六、学习对象分类
在第 5 章,自动光学检测、对象分割和检测中,我们介绍了对象分割和检测的基本概念。 这指的是隔离图像中出现的对象以供将来处理和分析。 本章介绍如何对这些孤立对象中的每一个进行分类。 为了使我们能够对每个对象进行分类,我们必须训练我们的系统能够学习所需的参数,以便它决定将哪个特定标签分配给检测到的对象(取决于在训练阶段考虑的不同类别)。
本章介绍了机器学习的基本概念,用于对具有不同标签的图像进行分类。 为此,我们将基于第 5 章、自动光学检测、对象分割和检测的分割算法创建一个基本应用。 该分割算法提取包含未知对象的图像部分。 对于每个检测到的目标,我们将提取不同的特征,这些特征将使用机器学习算法进行分类。 最后,我们将显示使用我们的用户界面获得的所有结果,以及在输入图像中检测到的每个对象的标签。
本章涉及不同的主题和算法,包括以下内容:
- 机器学习概念简介
- 常用机器学习算法和过程
- 特征提取
- 支持向量机(SVM)
- 训练和预测
技术要求
本章要求熟悉基本的 C++ 编程语言。 本章中使用的所有代码都可以从以下 gihub 链接下载:*https://github.com/PacktPublishing/Building-Computer-Vision-Projects-with-OpenCV4-and-CPlusPlus/tree/master/Chapter06。这段代码可以在任何操作系统上执行,尽管它只在 Ubuntu 上测试过。
请查看以下视频,了解实际操作中的代码: http://bit.ly/2KGD4CO
机器学习概念简介
机器学习是由Arthur Samuel在 1959 年定义的一个概念,它是一个让计算机在没有明确编程的情况下能够学习的研究领域。 Tom M.Mitchel为机器学习提供了一个更正式的定义,在该定义中,他将样本的概念与经验数据、标签和算法的性能测量联系起来。
The machine learning definition by Arthur Samuel is referenced in Some Studies in Machine Learning Using the Game of Checkers in IBM Journal of Research and Development (Volume: 3, Issue: 3), p. 210. It was also referenced in The New Yorker and Office Management in the same year. The more formal definition from Tom M. Mitchel is referenced in Machine Learning Book, McGray Hill 1997: (http://www.cs.cmu.edu/afs/cs.cmu.edu/user/mitchell/ftp/mlbook.html).
机器学习涉及人工智能中的模式识别和学习理论,与计算统计学相关。 它还用于数百个应用,如光学字符识别(OCR)、垃圾邮件过滤、搜索引擎和数以千计的计算机视觉应用,例如我们将在本章开发的示例,其中机器学习算法试图对输入图像中出现的对象进行分类。
根据机器学习算法从输入数据中学习的方式,我们可以将其分为三类:
-
监督学习:计算机从一组标记的数据中学习。 这里的目标是了解允许计算机映射数据和输出标签结果之间关系的模型和规则的参数。
-
无监督学习:不给出标签,计算机试图发现给定数据的输入结构。
- 强化学习:计算机与动态环境交互,达到他们的目标并从他们的错误中学习。
根据我们希望从机器学习算法中获得的结果,我们可以将结果分类如下:
- 分类:输入的空间可以分为四个个个类,给定样本的预测结果就是这些训练类中的一个。 这是最常用的类别之一。 一个典型的例子可能是电子邮件垃圾邮件过滤,其中只有两类:垃圾邮件和非垃圾邮件。 或者,我们可以使用 OCR,其中只有 N 个字符可用,并且每个字符是一个类。
- 回归:输出是连续值,而不是像分类结果那样的离散值。 回归的一个例子可能是根据房子的大小、建造年限和位置对房价进行预测。
- 聚类:输入将被分成 N 个组,这通常是使用无监督训练来完成的。
- 密度估计:找出输入的(概率)分布。
在我们的示例中,我们将使用有监督的学习和分类算法,其中使用带有标签的训练数据集来训练模型,并且模型的预测结果是可能的标签之一。 在机器学习中,有几种途径和方法可以做到这一点。 其中一些比较流行的方法包括:支持向量机(SVM)、人工神经网络(ANN)、聚类、k 近邻、决策树和深度学习。 几乎所有这些方法和途径都在 OpenCV 中得到了支持、实现和良好的文档记录。 在本章中,我们将解释支持向量机。
OpenCV 机器学习算法
OpenCV 实现了其中八种机器学习算法。 它们都继承自StatModel类:
- 人工神经网络
- 随机树
- 期望最大化
- K-近邻
- Logistic 回归
-
正态贝叶斯分类器
-
支持向量机
- 随机梯度下降支持向量机
版本 3 支持基础级别的深度学习,但版本 4 更稳定且更受支持。 我们将在接下来的章节中详细探讨深度学习。
To get more information about each algorithm, read the OpenCV document page for machine learning at http://docs.opencv.org/trunk/dc/dd6/ml_intro.html.
