十六、基于深度卷积网络的车牌识别
本章向我们介绍为自动车牌识别(ANPR)创建应用所需的步骤。 根据不同的情况,有不同的方法和技术;例如,红外摄像机,固定的汽车位置,以及光线条件。 我们可以继续构建一个 ANPR 应用,在距离汽车 2 到 3 米的距离拍摄的照片中,在模糊的灯光条件下,在非平行地面上检测汽车牌照,车牌上的透视失真很小。
本章的主要目的是介绍图像分割与特征提取、模式识别基础知识,以及使用卷积网络的支持向量机(SVM)和深度神经网络[DNN)这两种重要的模式识别算法。 在本章中,我们将介绍以下主题:
- ANPR
- 板材检测
- 车牌识别
ANPR 简介
ANPR 有时也被称为自动车牌识别、(ALPR)、自动车辆识别、(AVI)或车牌识别、(CPR),是一种智能监控方法,它使用光学字符识别和(OCR)
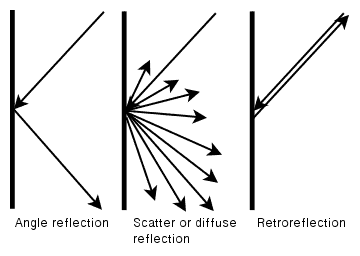
使用红外线和(IR)摄像头可以获得最好的 ANPR 识别系统的结果,因为检测和 OCR 分割的分割步骤简单而干净,而且它们将错误降至最低。 这要归功于光的定律,最基本的一条就是入射角等于反射角。 当我们看到平滑的表面(如平面镜)时,我们可以看到这种基本反射。 纸等粗糙表面的反射会导致一种被称为散射反射或漫反射的反射。 然而,大多数国家的板块都有一个特殊的特征,称为回射:板块的表面由一种材料制成,这种材料覆盖着数千个微小的半球,使光线反射回源,如我们在下图中所看到的:
如果我们使用带有滤光片耦合的结构化红外线投影仪的摄像头,我们可以只检索红外光,然后我们就有了非常高质量的图像进行分割,随后我们可以独立于任何照明环境来检测和识别车牌号,如下图所示:

在本章中,我们将不使用红外照片;我们将使用常规照片,因此我们不会获得最佳结果,而且我们会获得比使用红外相机更高水平的检测错误和更高的错误识别率。 但是,两者的步骤是相同的。
每个国家都有不同的汽车牌照大小和规格。 了解这些规范对于获得最佳结果和减少错误非常有用。 本章中使用的算法旨在解释 ANPR 的基础知识,并为西班牙使用的车牌而设计,但我们可以将其扩展到任何国家或规范。
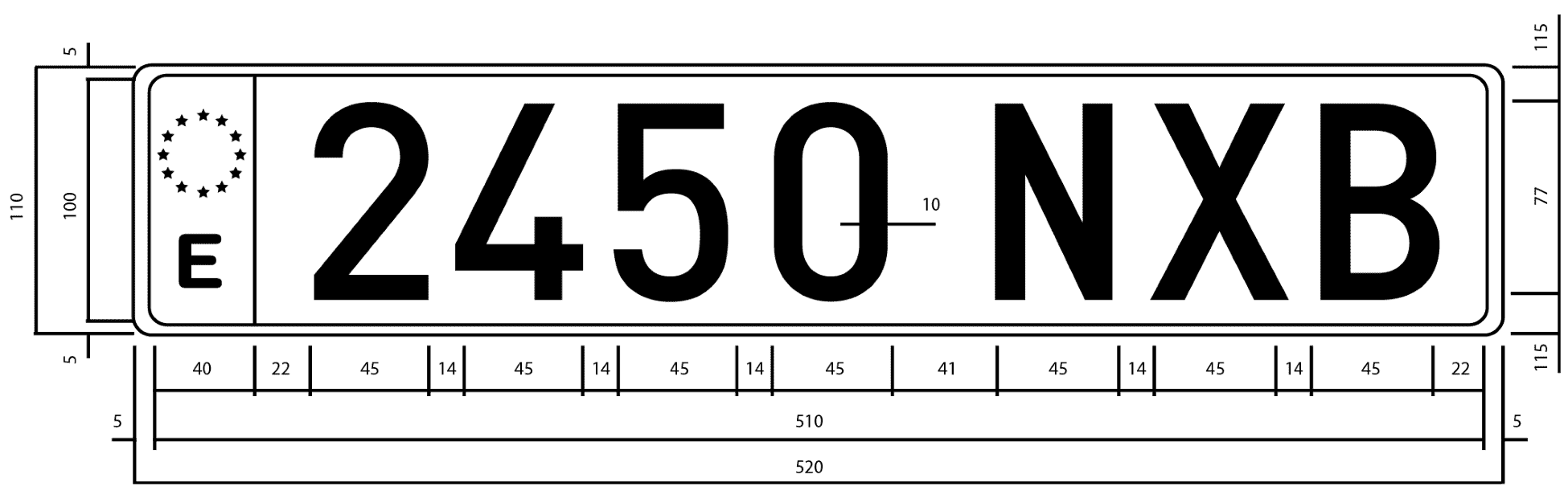
在本章中,我们将使用来自西班牙的车牌。 在西班牙,车牌有三种不同的大小和形状,但我们将只使用最常见的(大)车牌,它的宽度为 520 毫米,高度为 110 毫米。 两组字符以 41 mm 的间距分隔,每个单独的字符以 14 mm 的间距分隔。 第一组字符是四位数字,第二组是三个字母,不包括元音A、E、I、O或U,或者字母N或Q。 所有字符的尺寸均为 45 mm×77 mm。
该数据对于字符分割非常重要,因为我们可以同时检查字符和空格,以验证我们得到的是字符,而不是其他图像分段:
ANPR 算法
在解释完整的 ANPR 算法代码之前,我们需要定义 ANPR 算法中的主要步骤和任务。 车牌识别分为两个主要步骤,车牌检测和车牌识别:
- 车牌检测的目的是检测车牌在整个摄像机画面中的位置。
- 当在图像中检测到车牌时,车牌分段被传递到第二步(车牌识别),该步骤使用 OCR 算法来确定车牌上的字母数字字符。
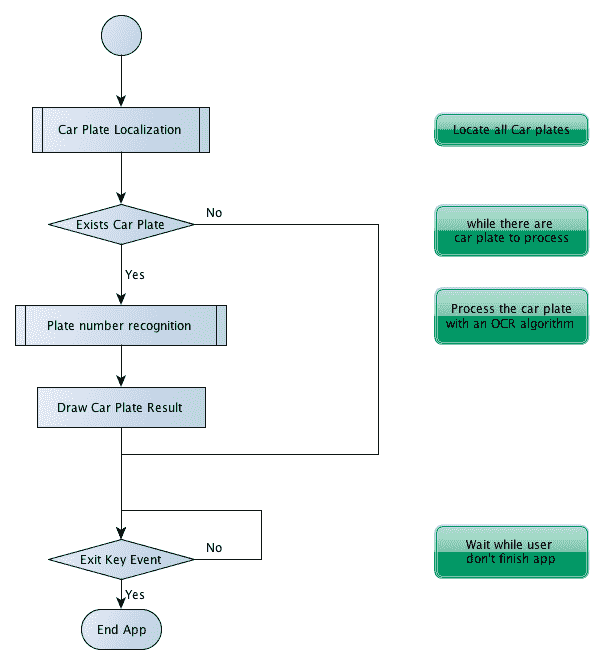
在下图中,我们可以看到两个主要的算法步骤,车牌检测和车牌识别。 在这些步骤之后,程序会在相机图像中绘制已检测到的车牌字符。 算法可能返回错误结果,也可能不返回任何结果:
在上图所示的每个步骤中,我们将定义模式识别算法中常用的另外三个步骤。 这些步骤如下:
- 分割:此步骤检测并移除图像中的每个感兴趣的补丁/区域。
- 特征提取:此步骤从每个补丁中提取一组特征。
- 分类:该步骤从车牌识别步骤中提取每个字符,或者在车牌检测步骤中将每个图像块分类为车牌或无车牌。
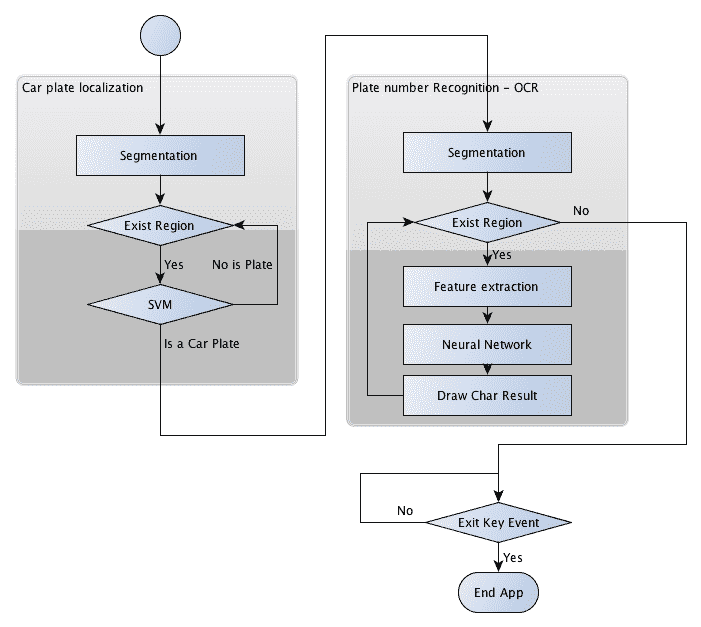
在下图中,我们可以看到应用中的这些模式识别步骤作为一个整体:
除了主要的应用(其目的是检测和识别车牌号码)之外,我们还将简要说明另外两个通常不会解释的任务:
- 如何训练模式识别系统
- 如何评价它?
