七、提取图像特征和描述符
在本章中,我们将讨论特征检测器和描述符,以及不同类型的特征检测器/提取器在图像处理中的各种应用。我们将从定义特征检测器和描述符开始。然后,我们将继续讨论一些流行的特征检测器,如 Harris 角点/SIFT 和 HOG,然后分别使用scikit-image和python-opencv (cv2)库函数讨论它们在图像匹配和目标检测等重要图像处理问题中的应用。
本章涉及的主题如下:
- 特征检测器与描述符,用于从图像中提取特征/描述符
- Harris 角点检测器和 Harris 角点特征在图像匹配中的应用(与 scikit 图像)
- 带有 LoG、DoG 和 DoH 的水滴探测器(带有
scikit-image) - 方向梯度特征直方图的提取
- SIFT、ORB 和简短特征及其在图像匹配中的应用
- 类 Haar 特征及其在人脸检测中的应用
特征检测器与描述符
在图像处理中,(局部)特征是指与图像处理任务相关的一组关键/显著点或信息,它们创建了图像的抽象、更通用(通常更健壮)表示。基于某种标准(例如,检测/提取图像特征的转角、局部最大值/最小值等)从图像中选择一组兴趣点的一系列算法称为特征检测器/提取器。
相反,描述符由一组值组成,用于表示具有特征/兴趣点(例如,HOG 特征)的图像。特征提取也可以被认为是一种将图像转换为集合的操作。。。
哈里斯角检测器
该算法探索窗口在图像中的位置变化时窗口内的强度变化。与仅在一个方向上突然更改强度值的边不同,在所有方向的拐角处,强度值都会发生显著更改。因此,当窗口在拐角处沿任何方向移动(具有良好的定位)时,强度值应发生较大变化;哈里斯角点检测算法利用了这一事实。它不随旋转而变化,但不随缩放而变化(即,在图像进行旋转变换时,从图像中找到的角点保持不变,但在调整图像大小时会发生变化)。在本节中,我们将讨论如何使用scikit-image实现 Harris 角点检测器。
使用 scikit 图像
下一个代码片段显示了如何使用 Harris 角点检测器和scikit-image功能模块中的corner_harris()功能检测图像中的角点:
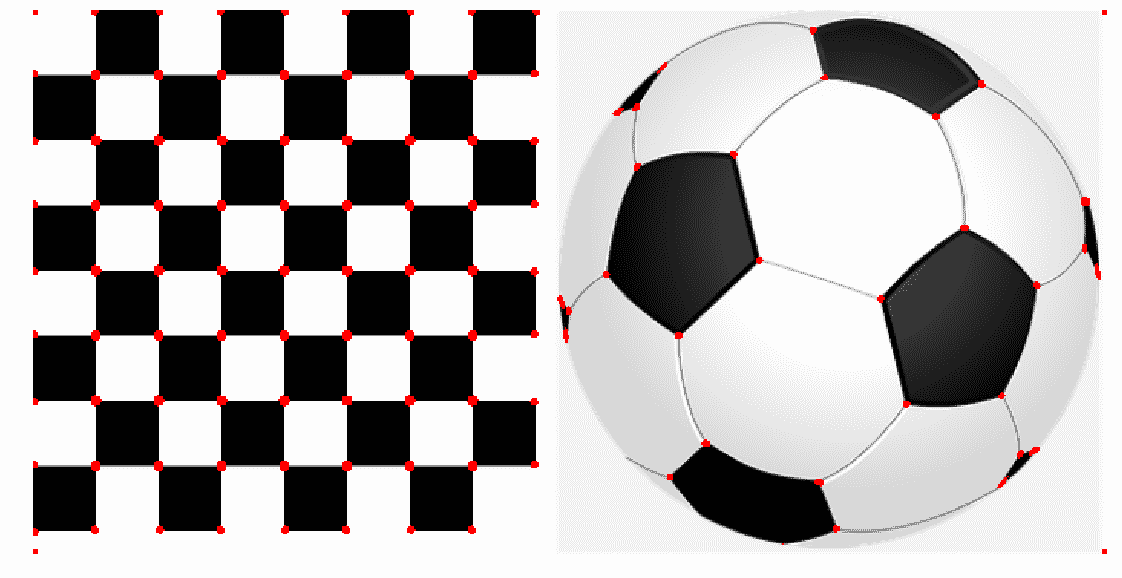
image = imread('../images/chess_football.png') # RGB imageimage_gray = rgb2gray(image)coordinates = corner_harris(image_gray, k =0.001)image[coordinates>0.01*coordinates.max()]=[255,0,0,255]pylab.figure(figsize=(20,10))pylab.imshow(image), pylab.axis('off'), pylab.show()
下一个屏幕截图显示了代码的输出,其中角点被检测为红色点:
亚像素精度
有时,可能需要以最大精度找到拐角。通过 scikit 图像功能模块的corner_subpix()功能,检测到的角点以亚像素精度进行细化。下面的代码演示如何使用此函数。巴黎卢浮宫金字塔作为输入图像,通常先用corner_peaks()计算哈里斯角点,然后用corner_subpix()函数计算角点的亚像素位置,该函数使用统计测试来决定是否接受/拒绝之前用corner_peaks()计算的角点函数。我们需要定义函数用于搜索角点的邻域(窗口)的大小:
image = imread('../images/pyramids2.jpg')
image_gray = rgb2gray(image)
coordinates = corner_harris(image_gray, k =0.001)
coordinates[coordinates > 0.03*coordinates.max()] = 255 # threshold for an optimal value, depends on the image