下图显示了机器学习类层次结构:

StatModel类是所有机器学习算法的基类。 这提供了预测和所有读写功能,这些功能对于保存和读取我们的机器学习参数和训练数据非常重要。
在机器学习中,训练方法是最耗时、最耗费计算资源的部分。 对于大型数据集和复杂的机器学习结构,培训可能需要几秒钟到几周或几个月的时间。 例如,在深度学习中,拥有超过 10 万个图像数据集的大型神经网络结构可能需要很长时间才能进行训练。 对于深度学习算法,通常使用并行硬件处理,如采用 CUDA 技术的 GPU,以减少训练期间的计算时间,或者使用大多数新的芯片设备,如 Intel Movidius。 这意味着我们不能在每次运行我们的应用时训练我们的算法,因此建议用已经学习的所有参数保存我们训练过的模型。 在以后的执行中,我们只需从保存的模型中加载/读取,而无需训练,除非我们需要使用更多样本数据更新我们的模型。
StatModel是除深度学习方法以外的所有机器学习类(如 SVM 或 ANN)的基类。StatModel基本上是一个虚拟类,它定义了两个最重要的函数-train和predict。 train方法是负责使用训练数据集学习模型参数的主要方法。 此版本有以下三种可能的调用:
bool train(const Ptr<TrainData>& trainData, int flags=0 );
bool train(InputArray samples, int layout, InputArray responses);
Ptr<_Tp> train(const Ptr<TrainData>& data, int flags=0 );
列车功能具有以下参数:
TrainData:可以从TrainData类加载或创建的培训数据。 这个类是 OpenCV 3 中的新增类,帮助开发人员从机器学习算法中创建训练数据和摘要。 这样做是因为不同的算法需要不同类型的阵列结构来进行训练和预测,例如 ANN 算法。samples:训练数组样本的数组,例如机器学习算法要求的格式的训练数据。layout:ROW_SAMPLE(训练样本为矩阵行)或COL_SAMPLE(训练样本为矩阵列)。responses:与样本数据关联的响应向量。flags:每个方法定义的可选标志。
最后一个 Train 方法创建并训练_TP类类型的模型。 唯一接受的类是实现不带参数或全部使用默认参数值的静态 Create 方法的类。
predict方法要简单得多,并且只有一个可能的调用:
float StatModel::predict(InputArray samples, OutputArray results=noArray(), int flags=0)
预测函数具有以下参数:
samples:用于预测模型结果的输入样本可以由任意数量的数据组成,无论是单个数据还是多个数据。results:每个输入行样本的结果(由来自先前训练的模型的算法计算)。flags:这些可选标志取决于型号。 某些模型(如 Boost)由 SVM 的StatModel::RAW_OUTPUT标志识别,该标志使方法返回原始结果(总和),而不是类标签。
StatModel类为其他非常有用的方法提供了一个接口:
现在,我们将介绍一个在计算机视觉应用中使用机器学习的基本应用是如何构建的。
计算机视觉与机器学习工作流
具有机器学习的计算机视觉应用具有共同的基本结构。 此结构分为不同的步骤:
- 预处理
- 分段
- 特征提取
- 分类结果
- P主进程
这些在几乎所有的计算机视觉应用中都很常见,而其他的则被省略了。 在下图中,您可以看到涉及的不同步骤:
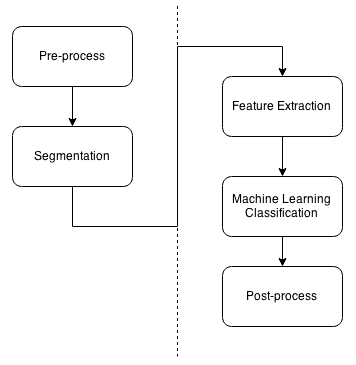
几乎所有的计算机视觉应用都是从应用于输入图像的预处理开始的,包括去除光线和噪声、过滤、模糊等。在对输入图像应用所有所需的预处理之后,第二步是分割。 在这一步中,我们必须提取图像中的感兴趣区域,并将每个区域分离为唯一的感兴趣对象。 例如,在人脸检测系统中,我们必须将人脸与场景中的其他部分分开。 在检测到图像内部的所有对象后,我们继续下一步。 在这里,我们必须提取每个对象的特征;这些特征通常是对象的特征向量。 特征描述我们的对象,可以是对象的面积、轮廓、纹理图案、像素等。
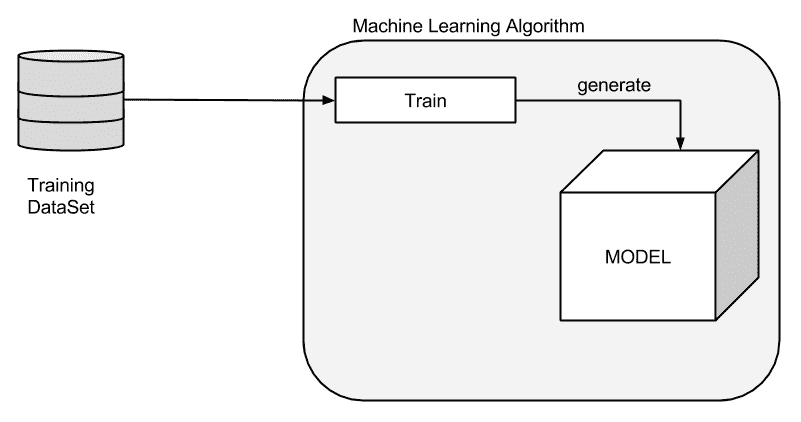
现在,我们有了对象的描述符,也称为特征向量或特征集。 描述符是描述对象的特征,我们使用它们来训练或预测模型。 要做到这一点,我们必须创建一个包含数千幅图像的大型特征数据集。 然后,我们在我们选择的列车模型函数中使用提取的特征(图像/对象特征),例如面积、大小和纵横比。 在下图中,我们可以看到如何将数据集送入机器学习算法来训练和生成模型:
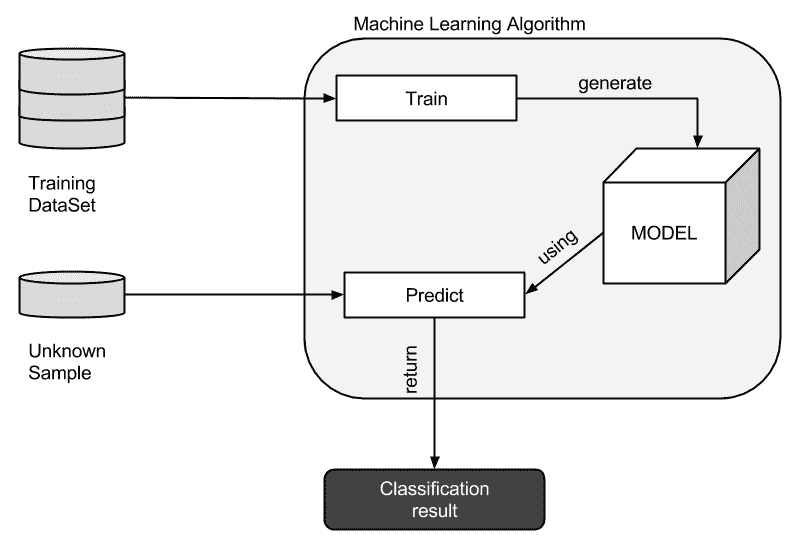
当我们用数据集训练时,模型学习能够预测何时具有未知标签的新特征向量作为我们算法的输入所需的所有参数。 在下图中,我们可以看到未知特征向量如何使用生成的模型来预测,从而返回分类和结果或回归:
在预测结果后,有时需要对输出数据进行后处理,例如合并多个分类以减少预测误差或合并多个标签。 光学字符识别中的一个示例是分类结果是根据每个预测字符,并且通过结合字符识别结果来构造一个词。 这意味着我们可以创建一种后处理方法来纠正检测到的单词中的错误。通过对计算机视觉的机器学习的这个小介绍,我们将实现我们自己的应用,使用机器学习来对幻灯片中的对象进行分类。 我们将使用支持向量机作为我们的分类方法,并解释如何使用它们。 其他机器学习算法的使用方式非常相似。 OpenCV 文档在以下链接中提供了有关所有机器学习算法的详细信息:https://docs.opencv.org/master/dd/ded/group__ml.html。
物体自动检测分类示例
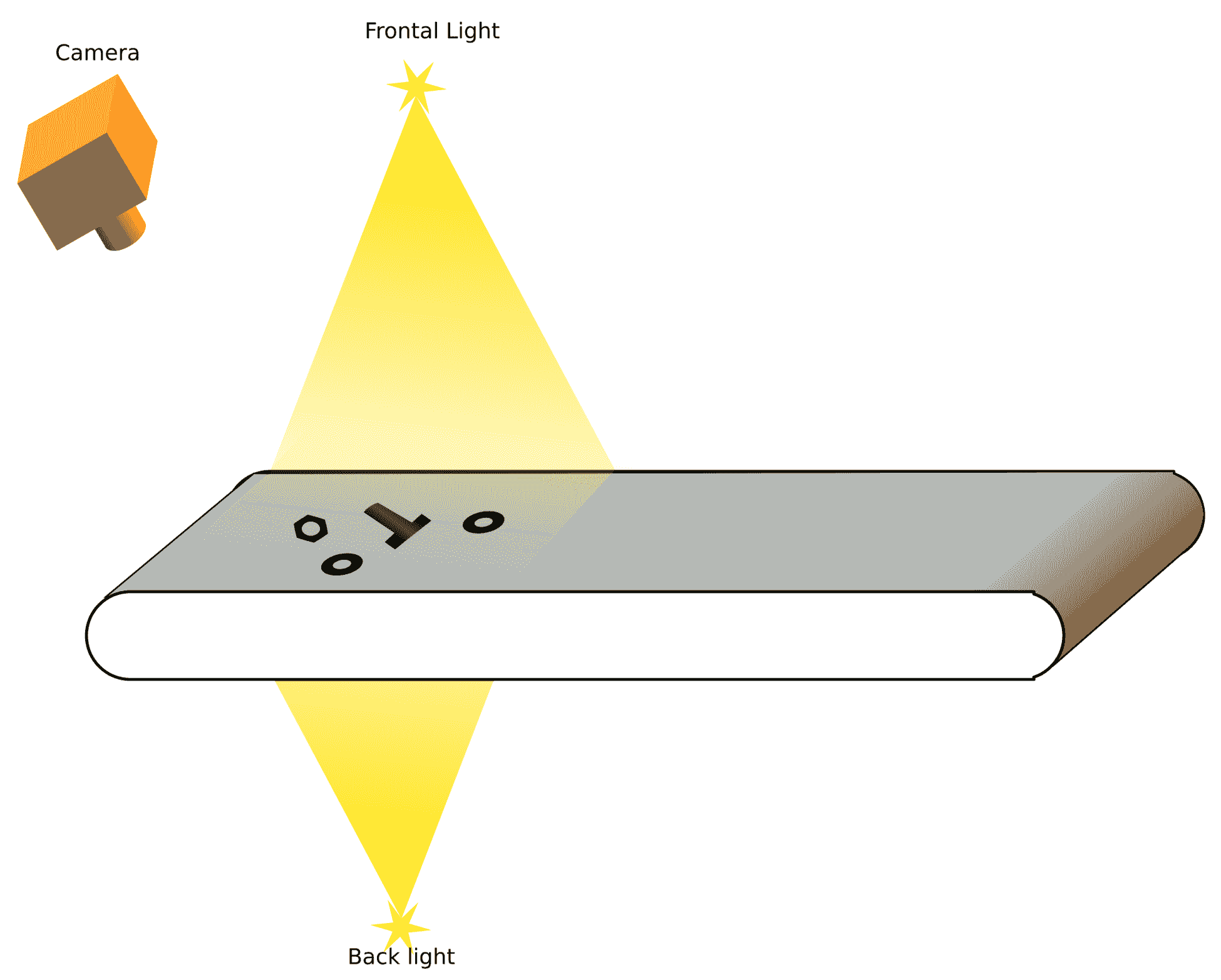
在第 5 章,自动光学检查、对象分割和检测中,我们查看了一个自动对象检查分段的示例,其中载体带包含三种不同类型的对象:螺母、螺丝和环。 有了计算机视觉,我们将能够识别其中的每一个,这样我们就可以向机器人发送通知,或者把每个机器人放在不同的盒子里。 以下是载带的基本示意图:
在第 5 章、自动光学检测、对象分割、和中,我们对输入图像进行预处理并提取感兴趣区域,使用不同的技术分离每个对象。 现在,我们将应用本示例中前面几节中解释的所有概念来提取特征并对每个对象进行分类,从而允许机器人将每个对象放入不同的盒子中。 在我们的应用中,我们不会只显示每个图像的标签,但我们可以将图像中的位置和标签发送给其他设备,如机器人。 此时,我们的目标是提供具有不同对象的输入图像,允许计算机检测对象并在每个图像上显示对象的名称,如下图所示。 然而,为了了解整个过程的步骤,我们将通过创建一个曲线图来训练我们的系统,以显示我们要使用的功能分布,并用不同的颜色将其可视化。 我们还将展示预处理后的输入图像,以及得到的输出分类结果。 最终结果看起来如下:

对于我们的示例应用,我们将遵循以下步骤:
-
对于每个输入图像:
- 对图像进行预处理
- 分割图像
- 对于图像中的每个对象:
- 提取要素