然而,这些任务可能比主要应用更重要,因为如果我们没有正确训练模式识别系统,我们的系统可能会失败,无法正常工作;不同的模式需要不同的训练和评估过程。 我们需要根据不同的环境、条件和功能对我们的系统进行评估,以获得最佳结果。 这两个任务有时是一起完成的,因为不同的功能可能会产生不同的结果,我们可以在评估部分看到这一点。
板材检测
在这一步中,我们必须对当前摄像机帧中的所有底片进行检测。 为此,我们将其分为两个主要步骤:分段和分段分类。 由于我们使用图像块作为矢量特征,所以没有解释特征步骤。
在第一步(分割)中,我们将应用不同的过滤器、形态学操作、轮廓算法和验证来检索可能包含车牌的图像部分。
在第二步(分类)中,我们将应用支持向量机分类器来识别每个图像块,也就是我们的特征。 在创建我们的主应用之前,我们将使用两个不同的类进行训练:板块和非板块。 我们将使用 800 像素宽的平行正面视图彩色图像,这些图像距离汽车 2 到 4 米。 这些要求对于正确分割非常重要。 如果我们创建一个多尺度图像算法,我们就可以进行检测。
在下图中,我们将展示车牌检测涉及的每个进程:

涉及的程序如下:
- Sobel 滤波器
- 阈值操作
- 封闭形态运算
- 其中一个填充区域的蒙版
- 红色,可能检测到的车牌(图片特色)
- 用支持向量机分类器检测车牌
分割
分割是将一幅图像分割成多个片段的最新过程。 这一过程是为了简化用于分析的图像,并使特征提取更容易。
车牌分割的一个重要特征是车牌中垂直边缘的数量很多,假设图像是正面拍摄的,车牌没有旋转,也没有透视失真。 可以在第一个分割步骤中利用此功能来消除没有任何垂直边缘的区域。
在找到垂直边缘之前,我们需要将彩色图像转换为灰度图像(因为颜色不能帮助我们完成此任务),并删除相机或其他环境噪声可能产生的噪声。 我们将应用 5x5 高斯模糊并去除噪波。 如果我们不应用噪声去除方法,我们可能会得到许多产生失败检测的垂直边缘:
//convert image to gray
Mat img_gray;
cvtColor(input, img_gray, CV_BGR2GRAY);
blur(img_gray, img_gray, Size(5,5));
要找到垂直边缘,我们将使用第一个Sobel过滤器并找到第一个水平导数。 导数是一个数学函数,可以让我们找到图像上的垂直边缘。OpenCV 中的Sobel函数定义如下:
void Sobel(InputArray src, OutputArray dst, int ddepth, int xorder, int yorder, int ksize=3, double scale=1, double delta=0, int borderType=BORDER_DEFAULT )
这里,ddepth是目标图像深度;xorder是x的导数阶数;yorder是y的导数阶数;ksize是一、三、五、七的核大小;scale是计算导数值的可选因子;delta是加到结果上的可选值;以及*borderType是像素插值
然后,对于我们的情况,我们可以使用xorder=1、yorder=0、和ksize=3:
//Find vertical lines. Car plates have high density of vertical
lines
Mat img_sobel;
Sobel(img_gray, img_sobel, CV_8U, 1, 0, 3, 1, 0);
在应用Sobel滤波器之后,我们将应用阈值滤波器来获得具有通过 Otsu 方法获得的阈值的二值图像。 Otsu 的算法需要 8 位输入图像,Otsu 的方法自动确定最佳阈值:
//threshold image
Mat img_threshold;
threshold(img_sobel, img_threshold, 0, 255, CV_THRESH_OTSU+CV_THRESH_BINARY);
要在 Threshold 函数中定义 Otsu 的方法,我们将把 type 参数与 ThresholdCV_THRESH_OTSU的值结合起来,并忽略 Threshold 参数。
When the CV_THRESH_OTSU value is defined, the threshold function returns the optimal threshold value obtained by Otsu's algorithm.
通过应用封闭的形态运算,我们可以删除每条垂直边缘线之间的空格,并连接所有具有大量边缘的区域。 在这一步中,我们有可能包含板块的区域。
首先,我们将定义在形态操作中使用的结构元素。 在我们的例子中,我们将使用getStructuringElement函数来定义尺寸为17乘以3的结构矩形元素;这在其他图像大小中可能有所不同:
Mat element = getStructuringElement(MORPH_RECT, Size(17, 3));
然后,我们将使用morphologyEx函数在封闭的形态运算中使用此结构元素:
morphologyEx(img_threshold, img_threshold, CV_MOP_CLOSE, element);
在我们应用了这些功能之后,我们在图像中有可能包含车牌的区域;但是,大多数区域都不包含车牌。 可以通过连通分量分析或使用findContours函数来分割这些区域。 最后一个函数使用不同的方法和结果检索二值图像的轮廓。 我们只需要获得具有任何层次关系和任何多边形近似结果的外轮廓:
//Find contours of possibles plates
vector< vector< Point>> contours;
findContours(img_threshold,
contours, // a vector of contours
CV_RETR_EXTERNAL, // retrieve the external contours
CV_CHAIN_APPROX_NONE); // all pixels of each contours
对于检测到的每个轮廓,提取最小面积的边界矩形。 OpenCV 会调出此任务的minAreaRect函数。 此函数返回旋转后的RotatedRect个 Rectangle 类。 然后,在每个轮廓上使用向量迭代器,我们可以得到旋转的矩形,并在对每个区域进行分类之前进行一些初步验证:
//Start to iterate to each contour founded
vector<vector<Point>>::iterator itc= contours.begin();
vector<RotatedRect> rects;
//Remove patch that has no inside limits of aspect ratio and
area.
while (itc!=contours.end()) {
//Create bounding rect of object
RotatedRect mr= minAreaRect(Mat(*itc));
if(!verifySizes(mr)){
itc= contours.erase(itc);
}else{
++ itc;
rects.push_back(mr);
}
}
我们根据区域的面积和纵横比对检测到的区域进行基本验证。 我们会认为,如果一个区域的长宽比约为520/110=4.727272(板块宽度除以板块高度),误差幅度为 40%,且区域的高度最小为 115像素,最大为 5125像素,则区域可以是板块。 这些值是根据图像大小和相机位置计算的:
bool DetectRegions::verifySizes(RotatedRect candidate ){
float error=0.4;
//Spain car plate size: 52x11 aspect 4,7272
const float aspect=4.7272;
//Set a min and max area. All other patchs are discarded
int min= 15*aspect*15; // minimum area
int max= 125*aspect*125; // maximum area
//Get only patches that match to a respect ratio.
float rmin= aspect-aspect*error;
float rmax= aspect+aspect*error;
int area= candidate.size.height * candidate.size.width;
float r= (float)candidate.size.width
/(float)candidate.size.height;
if(r<1)
r= 1/r;
if(( area < min || area > max ) || ( r < rmin || r > rmax )){
return false;
}else{
return true;
}
}
我们可以利用车牌的白色背景属性做更多的改进。 所有的板子都有相同的背景颜色,我们可以使用泛洪填充算法来检索旋转的矩形以进行精确的裁剪。
裁剪车牌的第一步是在最后旋转的矩形中心附近找到几个种子。 然后,我们将得到介于宽度和高度之间的最小板子大小,并使用它在贴片中心附近生成随机种子。
我们希望选择白色区域,并且需要几个种子才能接触到至少一个白色像素。 然后,对于每个种子,我们使用一个floodFill函数来绘制新的蒙版图像,以存储新的最近裁剪区域:
for(int i=0; i< rects.size(); i++){
//For better rect cropping for each possible box
//Make floodFill algorithm because the plate has white background
//And then we can retrieve more clearly the contour box
circle(result, rects[i].center, 3, Scalar(0,255,0), -1);
//get the min size between width and height
float minSize=(rects[i].size.width < rects[i].size.height)?
rects[i].size.width:rects[i].size.height;
minSize=minSize-minSize*0.5;
//initialize rand and get 5 points around center for floodFill algorithm
srand ( time(NULL) );
//Initialize floodFill parameters and variables
Mat mask;
mask.create(input.rows + 2, input.cols + 2, CV_8UC1);
mask= Scalar::all(0);
int loDiff = 30;
int upDiff = 30;
int connectivity = 4;
int newMaskVal = 255;
int NumSeeds = 10;
Rect ccomp;
int flags = connectivity + (newMaskVal << 8 ) + CV_FLOODFILL_FIXED_RANGE + CV_FLOODFILL_MASK_ONLY;
for(int j=0; j<NumSeeds; j++){
Point seed;
seed.x=rects[i].center.x+rand()%(int)minSize-(minSize/2);
seed.y=rects[i].center.y+rand()%(int)minSize-(minSize/2);
circle(result, seed, 1, Scalar(0,255,255), -1);
int area = floodFill(input, mask, seed, Scalar(255,0,0), &ccomp, Scalar(loDiff, loDiff, loDiff), Scalar(upDiff, upDiff, upDiff), flags);
函数的作用是:将带有颜色的连通分量填充到从点种子开始的蒙版图像中,并设置要填充的像素与像素的相邻像素或像素种子之间的最大上下限亮度/色差:
int floodFill(InputOutputArray image, InputOutputArray mask, Point seed, Scalar newVal, Rect* rect=0, Scalar loDiff=Scalar(), Scalar upDiff=Scalar(), int flags=4 )
参数newval是我们希望在填充时合并到图像中的新颜色。 第一个loDiff和第二个upDiff参数是要填充的像素与像素邻居或像素种子之间的最大下限和最大上限亮度/色差。
参数 FLAG_1 是以下位的简单组合:
- 低位:这些位包含函数中使用的连接值,四个(默认情况下)或八个。 连通性确定要考虑像素的哪些邻居。
- 高位:这些位可以是 0,也可以是下列值的组合:
CV_FLOODFILL_FIXED_RANGE和*CV_FLOODFILL_MASK_ONLY。
CV_FLOODFILL_FIXED_RANGE设置当前像素和种子像素之间的差异。CV_FLOODFILL_MASK_ONLY将只填充图像蒙版,不会更改图像本身。
一旦我们有了一个裁剪蒙版,我们将从图像遮罩点获得一个最小面积的矩形,并再次检查有效大小。 对于每个蒙版,一个白色像素获取位置,并使用minAreaRect函数检索最近的裁剪区域:
//Check new floodFill mask match for a correct patch.