corner_coordinates = corner_peaks(coordinates)
coordinates_subpix = corner_subpix(image_gray, corner_coordinates, window_size=11)
pylab.figure(figsize=(20,20))
pylab.subplot(211), pylab.imshow(coordinates, cmap='inferno')
pylab.plot(coordinates_subpix[:, 1], coordinates_subpix[:, 0], 'r.', markersize=5, label='subpixel')
pylab.legend(prop={'size': 20}), pylab.axis('off')
pylab.subplot(212), pylab.imshow(image, interpolation='nearest')
pylab.plot(corner_coordinates[:, 1], corner_coordinates[:, 0], 'bo', markersize=5)
pylab.plot(coordinates_subpix[:, 1], coordinates_subpix[:, 0], 'r+', markersize=10), pylab.axis('off')
pylab.tight_layout(), pylab.show()
接下来的两个屏幕截图显示了代码的输出。在第一个屏幕截图中,Harris 角点用黄色像素标记,精细的亚像素角点用红色像素标记。在第二个屏幕截图中,检测到的角点用蓝色像素和亚像素(同样是红色像素)绘制在原始输入图像的顶部:

一种应用——图像匹配
一旦我们检测到图像中的兴趣点,最好知道如何在同一对象的不同图像上匹配这些点。例如,以下列表显示了匹配两个此类图像的一般方法:
- 计算感兴趣的点(例如,使用 Harris 角点检测器的角点)
- 考虑每个关键点周围的区域(窗口)
- 从区域中,为每个图像的每个关键点计算一个局部特征描述符,并进行规格化
- 匹配两幅图像中计算的局部描述符(例如,使用欧几里德距离)
哈里斯角点可以用来匹配两幅图像;下一节将给出一个示例
基于 RANSAC 算法和 Harris 角点特征的鲁棒图像匹配
在本例中,我们将匹配图像及其仿射变换版本;它们可以被视为是从不同的观点出发的。以下步骤描述了图像匹配算法:
- 首先,我们将计算两幅图像中的兴趣点或 Harris 角点。
- 将考虑点周围的小空间,然后使用平方差的加权和计算点之间的对应关系。此度量不是非常健壮,仅在视点发生轻微变化时可用。
- 一旦找到对应,将获得一组源坐标和相应的目标坐标;它们用于估计两幅图像之间的几何变换。
-
用坐标简单地估计参数是不够的,许多对应关系可能是错误的。
-
使用随机样本一致性(RANSAC)算法对参数进行稳健估计,首先将点分类为
inliers和outliers,然后在忽略outliers的情况下将模型拟合到inliers,以找到与仿射变换一致的匹配。
下一个代码块显示如何使用 Harris 角点功能实现图像匹配:
temple = rgb2gray(img_as_float(imread('../images/temple.jpg')))
image_original = np.zeros(list(temple.shape) + [3])
image_original[..., 0] = temple
gradient_row, gradient_col = (np.mgrid[0:image_original.shape[0], 0:image_original.shape[1]] / float(image_original.shape[0]))
