛的时候需要加载人脸级联分类器呢? 嗯,我们并不真的需要使用人脸检测器,但它可以帮助我们限制对眼睛位置的搜索。 我们知道眼睛总是位于某人的脸上,所以我们可以将眼睛检测限制在人脸区域。 第一步是检测脸部,然后在这个区域运行我们的眼睛探测器代码。 由于我们将在较小的地区开展业务,因此速度会更快,效率也会更高。
对于每一帧,我们从检测人脸开始。 然后我们继续对这个区域进行手术来检测眼睛的位置。 在这一步之后,我们需要覆盖太阳镜。 要做到这一点,我们需要调整太阳镜图像的大小,以确保它适合我们的脸。 为了获得合适的比例,我们可以考虑被检测的两只眼睛之间的距离。 只有当我们察觉到两只眼睛时,我们才会戴上太阳镜。 这就是为什么我们首先运行眼睛探测器,收集所有的中心,然后覆盖太阳镜。 一旦我们有了这个,我们只需要盖上太阳镜面具。 用于遮罩的原理与我们用于覆盖面膜的原理非常相似。 您可能需要定制太阳镜的大小和位置,具体取决于您想要的。 你可以玩不同类型的太阳镜,看看它们是什么样子。
跟踪鼻子、嘴巴和耳朵
既然您知道了如何使用该框架跟踪不同的东西,那么您也可以尝试跟踪您的鼻子、嘴巴和耳朵了。 让我们用鼻子探测器覆盖一个滑稽的鼻子:

您可以参考代码文件了解该检测器的完整实现。 haarcascade_mcs_nose.xml、haarcascade_mcs_mouth.xml、haarcascade_mcs_leftear.xml和haarcascade_mcs_rightear.xml级联文件可用于跟踪不同的人脸分。 和他们一起玩耍,试着把胡子或德古拉耳朵盖在自己身上。
简略的 / 概括的 / 简易判罪的 / 简易的
在这一章中,我们讨论了 Haar 级联和积分像。 我们了解了人脸检测管道是如何构建的。 我们学习了如何检测和跟踪实时视频流中的人脸。 我们讨论了使用人脸检测框架来检测各种人脸部位,如眼睛、耳朵、鼻子和嘴巴。 最后,我们学习了如何利用人脸部分检测的结果在输入图像上叠加蒙版。
在下一章中,我们将学习视频监控、背景去除和形态学图像处理。