//Get all points detected for get Minimal rotated Rect
vector<Point> pointsInterest;
Mat_<uchar>::iterator itMask= mask.begin<uchar>();
Mat_<uchar>::iterator end= mask.end<uchar>();
for( ; itMask!=end; ++ itMask)
if(*itMask==255)
pointsInterest.push_back(itMask.pos());
RotatedRect minRect = minAreaRect(pointsInterest);
if(verifySizes(minRect)){
分割过程已经完成,我们得到了有效的区域。 现在,我们可以裁剪每个检测到的区域,删除可能的旋转,裁剪图像区域,调整图像大小,并均衡裁剪图像区域的光线。
首先,我们需要生成具有*getRotationMatrix2D的变换矩阵,以去除检测到的区域中可能出现的旋转。 我们需要注意高度,因为RotatedRect可以返回并以90度旋转。 因此,我们必须检查矩形纵横比,如果它小于1,则需要将其旋转90度:
//Get rotation matrix
float r= (float)minRect.size.width / (float)minRect.size.height;
float angle=minRect.angle;
if(r<1)
angle=90+angle;
Mat rotmat= getRotationMatrix2D(minRect.center, angle,1);
有了变换矩阵,我们现在可以通过使用warpAffine函数的仿射变换(仿射变换保留平行线)来旋转输入图像,其中我们设置了输入和目标图像、变换矩阵、输出大小(与本例中的输入相同)和要使用的插值方法。 如果需要,我们可以定义边框方法和边框值:
//Create and rotate image
Mat img_rotated;
warpAffine(input, img_rotated, rotmat, input.size(),
CV_INTER_CUBIC);
在旋转图像之后,我们将使用getRectSubPix裁剪图像,这将裁剪和复制以点为中心的宽度和高度的图像部分。 如果图像被旋转,我们需要使用 C++ swap函数更改宽度和高度大小:
//Crop image
Size rect_size=minRect.size;
if(r < 1)
swap(rect_size.width, rect_size.height);
Mat img_crop;
getRectSubPix(img_rotated, rect_size, minRect.center, img_crop);
裁剪后的图像不适合用于训练和分类,因为它们的大小不同。 此外,每幅图像包含不同的光线条件,突出了它们之间的差异。 要解决此问题,我们将所有图像的大小调整为相同的宽度和高度,并应用光线直方图均衡化:
Mat resultResized;
resultResized.create(33,144, CV_8UC3);
resize(img_crop, resultResized, resultResized.size(), 0, 0, INTER_CUBIC);
//Equalize croped image
Mat grayResult;
cvtColor(resultResized, grayResult, CV_BGR2GRAY);
blur(grayResult, grayResult, Size(3,3));
equalizeHist(grayResult, grayResult);
对于每个检测到的区域,我们将裁剪的图像及其位置存储在向量中:
output.push_back(Plate(grayResult,minRect.boundingRect()));
现在我们已经有了可能检测到的区域,我们必须对每个可能的区域是否为板块进行分类。 在下一节中,我们将学习如何基于支持向量机创建分类。
分类 / 同 taxonomy / 种类 / 类别,等级
在我们对图像的所有可能部分进行预处理和分割之后,我们现在需要确定每个部分是否是(或不是)车牌。 要做到这一点,我们将使用一种改进的支持向量机算法。
支持向量机是一种模式识别算法,它包括在最初为二进制分类创建的监督学习算法家族中。 监督学习是一种用标记数据训练的机器学习算法技术。 我们需要用标记的数据量训练算法;每个数据集都需要有一个类。
支持向量机创建一个或多个超平面,用于区分每类数据。
经典的示例是定义了两个类的 2D 点集;SVM 搜索区分每个类的最佳直线:
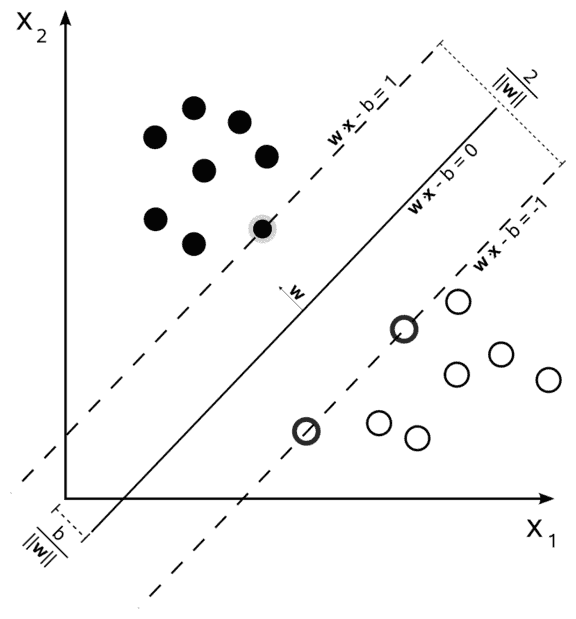
在任何一个新的分类器之前,第一个任务就是培训我们的分类器;这是在主应用之前要承担的一项工作,也就是我们所说的“线下培训”。 这不是一件容易的工作,因为它需要足够的数据来训练系统,但更大的数据集并不总是意味着最好的结果。 在我们的案例中,由于没有公开的车牌数据库,我们没有足够的数据。 因此,我们需要拍摄数百张汽车照片,然后对它们进行预处理和分割。
我们用 75 张车牌图像和 35 张没有车牌的图像训练了我们的系统,分辨率为 144x33 像素。 我们可以在下图中看到此数据的示例。 这不是一个很大的数据集,但足以为我们的章节获得令人满意的结果。 在实际应用中,我们需要使用更多数据进行训练:

为了容易理解机器学习的工作原理,我们将继续使用分类器算法的图像像素特征(请记住,有更好的方法和特征来训练 SVM,例如主成分分析)(PCA)、傅立叶变换和纹理分析)。
为了保存图像,我们需要使用DetectRegions类重新创建图像以训练我们的系统,并将savingRegions变量设置为true。 我们可以使用命令segmentAllFiles.sh的 bash 脚本对文件夹中的所有图像文件重复该过程。 这可以从本书的源代码中获取。
为了方便起见,我们将把所有经过处理和准备的图像训练数据存储到一个 XML 文件中,以便直接与 SVM 函数一起使用。 trainSVM.cpp应用使用文件夹和图像文件数量创建此文件。
Training data for a machine learning OpenCV algorithm is stored in an NxM matrix, with N samples and M features. Each dataset is saved as a row in the training matrix.