image_original[..., 1] = gradient_row
image_original[..., 2] = gradient_col
image_original = rescale_intensity(image_original)
image_original_gray = rgb2gray(image_original)
affine_trans = AffineTransform(scale=(0.8, 0.9), rotation=0.1, translation=(120, -20))
image_warped = warp(image_original, affine_trans .inverse, output_shape=image_original.shape)
image_warped_gray = rgb2gray(image_warped)
使用 Harris 角点度量提取角点:
coordinates = corner_harris(image_original_gray)
coordinates[coordinates > 0.01*coordinates.max()] = 1
coordinates_original = corner_peaks(coordinates, threshold_rel=0.0001, min_distance=5)
coordinates = corner_harris(image_warped_gray)
coordinates[coordinates > 0.01*coordinates.max()] = 1
coordinates_warped = corner_peaks(coordinates, threshold_rel=0.0001, min_distance=5)
确定亚像素角点位置:
coordinates_original_subpix = corner_subpix(image_original_gray, coordinates_original, window_size=9)
coordinates_warped_subpix = corner_subpix(image_warped_gray, coordinates_warped, window_size=9)
def gaussian_weights(window_ext, sigma=1):
y, x = np.mgrid[-window_ext:window_ext+1, -window_ext:window_ext+1]
g_w = np.zeros(y.shape, dtype = np.double)
g_w[:] = np.exp(-0.5 * (x**2 / sigma**2 + y**2 / sigma**2))
g_w /= 2 * np.pi * sigma * sigma
return g_w
根据到中心像素的距离对像素进行加权,计算扭曲图像中所有角点的平方差之和,并使用具有最小 SSD 的角点作为对应:
def match_corner(coordinates, window_ext=3):
row, col = np.round(coordinates).astype(np.intp)
window_original = image_original[row-window_ext:row+window_ext+1, col-window_ext:col+window_ext+1, :]
weights = gaussian_weights(window_ext, 3)
weights = np.dstack((weights, weights, weights))
SSDs = []
for coord_row, coord_col in coordinates_warped:
window_warped = image_warped[coord_row-window_ext:coord_row+window_ext+1,
coord_col-window_ext:coord_col+window_ext+1, :]
if window_original.shape == window_warped.shape:
SSD = np.sum(weights * (window_original - window_warped)**2)
SSDs.append(SSD)
min_idx = np.argmin(SSDs) if len(SSDs) > 0 else -1
return coordinates_warped_subpix[min_idx] if min_idx >= 0 else [None]
使用平方差的简单加权和查找对应关系:
source, destination = [], []
for coordinates in coordinates_original_subpix:
coordinates1 = match_corner(coordinates)
if any(coordinates1) and len(coordinates1) > 0 and not all(np.isnan(coordinates1)):
source.append(coordinates)
destination.append(coordinates1)
source = np.array(source)
destination = np.array(destination)
使用所有坐标估计仿射变换模型:
model = AffineTransform()
model.estimate(source, destination)
使用 RANSAC 稳健估计仿射变换模型:
model_robust, inliers = ransac((source, destination), AffineTransform, min_samples=3, residual_threshold=2, max_trials=100)
outliers = inliers == False
比较True和估计的变换参数:
print(affine_trans.scale, affine_trans.translation, affine_trans.rotation)
# (0.8, 0.9) [ 120\. -20.] 0.09999999999999999
print(model.scale, model.translation, model.rotation)
# (0.8982412101241938, 0.8072777593937368) [ -20.45123966 114.92297156] -0.10225420334222493
print(model_robust.scale, model_robust.translation, model_robust.rotation)
# (0.9001524425730119, 0.8000362790749188) [ -19.87491292 119.83016533] -0.09990858564132575
将通信可视化:
fig, axes = pylab.subplots(nrows=2, ncols=1, figsize=(20,15))
pylab.gray()
inlier_idxs = np.nonzero(inliers)[0]
plot_matches(axes[0], image_original_gray, image_warped_gray, source, destination, np.column_stack((inlier_idxs, inlier_idxs)), matches_color='b')