- 将特征添加到带有相应标签(螺母、螺钉、环)的训练特征向量
- 创建一个 SVM 模型。
- 用训练后的特征向量训练支持向量机模型。
- 对输入图像进行预处理,对每个分割对象进行分类。
- 分割输入图像。
- 对于检测到的每个对象:
- 提取要素
- 用支持向量机进行预测
- 模型 / 模式 / 模范 / 时装模特儿
- 在输出图像中绘制结果
对于预处理和分割,我们将使用第 5 章、自动光学检测、对象分割、和检测中的代码。 然后我们将解释如何提取特征并创建训练和预测我们的模型所需的向量。
特征提取
接下来我们需要做的是提取每个对象的特征。 为了理解特征向量的概念,我们将在示例中提取非常简单的特征,因为这足以获得良好的结果。 在其他解决方案中,我们可以获得更复杂的特征,如纹理描述符、轮廓描述符等。在我们的示例中,我们只有图像中不同位置和方向的螺母、环和螺钉。 同一对象可以位于图像和方向的任何位置,例如,螺钉或螺母。 我们可以在下图中看到不同的方向:

我们将探索一些特征或特征,这些特征可以提高我们机器学习算法的准确性。 我们的不同对象(螺母、螺丝和环)的这些可能特征如下:
- 对象的面积
- 长宽比,即宽度除以边界矩形的高度
- 孔洞的数量
- 等高线边数
这些特征可以很好地描述我们的对象,如果我们全部使用,分类误差会很小。 但是,在我们实现的示例中,我们只打算使用前两个特征(面积和纵横比)来学习,因为我们可以在 2D 图形中绘制这些特征,并显示这些值能够正确地描述我们的对象。 我们还可以说明,在图形情节中,我们可以在视觉上区分一种对象和另一种对象。 为了提取这些特征,我们将使用黑/白 ROI 图像作为输入,其中只有一个对象以白色显示,背景为黑色。 该输入是第 5 章、自动光学检测、对象分割、和检测的分割结果。 我们将使用findCountours算法分割对象,并为此创建ExtractFeatures函数,如下面的代码所示:
vector< vector<float> > ExtractFeatures(Mat img, vector<int>* left=NULL, vector<int>* top=NULL)
{
vector< vector<float> > output;
vector<vector<Point> > contours;
Mat input= img.clone();
vector<Vec4i> hierarchy;
findContours(input, contours, hierarchy, RETR_CCOMP, CHAIN_APPROX_SIMPLE);
// Check the number of objects detected
if(contours.size() == 0){
return output;
}
RNG rng(0xFFFFFFFF);
for(auto i=0; i<contours.size(); i++){
Mat mask= Mat::zeros(img.rows, img.cols, CV_8UC1);
drawContours(mask, contours, i, Scalar(1), FILLED, LINE_8, hierarchy, 1);
Scalar area_s= sum(mask);
float area= area_s[0];
if(area>500){ //if the area is greater than min.
RotatedRect r= minAreaRect(contours[i]);
float width= r.size.width;