这些类存储在另一个大小为nx1的矩阵中,其中每个类由一个float数字标识。
OpenCV 提供了一种非常简单的方法来管理 XML 或 YAML 格式的数据文件,它使用FileStorage类。 这个类允许我们存储和读取 OpenCV 变量和结构,或者我们的自定义变量。 使用此功能,我们可以读取培训数据矩阵和培训课程,并将其保存在SVM_TrainingData和SVM_Classes中:
FileStorage fs;
fs.open("SVM.xml", FileStorage::READ);
Mat SVM_TrainingData;
Mat SVM_Classes;
fs["TrainingData"] >>SVM_TrainingData;
fs["classes"] >>SVM_Classes;
现在,我们在SVM_TrainingData变量中有训练数据,在SVM_Classes中有标签。 然后,我们只需创建连接要在我们的机器学习算法中使用的数据和标签的训练数据对象。 为此,我们将使用TrainData类作为 OpenCV 指针Ptr类,如下所示:
Ptr<TrainData> trainData = TrainData::create(SVM_TrainingData, ROW_SAMPLE, SVM_Classes);
我们将使用SVM类创建分类器对象,使用Ptr创建分类器对象,或使用 OpenCV 4 创建分类器对象std::shared_ptrOpenCV 类:
Ptr<SVM> svmClassifier = SVM::create()
现在,我们需要设置支持向量机参数,这些参数定义了在支持向量机算法中使用的基本参数。 要做到这一点,我们只需更改一些对象变量。 经过不同的实验,我们将选择下一个参数的设置:
svmClassifier->setTermCriteria(TermCriteria(TermCriteria::MAX_ITER, 1000, 0.01));
svmClassifier->setC(0.1);
svmClassifier->setKernel(SVM::LINEAR);
我们选择了1000次进行训练,对0.1进行了C个参数变量优化,最后选择了一个核函数。
我们只需要用train函数和训练数据训练我们的分类器:
svmClassifier->train(trainData);
我们的分类器已经准备好使用我们的 SVM 类的预测函数来预测可能的裁剪图像;该函数返回类标识符i。 在我们的例子中,我们将把plate类标记为 1,将no plate类标记为 0。 然后,对于每个检测到的可能是车牌的区域,我们将使用支持向量机将其分类为车牌或无车牌,并且只保存正确的响应。 以下代码是称为在线处理的主应用的一部分:
vector<Plate> plates;
for(int i=0; i< posible_regions.size(); i++)
{
Mat img=posible_regions[i].plateImg;
Mat p= img.reshape(1, 1);//convert img to 1 row m features
p.convertTo(p, CV_32FC1);
int response = (int)svmClassifier.predict( p );
if(response==1)
plates.push_back(posible_regions[i]);
}
车牌识别
车牌识别的第二步是用 OCR 检索车牌字符。 对于每个检测到的车牌,我们对每个字符进行车牌分割,并使用人工神经网络的机器学习算法来识别字符。 另外,在本节中,您将学习如何评估分类算法。
OCR 分割
首先,我们将首先获得一个车牌图像块作为 OCR 分割函数的输入,并使用均衡化的直方图。 然后,我们只需要应用阈值过滤器,并使用该阈值图像作为查找轮廓算法的输入。 我们可以在下图中观察到这一过程:

此分段过程编码如下:
Mat img_threshold;
threshold(input, img_threshold, 60, 255, CV_THRESH_BINARY_INV);
if(DEBUG)
imshow("Threshold plate", img_threshold);
Mat img_contours;
img_threshold.copyTo(img_contours);
//Find contours of possibles characters
vector< vector< Point>> contours;
findContours(img_contours, contours, // a vector of contours
CV_RETR_EXTERNAL, // retrieve the external contours
CV_CHAIN_APPROX_NONE); // all pixels of each contours
我们使用参数CV_THRESH_BINARY_INV来反转阈值输出,方法是将白色输入值设置为黑色,将黑色输入值设置为白色。 这是获取每个字符的轮廓所必需的,因为轮廓算法搜索白色像素。
对于每个检测到的轮廓,我们可以进行尺寸验证,并删除尺寸较小或纵横比不正确的所有区域。 在我们的例子中,字符的纵横比为 45/77,对于旋转或扭曲的字符,我们可以接受 35%的纵横比误差。 如果面积大于 80%,我们将认为该区域是黑色块而不是字符。 为了计算面积,我们可以使用countNonZero函数,该函数计算数值大于零的像素数:
bool OCR::verifySizes(Mat r){
//Char sizes 45x77
float aspect=45.0f/77.0f;
float charAspect= (float)r.cols/(float)r.rows;
float error=0.35;
float minHeight=15;
float maxHeight=28;
//We have a different aspect ratio for number 1, and it can be ~0.2
float minAspect=0.2;
float maxAspect=aspect+aspect*error;
//area of pixels
float area=countNonZero(r);
//bb area
float bbArea=r.cols*r.rows;
//% of pixel in area
float percPixels=area/bbArea;
if(percPixels < 0.8 && charAspect > minAspect && charAspect <
maxAspect && r.rows >= minHeight && r.rows < maxHeight)
return true;
else
return false;
}
如果一个分割后的字符被验证,我们必须对其进行预处理,以便为所有字符设置相同的大小和位置,并使用辅助的CharSegment类将其保存在一个向量中。 这个类保存了分割的字符图像和我们对字符进行排序所需的位置,因为查找轮廓算法不会按所需的正确顺序返回轮廓。
基于卷积神经网络的字符分类
在我们开始使用卷积神经网络和深度学习之前,我们将介绍这些主题和创建 DNN 的工具。
深度学习是机器学习家族的一部分,可以是有监督的,也可以是半监督的,也可以是无监督的。 在科学界,DNN 并不是一个新概念。 这个术语于 1986 年由 Rina Dechter 引入机器学习领域,并于 2000 年由 Igor Aizenberg 引入人工神经网络。 但这一领域的研究始于 1980 年初,当时的研究如新认知电子管是卷积神经网络的灵感来源。
但深度学习并不是在 2009 年之前开始革命的。 2009 年,随着新的研究算法的出现,硬件方面的进步重新燃起了人们对深度学习的兴趣,使用 NVIDIA 图形处理器来加速训练算法,以前可能需要几天或几个月的时间,现在速度提高了 100 倍。
卷积神经网络,ConvNet,或 CNN,是一类基于前馈网络的深度学习算法,主要应用于计算机视觉。 CNN 使用多层感知器的一种变体,允许我们自动提取移位不变特征。 与人工经典机器学习相比,CNN 使用的预处理相对较少。 与其他机器学习算法相比,特征提取是一个主要优势。
卷积神经网络像经典的人工神经网络一样,由具有多个隐含层的输入输出层组成,不同之处在于输入通常是图像的原始像素,隐含层由卷积层和汇聚层组成,完全连通或归一化。
现在,我们来简要介绍一下卷积神经网络中最常用的几个层:
- 卷积:本层对输入应用卷积运算过滤器,将结果传递给下一层。 这一层的工作原理类似于典型的计算机视觉过滤器(Sobel、Canny 等),但内核过滤器是在训练阶段学习的。 使用这一层的主要好处是减少了常见的完全连接的前馈神经网络,例如,100 x 100 图像有 10,000 个权重,但使用 CNN,问题就减少到了核大小;例如,应用 5 x 5 和 32 个不同过滤器的核,只有5532=800。 同时,这些过滤器激发了特征提取的所有可能性。
- 汇集:这一层将一组神经元的输出合并成一个单一的。 最常见的是 max pooling,它返回输入神经元组的最大值。 深度学习中另一种经常使用的方法是平均汇集。 这一层为 CNN 带来了在随后的层中提取更高级别特征的可能性。
- FLATEN:FLATEN 不是 DNN 层,而是将矩阵转换为简单向量的常见操作;此步骤是应用其他层并最终获得分类所必需的。
- 完全连接:这与传统的多层感知器相同,在传统的多层感知器中,前一层的每个神经元都通过激活功能连接到下一层。
- Dropout:-这一层是减少过拟合的正则化;-它是对模型执行精确度的常用层。
- 损失层:这通常是 DNN 中的最后一层,并指定如何训练和计算误差以执行预测。 一种非常常见的损失层是用于分类的 Softmax。
OpenCV 深度学习并不是为培训深度学习模型而设计的,也不受支持,因为有非常稳定和强大的开源项目只专注于深度学习,如 TensorFlow、Caffe 和 Torch。 然后,OpenCV 有一个接口来导入和读取最重要的模型。
然后,我们将在 TensorFlow 中开发我们的 CNN 用于 OCR 分类,TensorFlow 是最常用和最流行的深度学习软件库之一,最初是由谷歌研究人员和工程师开发的。
用 TensorFlow 创建和训练卷积神经网络
本节将探讨如何训练新的 TensorFlow 模型,但在开始创建模型之前,我们必须检查图像数据集并生成训练模型所需的资源。
准备数据
我们有 30 个字符和数字,分布在数据集中的 702 个图像上,分布如下。 我们可以检查到有超过 30 个数字图像,但一些字母,如K、M和P,图像样本较少:
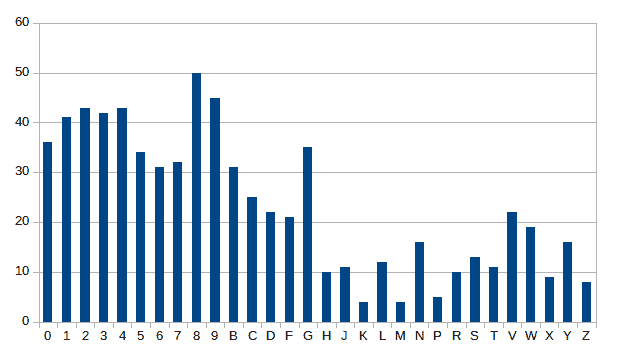
在下图中,我们可以看到数据集中的一小部分图像:
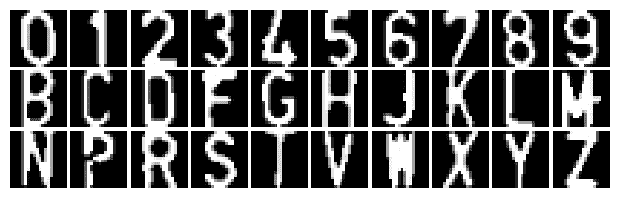
对于深度学习来说,这个数据集非常小。 深度学习需要大量的样本,是一种常用的技术。 在某些情况下,可以在原始数据集上使用数据集扩充。 数据集增强是一种通过应用不同的变换(如旋转、翻转图像、透视扭曲和添加噪波)来创建新样本的方法。
有多种方法可以扩充数据集:我们可以创建自己的脚本或使用开源库来完成此任务。 我们将使用增强器(https://github.com/mdbloice/Augmentor)。 Augmentor 是一个 Python 库,它允许我们通过应用我们认为对我们的问题更方便的转换来创建所需数量的样本。
要通过pip安装 Augmentor,我们必须执行以下命令:
pip install Augmentor
在安装库之后,我们创建一个小的 Python 脚本来生成并增加改变变量number_samples的样本数量,并应用以下内容:随机扭曲、剪切以及扭曲和旋转扭曲,如我们在下一个 Python 脚本中所看到的:
import Augmentor
number_samples = 20000
p = Augmentor.Pipeline("./chars_seg/chars/")
p.random_distortion(probability=0.4, grid_width=4, grid_height=4, magnitude=1)
p.shear(probability=0.5, max_shear_left=5, max_shear_right=5)
p.skew_tilt(probability=0.8, magnitude=0.1)
p.rotate(probability=0.7, max_left_rotation=5, max_right_rotation=5)
p.sample(number_samples)
此脚本将生成一个输出文件夹,其中将存储所有图像,并保持与原始路径相同的路径。 我们需要生成两个数据集,一个用于训练,另一个用于测试我们的算法。 然后,我们将通过更改number_samples生成 20,000 个用于训练的图像和 2,000 个用于测试的图像中的一个。
现在我们有了足够的图像,我们必须将它们提供给 TensorFlow 算法。 TensorFlow 允许多种输入数据格式,例如带有图像和标签的 CSV 文件、Numpy 数据文件以及推荐的 TFRecordDataset。
Visit http://blog.damiles.com/2018/06/18/tensorflow-tfrecodataset.html for more info about why it is better to use TFRecordDataset instead of CSV files with image references.