axes[0].axis('off'), axes[0].set_title('Correct correspondences', size=20)
outlier_idxs = np.nonzero(outliers)[0]
plot_matches(axes[1], image_original_gray, image_warped_gray, source, destination, np.column_stack((outlier_idxs, outlier_idxs)), matches_color='row')
axes[1].axis('off'), axes[1].set_title('Faulty correspondences', size=20)
fig.tight_layout(), pylab.show()
下面的屏幕截图显示了代码块的输出。找到的正确对应用蓝线显示,而错误对应用红线显示:


Blob 探测器,带有 LoG、DoG 和 DoH
在图像中,水滴被定义为暗区域上的亮区域或亮区域上的暗区域。在本节中,我们将讨论如何使用以下三种算法在图像中实现斑点特征检测。输入图像是彩色(RGB)蝴蝶图像。
高斯拉普拉斯(对数)
在第 3 章、卷积和频域滤波中,我们看到图像与滤波器的互相关可以看作是模式匹配;也就是说,将一个(小的)模板图像(我们想要找到的)与图像中的所有局部区域进行比较。斑点检测的关键思想来自这一事实。在上一章中,我们已经看到了带过零的对数滤波器如何用于边缘检测。LoG 还可以利用尺度空间的概念,通过搜索 LoG 的三维(位置+尺度)极值来寻找尺度不变区域。如果拉普拉斯函数的尺度(对数滤波器的σ)与 blob 的尺度匹配,则拉普拉斯函数响应的幅度在 blob 的中心达到最大值。采用这种方法,对数卷积图像以逐渐增加的σ进行计算,并堆叠成立方体。BLOB 对应于此多维数据集中的局部最大值。这种方法只检测黑暗背景上的明亮斑点。它是准确的,但速度很慢(特别是对于检测较大的斑点)。
高斯差分(DoG)
LoG 方法近似于 DoG 方法,因此速度更快。图像用增加的σ值进行平滑(使用高斯),两个连续平滑图像之间的差异叠加在一个立方体中。这种方法再次检测黑暗背景上的亮斑。它比日志更快,但精确度较低,尽管较大的斑点检测仍然昂贵。
黑森行列式(DoH)
DoH 方法是所有这些方法中最快的。它通过计算图像 Hessian 行列式矩阵的最大值来检测斑点。水滴的大小对检测速度没有任何影响。该方法既能检测出暗背景上的亮斑,又能检测出亮背景上的暗斑,但不能准确地检测出小斑。
下一个代码块演示如何使用 scikit image 实现上述三种算法:
from numpy import sqrt
from skimage.feature import blob_dog, blob_log, blob_doh
im = imread('../images/butterfly.png')
im_gray = rgb2gray(im)
log_blobs = blob_log(im_gray, max_sigma=30, num_sigma=10, threshold=.1)
log_blobs[:, 2] = sqrt(2) * log_blobs[:, 2] # Compute radius in the 3rd column
dog_blobs = blob_dog(im_gray, max_sigma=30, threshold=0.1)
dog_blobs[:, 2] = sqrt(2) * dog_blobs[:, 2]
doh_blobs = blob_doh(im_gray, max_sigma=30, threshold=0.005)
list_blobs = [log_blobs, dog_blobs, doh_blobs]