float height= r.size.height;
float ar=(width<height)?height/width:width/height;
vector<float> row;
row.push_back(area);
row.push_back(ar);
output.push_back(row);
if(left!=NULL){
left->push_back((int)r.center.x);
}
if(top!=NULL){
top->push_back((int)r.center.y);
}
// Add image to the multiple image window class, See the class on full github code
miw->addImage("Extract Features", mask*255);
miw->render();
waitKey(10);
}
}
return output;
}
让我们解释一下我们用来提取特征的代码。 我们将创建一个函数,该函数将一张图像作为输入,并返回图像中检测到的每个对象的左位置和顶部位置的两个向量作为参数。 这些数据将用于在每个对象上绘制相应的标签。 函数的输出是浮点数向量的向量。 换句话说,它是一个矩阵,其中每一行都包含检测到的每个对象的特征。
首先,我们必须创建将在查找轮廓算法分割中使用的输出向量变量和轮廓变量。 我们还必须创建输入图像的副本,因为前面的findCoutoursOpenCV 函数修改输入图像:
vector< vector<float> > output;
vector<vector<Point> > contours;
Mat input= img.clone();
vector<Vec4i> hierarchy;
findContours(input, contours, hierarchy, RETR_CCOMP, CHAIN_APPROX_SIMPLE);
现在,我们可以使用findContours函数来检索图像中的每个对象。 如果没有检测到任何轮廓,则返回一个空的输出矩阵,如下面的代码片断所示:
if(contours.size() == 0){
return output;
}
如果检测到所有对象,对于每个轮廓,我们将在黑色图像(零值)上绘制白色对象。 这将使用1值来完成,就像遮罩图像一样。 以下代码生成蒙版图像:
for(auto i=0; i<contours.size(); i++){
Mat mask= Mat::zeros(img.rows, img.cols, CV_8UC1);
drawContours(mask, contours, i, Scalar(1), FILLED, LINE_8, hierarchy, 1);
使用1的值在形状内部绘制非常重要,因为我们可以通过将轮廓内的所有值相加来计算面积,如以下代码所示:
Scalar area_s= sum(mask);
float area= area_s[0];
这个区域是我们的第一个特色。 我们将使用该值作为筛选器,以删除我们必须避免的所有可能的小对象。 面积小于我们考虑的最小阈值面积的所有对象都将被丢弃。 通过过滤器后,我们创建第二个特征和对象的纵横比。 这是指宽度或高度的最大值除以宽度或高度的最小值。 此功能可以很容易地区分螺丝和其他物体。 下面的代码描述了如何计算纵横比:
if(area>MIN_AREA){ //if the area is greater than min.