在生成 TFRecordDataset 之前,我们需要安装 TensorFlow 软件。 我们可以使用pip和以下针对 CPU 的命令来安装它:
pip install tensorflow
或者,如果您有支持 CUDA 的 NVIDIA 卡,您可以使用 GPU 发行版:
pip install tensorflow-gpu
现在,我们可以创建数据集文件来训练我们的模型,使用提供的脚本create_tfrecords_from_dir.py,传递两个参数,即图像所在的输入文件夹和输出文件。 我们必须调用此脚本两次,一次用于培训,另一次用于测试,以分别生成这两个文件。 我们可以在下面的代码片断中看到该调用的示例:
python ./create_tfrecords_from_dir.py -i ../data/chars_seg/DNN_data/test -o ../data/chars_seg/DNN_data/test.tfrecords
python ./create_tfrecords_from_dir.py -i ../data/chars_seg/DNN_data/train -o ../data/chars_seg/DNN_data/train.tfrecords
该脚本生成两个test.tfrecords和train.tfrecords文件,其中标签是自动分配的编号,并按文件夹名称排序。 train文件夹必须具有以下结构:
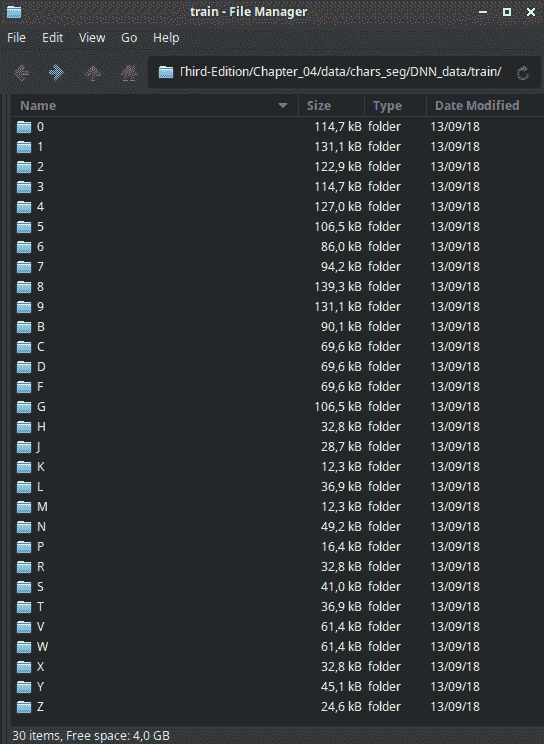
现在,我们有了数据集,我们已经准备好创建我们的模型,并开始训练和评估。
创建 TensorFlow 模型
TensorFlow 是一个开源软件库,专注于高性能数值计算和深度学习,可访问和支持 CPU、GPU 和 TPU(张量处理单元,专用于深度学习的新 Google 硬件)。 这个库不是一个容易的库,学习曲线很高,但引入 Kera(TensorFlow 之上的库)作为 TensorFlow 的一部分,让学习曲线变得更容易,但仍然需要巨大的学习曲线本身。
在这一章中,我们不能解释如何使用 TensorFlow,因为我们需要单独为这个主题编写一本书,但我们将解释我们将使用的 CNN 的结构。 我们将展示如何使用名为 TensorEditor 的在线可视化工具在几分钟内生成 TensorFlow 代码,我们可以下载这些代码并在计算机上进行本地训练,或者如果我们没有足够的计算机处理能力,也可以使用相同的在线工具来训练我们的模型。 如果您想阅读和学习 TensorFlow,我们建议您阅读任何相关的 Packt Publishing 书籍或 TensorFlow 教程。
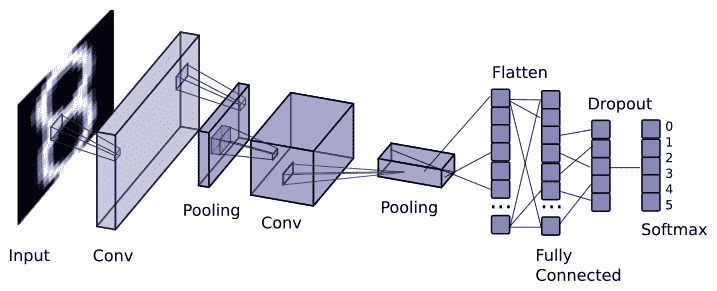
我们将要创建的 CNN 层结构是一个简单的卷积网络:
- 卷积层 1:32 个 5x5 带 REU 激活功能的滤波器
- 池化第 2 层:使用 2 x 2 过滤器和跨度为 2 的最大池化
- 卷积层 3:64 个 5x5 滤波器,具有 RELU 激活功能
- 池化层 4:使用 2 x 2 过滤器和跨度为 2 的最大池化
- 致密层 5:↔1,024 个神经元
- 丢包层 6:丢包率为 0.4 的丢包率正则化
- 致密层 7:包含30 个神经元,每个数字和字符对应一个神经元
- SoftMax Layer 8:SoftMax Layer Lost 函数,采用梯度下降优化器,学习率为 0.001,训练步数为 20,000 步。
我们可以在下图中看到我们必须生成的模型的基本图形:
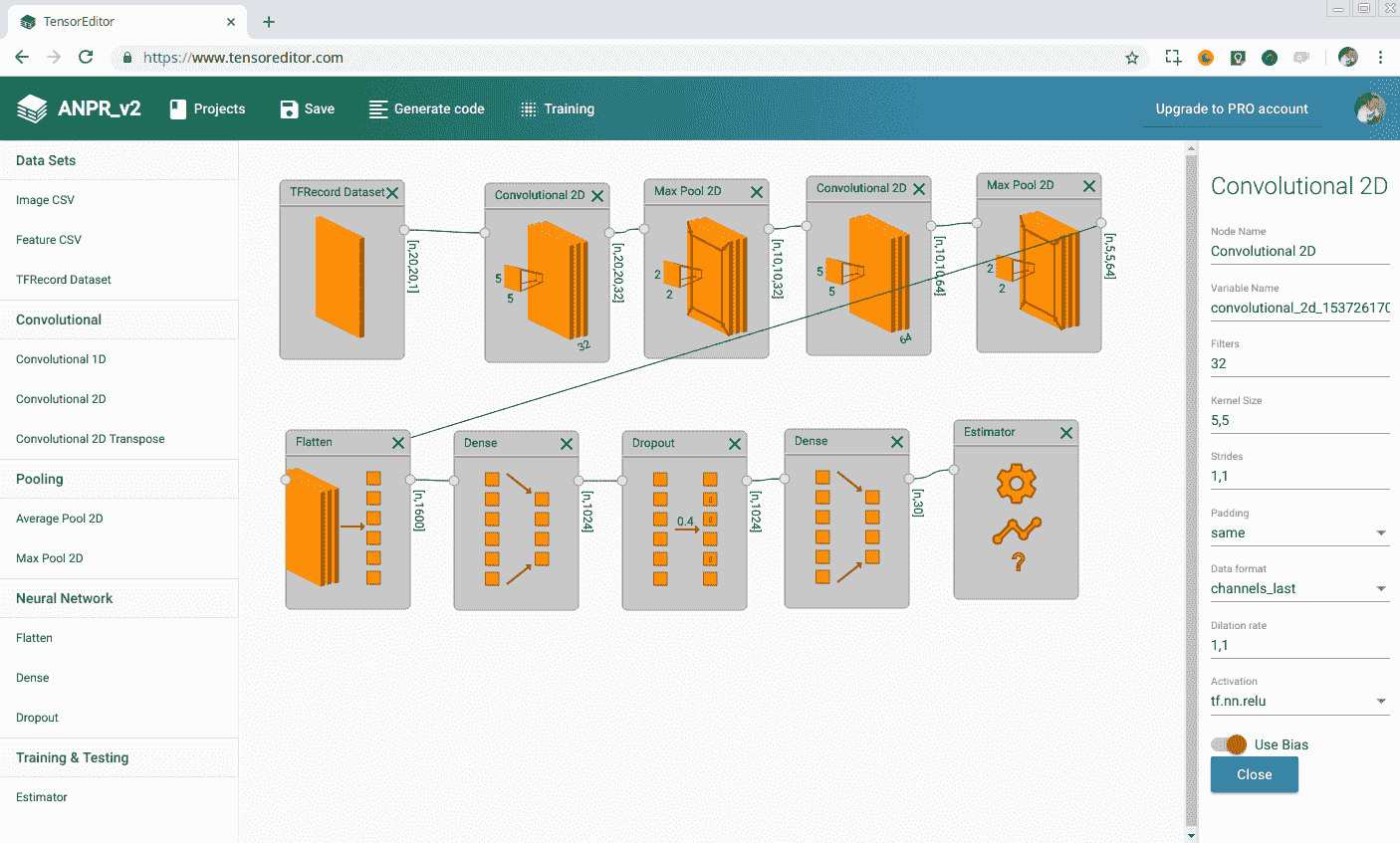
TensorEditor 是一个在线工具,它允许我们为 TensorFlow 创建模型并在云上进行训练,或者下载 Python2.7 代码并在本地执行。 注册在线免费下载工具后,即可生成模型,如下图所示:
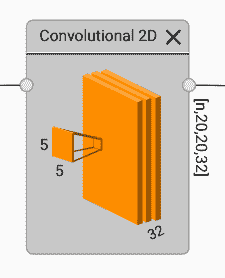
要添加一个层,我们通过单击左侧菜单来选择它,它将出现在编辑器中。 我们可以拖放来改变它的位置,双击来改变它的参数。 点击每个节点的小点,我们就可以链接到每个节点/层。 这个编辑器向我们展示了我们视觉上选择的参数和每个层的输出大小;我们可以在下图中看到,卷积层的核为 5 x 5 x 32,输出为 n x 20 x 20 x 32;n 变量表示我们可以为每个训练周期同时计算一幅或多幅图像:
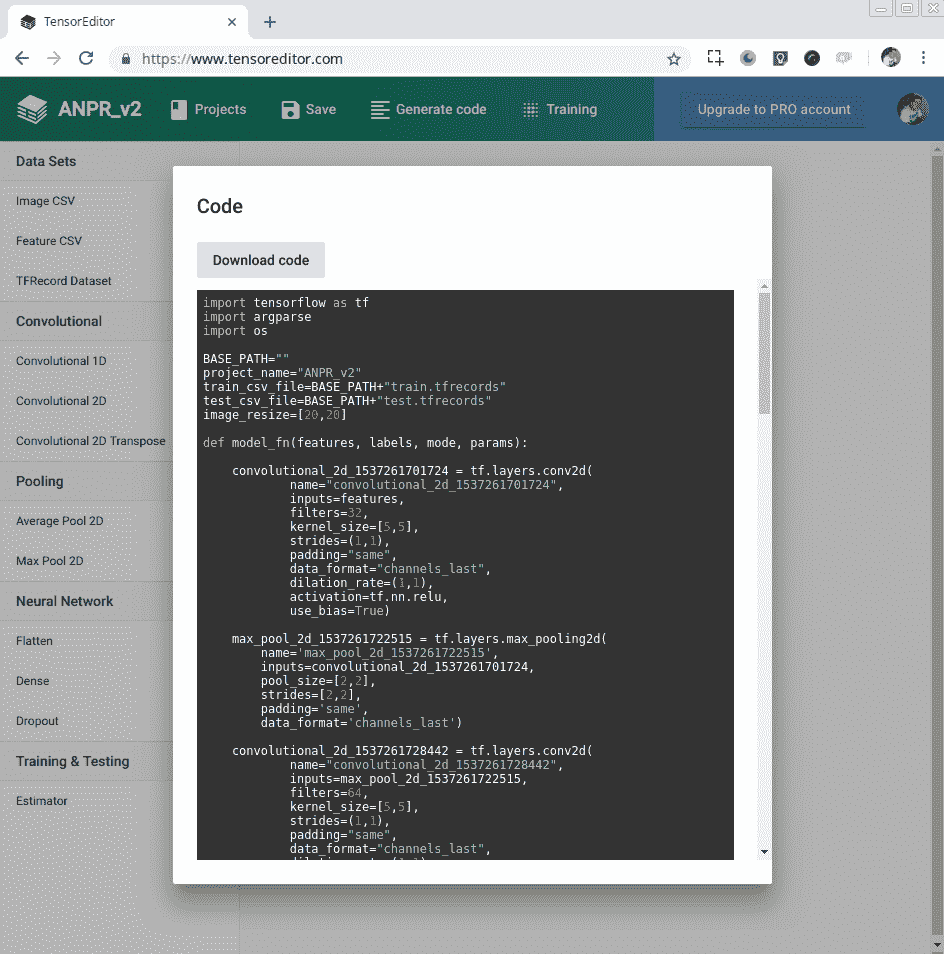
在 TensorEditor 中创建 CNN 层结构后,我们现在可以通过单击 Generate Code 并下载 Python 代码来下载 TensorFlow 代码,如以下屏幕截图所示:
现在,我们可以通过以下命令使用 TensorFlow 开始训练我们的算法:
python code.py --job-dir=./model_output
这里,参数--job-dir定义了存储训练好的输出模型的输出文件夹。 在终端中,我们可以看到每一次迭代的输出,以及损失结果和精度。 我们可以在下面的截图中看到一个示例:
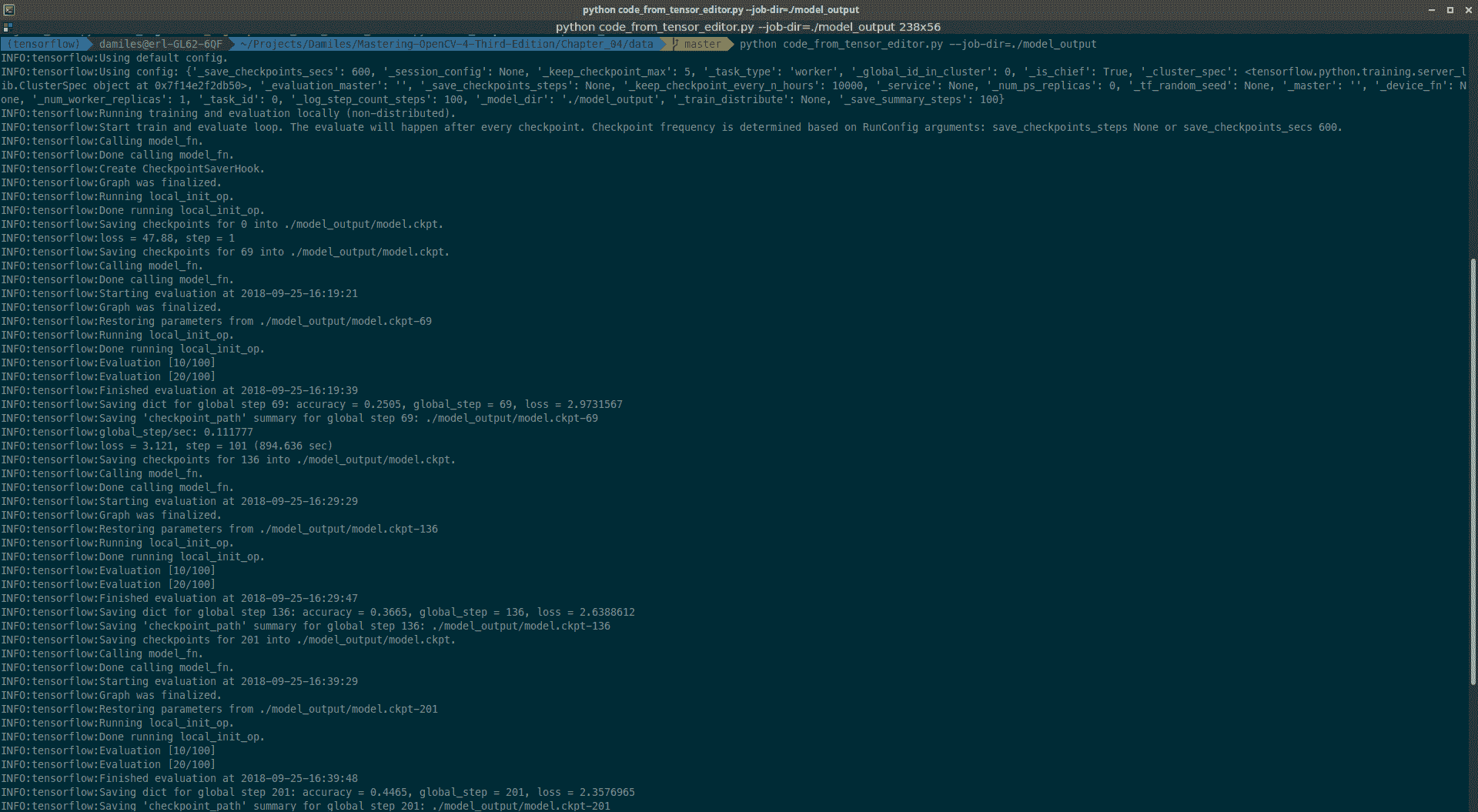
Output of the algorithm training command
我们可以使用 TensorBoard,一个 TensorFlow 工具,它给我们提供了关于训练和图表的信息。 要激活 TensorBoard,我们必须使用以下命令:
tensorboard --logdir ./model_output
在这里,必须确定保存模型和检查点的参数--logdir。 启动 TensorBoard 后,我们可以通过以下 URL 访问它:http://localhost:6006。 这个很棒的工具向我们展示了 TensorFlow 生成的图形,我们可以在其中浏览每个操作和变量,单击每个节点,如我们在下一个屏幕截图中所示:
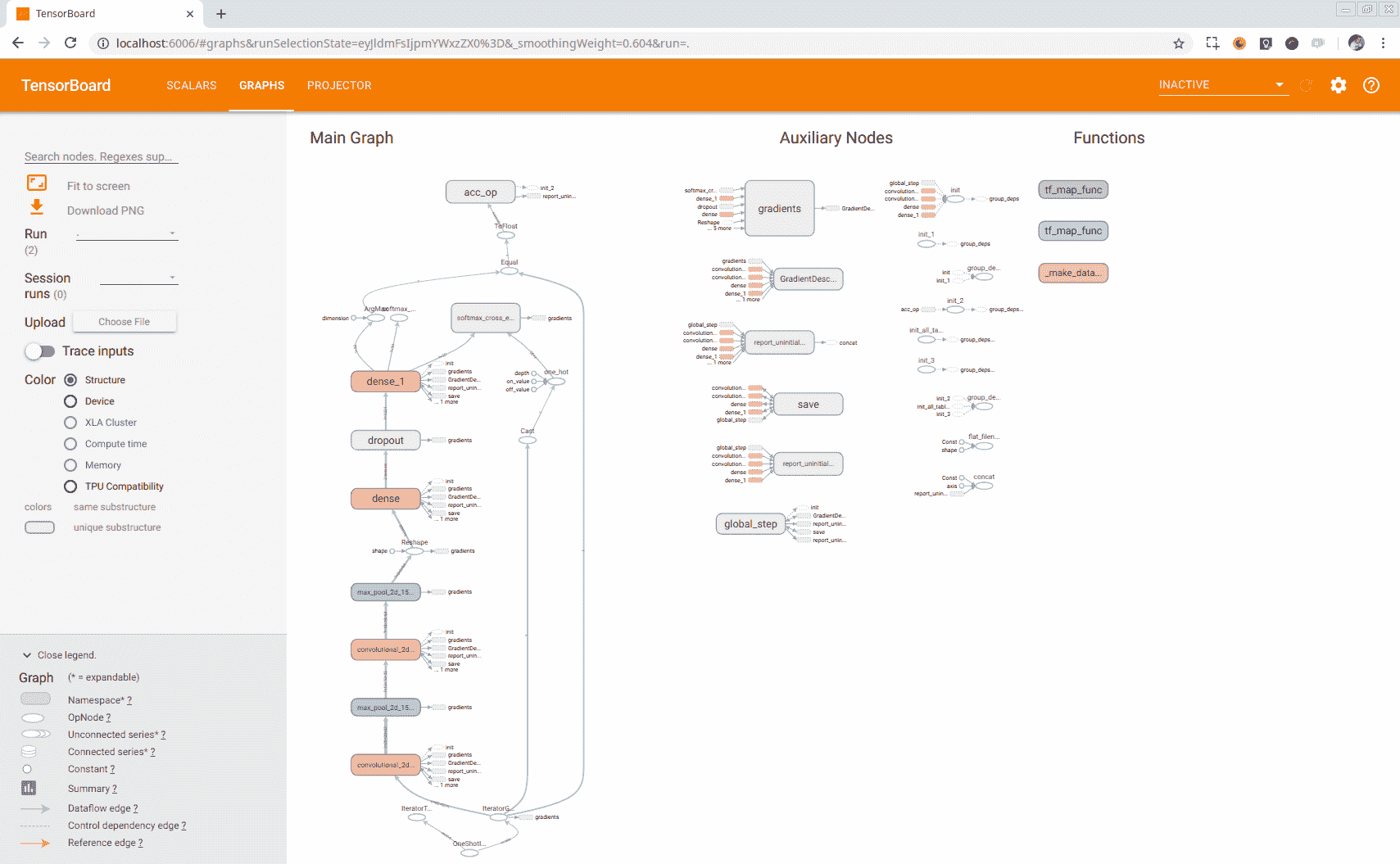
TensorBoard GRAPHS
或者,我们可以研究所获得的结果,例如每个历元步长的损失值或精度度量。 使用每个纪元的训练模型获得的结果显示在以下屏幕截图中:
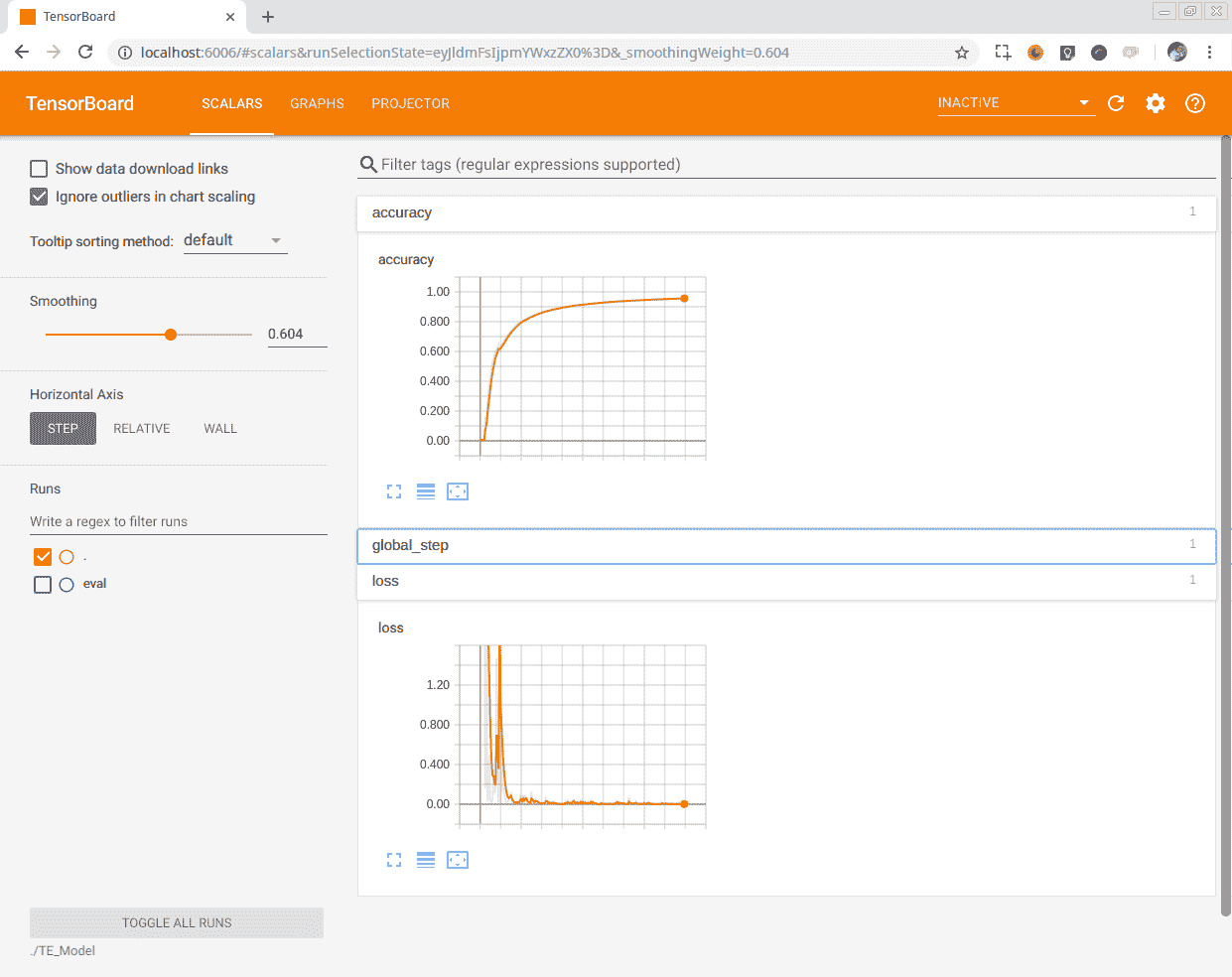
在一台配备 8 GB 内存的 i7 6700HQ 处理器上进行培训需要很长时间,大约 50 个小时;两天多一点的培训。 如果您使用基本的 NVIDIA GPU,此任务可以减少到大约 2-3 个小时。
如果您想在 TensorEditor 中进行训练,可能需要 10-15 分钟,训练完模型后会下载模型,可以下载完整的输出模型,也可以下载冻结优化后的模型。 我们将在下一节为 OpenCV准备模型的过程中介绍冷冻的基本概念。 我们可以在下一个屏幕截图中看到 TensorEditor 中的培训结果:
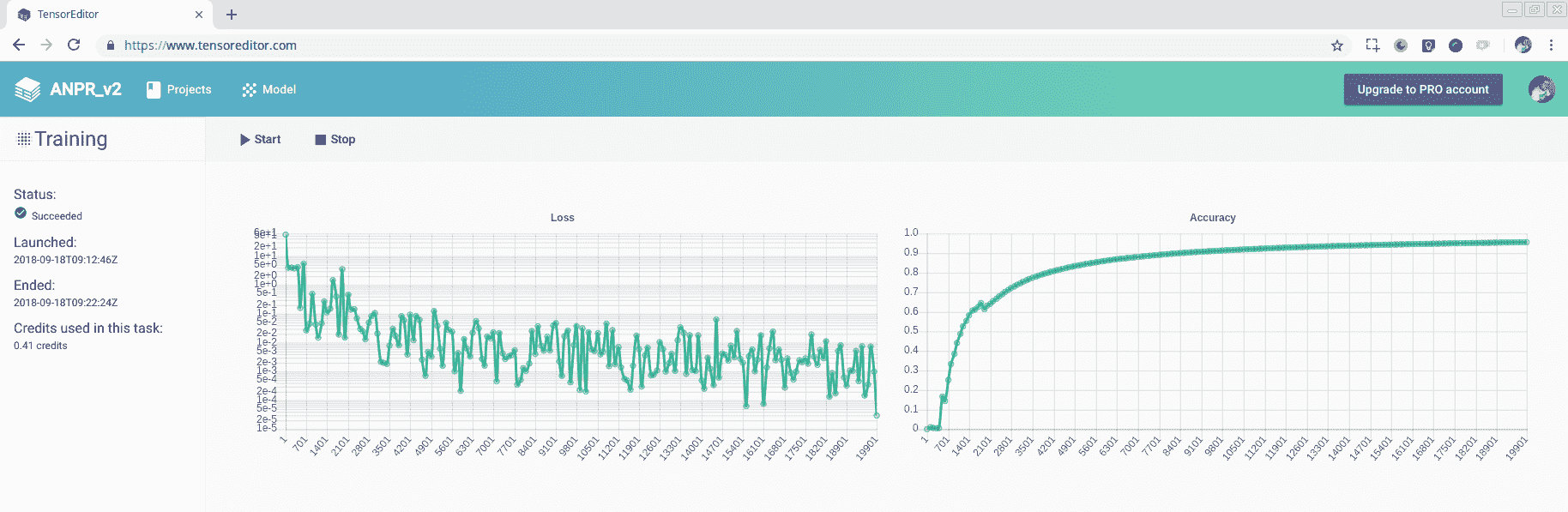
Training in TensorEditor
分析得到的结果,我们获得了 96%左右的准确率水平,比本书第二版中解释的旧算法要好得多,在旧算法中,我们使用特征提取和简单的人工神经网络的准确率只有 92%。
完成培训后,所有模型和变量都存储在启动 TensorFlow 脚本时定义的作业文件夹中。 现在,我们必须准备完成的结果,以便将其集成并导入到 OpenCV 中。
为 OpenCV 准备模型
TensorFlow 在我们训练新模型时会生成多个文件,为存储每个步骤中获得的准确性和损失以及其他指标的事件生成文件;此外,一些文件还会存储每个步骤或检查点获得的变量结果。 这些变量是网络在训练中学习的权重。 但在生产中共享所有这些文件并不方便,因为 OpenCV 无法管理它们。 同时,还有一些节点只用于训练而不用于推理。 我们必须从模型中删除这些节点,例如 Dropout 层或训练输入迭代器。
要把我们的车型投产,我们需要做好以下几个方面的工作:
- 冻结我们的图表
- 移除不需要的节点/层
- 针对推理进行优化
冻结获取图形定义和一组检查点,并将它们合并到单个文件中,将变量转换为常量。 要冻结我们的模型,我们必须移动到保存的模型文件夹中,并执行 TensorFlow 提供的以下脚本:
freeze_graph --input_graph=graph.pbtxt --input_checkpoint=model.ckpt-20000 --output_graph frozen_graph.pb --output_node_names=softmax_tensor