color, titles = ['yellow', 'lime', 'red'], ['Laplacian of Gaussian', 'Difference of Gaussian', 'Determinant of Hessian']
sequence = zip(list_blobs, colors, titles)
fig, axes = pylab.subplots(2, 2, figsize=(20, 20), sharex=True, sharey=True)
axes = axes.ravel()
axes[0].imshow(im, interpolation='nearest')
axes[0].set_title('original image', size=30), axes[0].set_axis_off()
for idx, (blobs, color, title) in enumerate(sequence):
axes[idx+1].imshow(im, interpolation='nearest')
axes[idx+1].set_title('Blobs with ' + title, size=30)
for blob in blobs:
y, x, row = blob
col = pylab.Circle((x, y), row, color=color, linewidth=2, fill=False)
axes[idx+1].add_patch(col), axes[idx+1].set_axis_off()
pylab.tight_layout(), pylab.show()
下面的屏幕截图显示了代码的输出,即使用不同算法检测到的斑点:
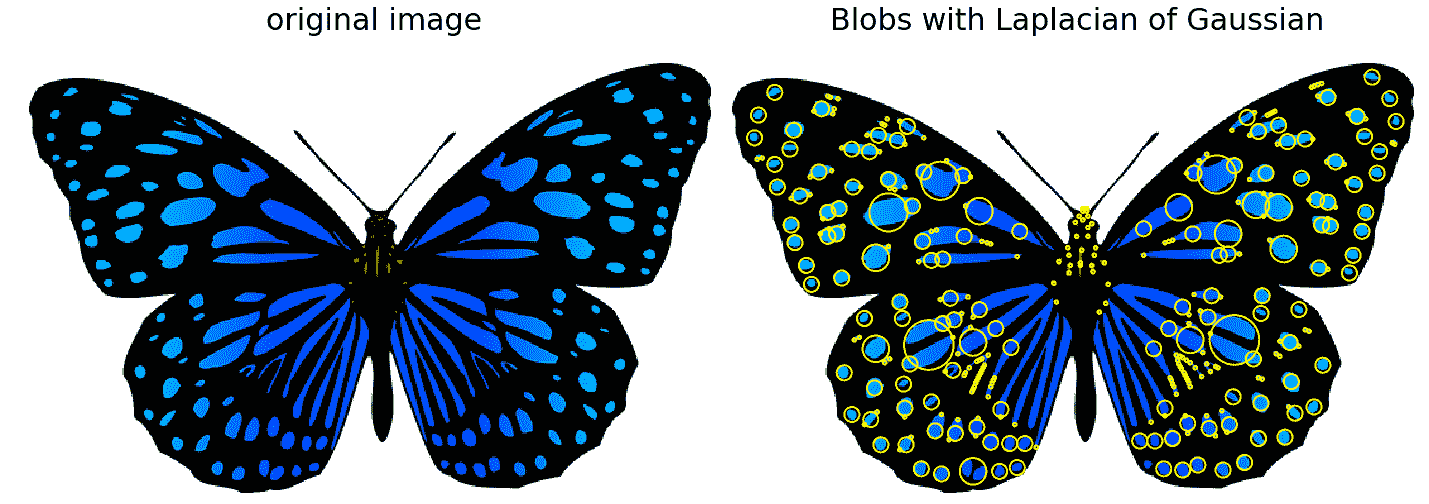
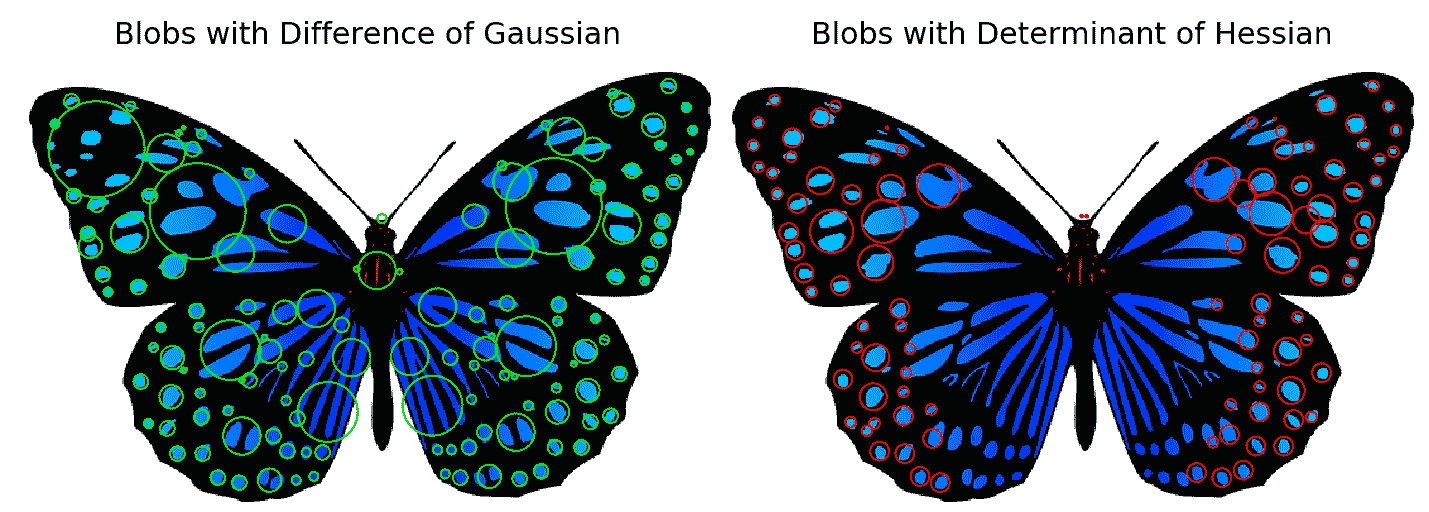
角点和斑点特征都具有重复性、显著性和局部性。
定向梯度直方图
用于目标检测的一种流行特征描述符是定向梯度的直方图(HOG。在本节中,我们将讨论如何从图像计算 HOG 描述符。
计算 HOG 描述符的算法
以下步骤描述了该算法:
- 如果愿意,可以对图像进行全局规格化
- 计算水平和垂直梯度图像
- 计算梯度直方图
- 跨块标准化
- 展平为特征描述符向量
HOG 描述符是使用该算法最终得到的归一化块描述符
使用 scikit 图像计算 HOG 描述符
现在,让我们使用 scikit 图像功能模块的hog()函数计算 HOG 描述符,并将其可视化:
from skimage.feature import hogfrom skimage import exposureimage = rgb2gray(imread('../images/cameraman.jpg'))fd, hog_image = hog(image, orientations=8, pixels_per_cell=(16, 16), cells_per_block=(1, 1), visualize=True) print(image.shape, len(fd))# ((256L, 256L), 2048)fig, (axes1, axes2) = pylab.subplots(1, 2, figsize=(15, 10), sharex=True, sharey=True)axes1.axis('off'), axes1.imshow(image, cmap=pylab.cm.gray), axes1.set_title('Input image')
现在,让我们重新缩放直方图以更好地显示:
hog_image_rescaled = exposure.rescale_intensity(hog_image, in_range=(0, 10))axes2.axis('off'), ...