RotatedRect r= minAreaRect(contours[i]);
float width= r.size.width;
float height= r.size.height;
float ar=(width<height)?height/width:width/height;
现在我们有了特征,我们只需将它们添加到输出向量中。 为此,我们将创建一个浮点数的行向量并将这些值相加,然后将此行添加到输出向量,如以下代码所示:
vector<float> row;
row.push_back(area);
row.push_back(ar);
output.push_back(row);
如果传递了 Left 和 top 参数,则将左上角的值相加以输出参数:
if(left!=NULL){
left->push_back((int)r.center.x);
}
if(top!=NULL){
top->push_back((int)r.center.y);
}
最后,我们将在窗口中显示检测到的对象以供用户反馈。 处理完图像中的所有对象后,我们将返回输出特征向量,如以下代码片段所述:
miw->addImage("Extract Features", mask*255);
miw->render();
waitKey(10);
}
}
return output;
现在我们已经提取了每个输入图像的特征,我们可以继续下一步。
训练支持向量机模型
现在我们将使用监督学习,然后获得每个对象的一组图像及其对应的标签。 数据集中没有图像的最小数量;如果我们为训练过程提供更多的图像,我们将获得更好的分类模型(在大多数情况下)。 然而,对于简单的分类器,训练简单的模型就足够了。 为此,我们创建了三个文件夹(screw、nut和ring),每种类型的所有图像都放在一起。对于文件夹中的每个图像,我们必须提取特征,将它们添加到train特征矩阵中,同时创建一个新的向量,每行的标签对应于每个训练矩阵。 为了评估我们的系统,我们将根据测试和培训将每个文件夹拆分成多个图像。 我们将留下大约 20 个图像用于测试,其余的用于培训。 然后,我们将创建两个标签向量和两个矩阵,用于训练和测试。
让我们进入我们的代码内部。 首先,我们必须创建我们的模型。 我们将在所有函数中声明该模型,以便能够将其作为全局变量访问。 OpenCV 使用Ptr模板类进行指针管理:
Ptr<SVM> svm;
在声明指向新的 SVM 模型的指针之后,我们将创建它并训练它。 为此,我们创建了trainAndTest函数。 完整的功能代码如下:
void trainAndTest()
{
vector< float > trainingData;
vector< int > responsesData;
vector< float > testData;
vector< float > testResponsesData;
int num_for_test= 20;
// Get the nut images
readFolderAndExtractFeatures("../data/nut/nut_%04d.pgm", 0, num_for_test, trainingData, responsesData, testData, testResponsesData);
// Get and process the ring images
readFolderAndExtractFeatures("../data/ring/ring_%04d.pgm", 1, num_for_test, trainingData, responsesData, testData, testResponsesData);
// get and process the screw images
readFolderAndExtractFeatures("../data/screw/screw_%04d.pgm", 2, num_for_test, trainingData, responsesData, testData, testResponsesData);
cout << "Num of train samples: " << responsesData.size() << endl;
cout << "Num of test samples: " << testResponsesData.size() << endl;
// Merge all data
Mat trainingDataMat(trainingData.size()/2, 2, CV_32FC1, &trainingData[0]);
Mat responses(responsesData.size(), 1, CV_32SC1, &responsesData[0]);
Mat testDataMat(testData.size()/2, 2, CV_32FC1, &testData[0]);
Mat testResponses(testResponsesData.size(), 1, CV_32FC1, &testResponsesData[0]);
Ptr<TrainData> tdata= TrainData::create(trainingDataMat, ROW_SAMPLE, responses);
svm = cv::ml::SVM::create();
svm->setType(cv::ml::SVM::C_SVC);
svm->setNu(0.05);
svm->setKernel(cv::ml::SVM::CHI2);
svm->setDegree(1.0);
svm->setGamma(2.0);
svm->setTermCriteria(TermCriteria(TermCriteria::MAX_ITER, 100, 1e-6));
svm->train(tdata);
if(testResponsesData.size()>0){
cout << "Evaluation" << endl;
cout << "==========" << endl;
// Test the ML Model
Mat testPredict;
svm->predict(testDataMat, testPredict);
cout << "Prediction Done" << endl;
// Error calculation
Mat errorMat= testPredict!=testResponses;
float error= 100.0f * countNonZero(errorMat) / testResponsesData.size();
cout << "Error: " << error << "%" << endl;
// Plot training data with error label
plotTrainData(trainingDataMat, responses, &error);
}else{
plotTrainData(trainingDataMat, responses);
}
}
现在,让我们解释一下代码。 首先,我们必须创建存储训练和测试数据所需的变量:
vector< float > trainingData;
vector< int > responsesData;
vector< float > testData;
vector< float > testResponsesData;
正如我们前面提到的,我们必须读取每个文件夹中的所有图像,提取特征,并将它们保存在我们的培训和测试数据中。 为此,我们将使用readFolderAndExtractFeatures函数,如下所示:
int num_for_test= 20;