现在,我们生成一个名为Freeze_raph.pb 的新文件,它是合并并冻结的图形。 然后,我们必须删除用于训练目的的输入层。 如果我们使用 TensorBoard 查看图表,我们可以看到我们对第一个卷积神经网络的输入是IteratorGetNext节点,我们必须将其剪切并设置为一个通道的 20x20 像素图像的单层输入。 然后,我们可以使用 TensorFlowTransform_graph应用,该应用允许我们更改图形、剪切或修改 TensorFlow 模型图形。 要删除连接到 ConvNet 的层,我们执行以下代码:
transform_graph --in_graph="frozen_graph.pb" --out_graph="frozen_cut_graph.pb" --inputs="IteratorGetNext" --outputs="softmax_tensor" --transforms='strip_unused_nodes(type=half, shape="1,20,20,1") fold_constants(ignore_errors=true) fold_batch_norms fold_old_batch_norms sort_by_execution_order'
It's very important to add the sort_by_execution_order parameter to ensure that the layers are stored in order in the model graph, to allow OpenCV to correctly import the model. OpenCV sequentially imports the layers from the graph model, checking that all previous layers, operations, or variables are imported; if not, we will receive an import error. TensorEditor doesn't take care of the execution order in the graph to construct and execute it.
执行transform_graph后,我们有一个保存为frozen_cut_graph.pb的新模型。 最后一步需要我们优化图表,删除所有训练操作和层,如辍学。 我们将使用以下命令为生产/推理优化我们的模型;此应用由 TensorFlow 提供:
optimize_for_inference.py --input frozen_cut_graph.pb --output frozen_cut_graph_opt.pb --frozen_graph True --input_names IteratorGetNext --output_names softmax_tensor
它的输出是一个名为frozen_cut_graph_opt.pb的文件。 该文件是我们的最终模型,我们可以在 OpenCV 代码中导入并使用它。
在 OpenCV C++ 代码中导入和使用模型
将深度学习模型导入到 OpenCV 非常容易;我们可以从 TensorFlow、Caffe、Torch 和 Darknet 导入模型。 所有导入都非常相似,但在本章中,我们将学习如何导入 TensorFlow 模型。
要导入 TensorFlow 模型,我们可以使用readNetFromTensorflow方法,该方法只接受两个参数:第一个参数是 Protobuf 格式的模型,第二个参数也是 Protobuf 格式的文本图形定义。 第二个参数不是必需的,但是在我们的例子中,我们必须为推理准备我们的模型,并且我们必须对其进行优化,以便也导入到 OpenCV 中。 然后,我们可以使用以下代码导入模型:
dnn::Net dnn_net= readNetFromTensorflow("frozen_cut_graph_opt.pb");