尺度不变特征变换
尺度不变特征变换(SIFT描述符)为图像区域提供了一种替代表示。它们对于匹配图像非常有用。如前所述,当要匹配的图像本质相似时(关于标度、方向等),简单的角点检测器工作良好。但是,如果它们具有不同的尺度和旋转,则需要使用 SIFT 描述符来匹配它们。SIFT 不仅具有尺度不变性,而且在图像的旋转、照明和视点也发生变化时,仍然可以获得良好的结果
让我们讨论 SIFT 算法中涉及的主要步骤,SIFT 算法将图像内容转换为对平移、旋转、缩放和其他成像参数不变的局部特征坐标。
SIFT 描述符的计算算法
- 尺度空间极值检测:搜索多个尺度和图像位置,位置和特征尺度由 DoG 检测器给出
- 关键点定位:基于稳定性度量选择关键点,通过消除低对比度和边缘关键点,仅保留强兴趣点
- 方向分配:计算每个关键点区域的最佳方向,有助于匹配的稳定性
- 关键点描述符计算:使用选定比例和旋转的局部图像梯度来描述每个关键点区域
如前所述,SIFT 对于光照的微小变化(由于梯度和归一化)、姿势(由于。。。
使用 opencv 和 opencv contrib
为了能够与python-opencv一起使用 SIFT 功能,我们首先需要按照此链接的说明安装opencv-contrib:https://pypi.org/project/opencv-contrib-python/ 。下一个代码块演示如何检测 SIFT 关键点,并使用输入的蒙娜丽莎图像绘制它们
我们将首先构造一个 SIFT 对象,然后使用detect()方法计算图像中的关键点。每个关键点都是一个特殊的特征,并且具有多个属性。例如,它的(x,y)坐标、角度(方向)、响应(关键点的强度)、有意义邻域的大小等等。
然后,我们将使用cv2中的drawKeyPoints()函数在检测到的关键点周围绘制小圆圈。如果将cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS标志应用于函数,它将绘制一个具有关键点大小的圆及其方向。为了同时计算关键点和描述符,我们将使用函数detectAndCompute():
# make sure the opencv version is 3.3.0 with
# pip install opencv-python==3.3.0.10 opencv-contrib-python==3.3.0.10
import cv2
print(cv2.__version__)
# 3.3.0
img = cv2.imread('../images/monalisa.jpg')
gray= cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
sift = cv2.xfeatures2d.SIFT_create()
kp = sift.detect(gray,None) # detect SIFT keypoints
img = cv2.drawKeypoints(img,kp, None, flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imshow("Image", img);
cv2.imwrite('me5_keypoints.jpg',img)
kp, des = sift.detectAndCompute(gray,None) # compute the SIFT descriptor
下面是代码的输出,输入蒙娜丽莎图像,以及在其上绘制的计算的 SIFT 关键点,以及方向:

应用程序–使用简短、筛选和 ORB 匹配图像
在最后一节中,我们讨论了如何检测 SIFT 关键点。在本节中,我们将为图像引入更多的特征描述符,即简短(一个简短的二进制描述符)和 ORB(一个有效的 SIFT 替代品)。所有这些描述符也可以用于图像匹配和对象检测,我们将很快看到
使用简短的二进制描述符将图像与 scikit 图像匹配
简短描述符具有相对较少的位,可以使用一组强度差测试进行计算。作为一个较短的二进制描述符,它具有较低的内存占用,使用该描述符进行匹配在汉明距离度量下非常有效。简单地说,通过检测不同尺度下的特征可以获得所需的尺度不变性,尽管它不提供旋转不变性。下一个代码块演示如何使用 scikit 图像函数计算简短的二进制描述符。用于匹配的输入图像是灰度 Lena 图像及其仿射变换版本
现在让我们编写以下代码:
from skimage import transform as transform
from skimage.feature import (match_descriptors, corner_peaks, corner_harris, plot_matches, BRIEF)
img1 = rgb2gray(imread('../images/lena.jpg')) #data.astronaut())
affine_trans = transform.AffineTransform(scale=(1.2, 1.2), translation=(0,-100))
img2 = transform.warp(img1, affine_trans)
img3 = transform.rotate(img1, 25)
coords1, coords2, coords3 = corner_harris(img1), corner_harris(img2), corner_harris(img3)
coords1[coords1 > 0.01*coords1.max()] = 1
coords2[coords2 > 0.01*coords2.max()] = 1