// Get the nut images
readFolderAndExtractFeatures("../data/nut/tuerca_%04d.pgm", 0, num_for_test, trainingData, responsesData, testData, testResponsesData);
// Get and process the ring images
readFolderAndExtractFeatures("../data/ring/arandela_%04d.pgm", 1, num_for_test, trainingData, responsesData, testData, testResponsesData);
// get and process the screw images
readFolderAndExtractFeatures("../data/screw/tornillo_%04d.pgm", 2, num_for_test, trainingData, responsesData, testData, testResponsesData);
readFolderAndExtractFeatures函数使用VideoCaptureOpenCV 函数读取文件夹中的所有图像,包括视频和摄像头帧。 对于读取的每个图像,我们提取特征并将它们添加到相应的输出向量中:
bool readFolderAndExtractFeatures(string folder, int label, int num_for_test,
vector<float> &trainingData, vector<int> &responsesData,
vector<float> &testData, vector<float> &testResponsesData)
{
VideoCapture images;
if(images.open(folder)==false){
cout << "Can not open the folder images" << endl;
return false;
}
Mat frame;
int img_index=0;
while(images.read(frame)){
//// Preprocess image
Mat pre= preprocessImage(frame);
// Extract features
vector< vector<float> > features= ExtractFeatures(pre);
for(int i=0; i< features.size(); i++){
if(img_index >= num_for_test){
trainingData.push_back(features[i][0]);
trainingData.push_back(features[i][1]);
responsesData.push_back(label);
}else{
testData.push_back(features[i][0]);
testData.push_back(features[i][1]);
testResponsesData.push_back((float)label);
}
}
img_index++ ;
}
return true;
}
在用特征和标签填充所有矢量之后,我们必须将矢量转换为 OpenCVMat格式,以便可以将其发送到训练函数:
// Merge all data
Mat trainingDataMat(trainingData.size()/2, 2, CV_32FC1, &trainingData[0]);
Mat responses(responsesData.size(), 1, CV_32SC1, &responsesData[0]);
Mat testDataMat(testData.size()/2, 2, CV_32FC1, &testData[0]);
Mat testResponses(testResponsesData.size(), 1, CV_32FC1, &testResponsesData[0]);
现在,我们准备创建和训练我们的机器学习模型。 如前所述,我们将使用支持向量机来实现这一点。 首先,我们将设置基本模型参数,如下所示:
// Set up SVM's parameters
svm = cv::ml::SVM::create();
svm->setType(cv::ml::SVM::C_SVC);
svm->setNu(0.05);
svm->setKernel(cv::ml::SVM::CHI2);
svm->setDegree(1.0);
svm->setGamma(2.0);
svm->setTermCriteria(TermCriteria(TermCriteria::MAX_ITER, 100, 1e-6));
我们现在将定义要使用的 SVM 类型和内核,以及停止学习过程的标准。 在我们的例子中,我们将使用最大迭代次数,在 100 次迭代时停止。 有关每个参数及其作用的更多信息,请查看位于以下链接的 OpenCV 文档:和 https://docs.opencv.org/master/d1/d2d/classcv_1_1ml_1_1SVM.html。 创建设置参数后,我们将通过调用train方法并使用trainingDataMat和响应矩阵作为TrainData对象来创建模型:
// Train the SVM
svm->train(tdata);
我们使用测试向量(将num_for_test变量设置为大于0)来获得模型的近似误差。 为了得到误差估计,我们将对所有测试向量特征进行预测,以获得 SVM 预测结果,并将这些结果与原始标签进行比较:
if(testResponsesData.size()>0){
cout << "Evaluation" << endl;
cout << "==========" << endl;
// Test the ML Model
Mat testPredict;
svm->predict(testDataMat, testPredict);
cout << "Prediction Done" << endl;
// Error calculation
Mat errorMat= testPredict!=testResponses;
float error= 100.0f * countNonZero(errorMat) / testResponsesData.size();
cout << "Error: " << error << "%" << endl;
// Plot training data with error label
plotTrainData(trainingDataMat, responses, &error);
}else{
plotTrainData(trainingDataMat, responses);
}
我们通过使用testDataMat特性和一个新的Mat预测结果来使用predict函数。 predict函数使得同时进行多个预测成为可能,即给出一个矩阵作为结果,而不是只给出一行或向量。预测之后,我们只需计算testPredict与我们的testResponses(原始标签)的差值。 如果有差异,我们只需要数一下有多少,然后除以测试的总数,就可以计算出误差。
We can use the new TrainData class to generate the feature vectors, samples, and split our train data between test and train vectors.