要对我们的车牌的每个检测到的片段进行分类,我们必须将每个图像片段放入我们的dnn_net中,并获得概率。 以下是对每个数据段进行分类的完整代码:
for(auto& segment : segments){
//Preprocess each char for all images have same sizes
Mat ch=preprocessChar(segment.img);
// DNN classify
Mat inputBlob;
blobFromImage(ch, inputBlob, 1.0f, Size(20, 20), Scalar(), true, false);
dnn_net.setInput(inputBlob);
Mat outs;
dnn_net.forward(outs);
cout << outs << endl;
double max;
Point pos;
minMaxLoc( outs, NULL, &max, NULL, &pos);
cout << "---->" << pos << " prob: " << max << " " << strCharacters[pos.x] << endl;
input->chars.push_back(strCharacters[pos.x]);
input->charsPos.push_back(segment.pos);
}
我们将对这段代码做更多的解释。 首先,我们必须对每个片段进行预处理,以获得 20x20 像素的相同大小的图像。 此预处理图像必须转换为保存在Mat结构中的 BLOB。 要将其转换为 BLOB,我们将使用blobFromImageFunction,该函数可以创建具有可选调整大小、缩放、裁剪或交换通道蓝色和红色的四维数据。 该函数具有以下参数:
void cv::dnn::blobFromImage (
InputArray image,
OutputArray blob,
double scalefactor = 1.0,
const Size & size = Size(),
const Scalar & mean = Scalar(),
bool swapRB = false,
bool crop = false,
int ddepth = CV_32F
)
每一项的定义如下:
image:输入图像(具有一个、三个或四个通道)。blob:输出斑点垫。size:输出图像的空间大小。mean:标量和平均值,从通道中减去。 如果图像具有 BGR 排序,并且swapRB是true,则值应该是(Mean-R,Mean-G,Mean-B)顺序。scalefactor:图像值的乘数。swapRB:指示需要交换三通道图像中的第一个通道和最后一个通道的标志。crop:指示调整大小后是否裁剪图像的标志ddepth:输出深度blob。 选择CV_32F或CV_8U。
可以使用dnn_net.setInput(inputBlob)将生成的 BLOB 作为输入添加到我们的 DNN 中。
一旦为我们的网络设置了输入 blob,我们只需要向前传递输入就可以获得我们的结果。 这就是使用dnn_net.forward(outs)函数的目的,该函数返回带有 Softmax 预测结果的Mat。 得到的结果是一行Mat,其中每一列都是标签;然后,要获得概率最高的标签,我们只需要获得这个Mat的最大位置。 我们可以使用minMaxLoc函数来检索标签值,如果需要,还可以检索概率值。
最后,要关闭 ANPR 应用,我们只需在输入车牌数据中保存新的分段位置和获得的标签。
如果我们执行该应用,我们将获得如下结果:

简略的 / 概括的 / 简易判罪的 / 简易的
在本章中,您学习了车牌自动识别程序的工作原理及其两个重要步骤:车牌定位和车牌识别。
在第一步中,您学习了如何通过查找我们可能有车牌的补丁来分割图像,并使用简单启发式算法和 SVM 算法对有个车牌和没有车牌的补丁进行二进制分类。
在第二步中,您学习了如何使用查找轮廓算法进行分段,使用 TensorFlow 创建深度学习模型,然后训练该模型并将其导入到 OpenCV 中。 您还学习了如何使用增强技术增加数据集中的样本数。
在下一章中,您将学习如何使用特征脸和深度学习创建人脸识别应用。