最后,我们将在 2D 绘图中显示训练数据,其中y轴是纵横比特征,x轴是对象的面积。 每个点都有不同的颜色和形状(十字形、正方形和圆形)来显示每种不同的对象,我们可以清楚地看到下图中的对象组:
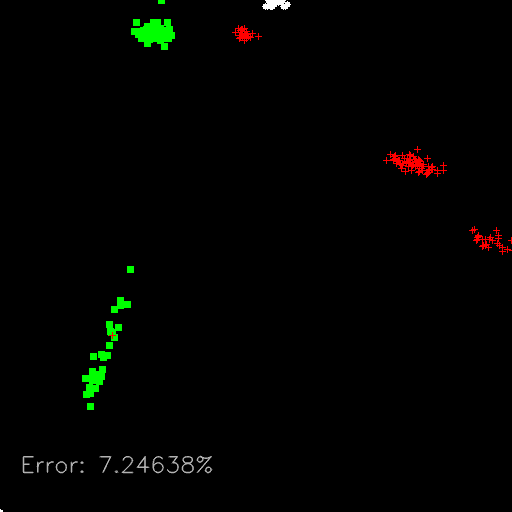
我们现在非常接近完成我们的应用示例。 在这一点上,我们已经训练了 SVM 模型;我们现在可以将其用于分类,以检测新传入和未知特征向量的类型。 下一步是预测具有未知对象的输入图像。
输入图像预测
现在我们准备解释主函数,该函数加载输入图像并预测其中出现的对象。 我们将使用类似以下图片的内容作为输入图像。 在这里,多个不同的物体出现在图像中。 我们没有这些的标签或名称,但计算机必须能够识别它们:

与所有训练图像一样,我们必须加载并预处理输入图像,如下所示:
- 首先,我们加载图像并将其转换为灰色值。
- 然后,我们使用
preprocessImage函数应用预处理任务(如我们在第 5 章、自动光学检查离子、对象分割、和检测中了解到的):
Mat pre= preprocessImage(img);
- 现在,我们将使用前面描述的
ExtractFeatures来提取图像中出现的所有对象的向量特征以及每个对象的左上角位置:
// Extract features
vector<int> pos_top, pos_left;
vector< vector<float> >
features=ExtractFeatures(pre, &pos_left, &pos_top);
- 我们将检测到的每个对象存储为特征行,然后将每行转换为一行和两个特征的
Mat:
for(int i=0; i< features.size(); i++){
Mat trainingDataMat(1, 2, CV_32FC1, &features[i][0]);
- 之后,我们可以使用我们的
StatModel支持向量机的predict函数对单个目标进行预测,预测的浮动结果就是检测到的目标的标签。 然后,要完成应用,我们必须在输出图像上绘制检测到并分类的每个对象的标签:
float result= svm->predict(trainingDataMat);
- 我们将使用
stringstream存储文本,使用Scalar存储每个不同标签的颜色:
stringstream ss;
Scalar color;
if(result==0){
color= green; // NUT
ss << "NUT";
}else if(result==1){
color= blue; // RING
ss << "RING" ;
}else if(result==2){
color= red; // SCREW
ss << "SCREW";
}
- 我们还将使用在
ExtractFeatures函数中检测到的位置在每个对象上绘制标签文本:
putText(img_output,
ss.str(),
Point2d(pos_left[i], pos_top[i]),
FONT_HERSHEY_SIMPLEX,
0.4,
color);
- 最后,我们将在输出窗口中绘制结果:
miw->addImage("Binary image", pre);
miw->addImage("Result", img_output);
miw->render();
waitKey(0);
我们的应用的最终结果显示了一个由四个屏幕组成的平铺窗口。 这里,左上角是输入训练图像,右上角是剧情训练图像,左下角是分析预处理图像的输入图像,右下角是预测的最终结果:

简略的 / 概括的 / 简易判罪的 / 简易的
在本章中,我们学习了机器学习的基础知识,并将其应用到一个小示例应用中。 这让我们了解了可以用来创建我们自己的机器学习应用的基本技术。机器学习很复杂,每个用例都涉及不同的技术(监督学习、无监督学习、聚类等)。 我们还学习了如何使用支持向量机创建最典型的机器学习应用-监督学习应用。监督机器学习中最重要的概念如下:您必须有适当数量的样本或数据集,您必须准确地选择描述我们对象的特征(有关图像特征的更多信息,请转到第 8 章、视频监控、背景建模、和形态运算)。 你必须选择一个能给出最好预测的模型。
如果我们没有得到正确的预测,我们必须检查这些概念中的每一个来发现问题所在。
在下一章中,我们将介绍背景减去方法,这些方法在视频监控应用中非常有用,因为在视频监控应用中,背景没有给我们任何有趣的信息,必须将其丢弃,以便我们可以分割图像来检测和分析图像对象。