coords3[coords3 > 0.01*coords3.max()] = 1
keypoints1 = corner_peaks(coords1, min_distance=5)
keypoints2 = corner_peaks(coords2, min_distance=5)
keypoints3 = corner_peaks(coords3, min_distance=5)
extractor = BRIEF()
extractor.extract(img1, keypoints1)
keypoints1, descriptors1 = keypoints1[extractor.mask], extractor.descriptors
extractor.extract(img2, keypoints2)
keypoints2, descriptors2 = keypoints2[extractor.mask], extractor.descriptors
extractor.extract(img3, keypoints3)
keypoints3, descriptors3 = keypoints3[extractor.mask], extractor.descriptors
matches12 = match_descriptors(descriptors1, descriptors2, cross_check=True)
matches13 = match_descriptors(descriptors1, descriptors3, cross_check=True)
fig, axes = pylab.subplots(nrows=2, ncols=1, figsize=(20,20))
pylab.gray(), plot_matches(axes[0], img1, img2, keypoints1, keypoints2, matches12)
axes[0].axis('off'), axes[0].set_title("Original Image vs. Transformed Image")
plot_matches(axes[1], img1, img3, keypoints1, keypoints3, matches13)
axes[1].axis('off'), axes[1].set_title("Original Image vs. Transformed Image"), pylab.show()
下面的屏幕截图显示了代码块的输出以及两幅图像之间的简短关键点如何匹配:


使用 scikit 图像匹配 ORB 特征检测器和二进制描述符
让我们编写一段代码来演示 ORB 特征检测和二进制描述符算法。该算法采用了一种面向对象的快速检测方法和旋转的简短描述子。与 BRIEF 相比,ORB 具有更大的尺度和旋转不变性,但即使这样,也应用了更有效的汉明距离度量进行匹配。因此,在考虑实时应用时,此方法优于简单方法:
from skimage import transform as transformfrom skimage.feature import (match_descriptors, ORB, plot_matches)img1 = rgb2gray(imread('../images/me5.jpg'))img2 = transform.rotate(img1, 180)affine_trans = transform.AffineTransform(scale=(1.3, 1.1), ...
使用蛮力匹配 python opencv 与 ORB 特性匹配
在本节中,我们将演示如何使用opencv的蛮力匹配器匹配两个图像描述符。在这种情况下,来自一个图像的特征描述符与另一个图像中的所有特征匹配(使用一些距离度量),并返回最接近的特征。我们将使用带有 ORB 描述符的BFMatcher()函数来匹配两个图书图像:
img1 = cv2.imread('../images/books.png',0) # queryImage
img2 = cv2.imread('../images/book.png',0) # trainImage
# Create a ORB detector object
orb = cv2.ORB_create()
# find the keypoints and descriptors
kp1, des1 = orb.detectAndCompute(img1,None)
kp2, des2 = orb.detectAndCompute(img2,None)
# create a BFMatcher object
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
# Match descriptors.
matches = bf.match(des1, des2)
# Sort them in the order of their distance.
matches = sorted(matches, key = lambda x:x.distance)
# Draw first 20 matches.
img3 = cv2.drawMatches(img1,kp1,img2,kp2,matches[:20], None, flags=2)
pylab.figure(figsize=(20,10)), pylab.imshow(img3), pylab.show()
以下屏幕截图显示了代码块中使用的输入图像:

以下屏幕截图显示了代码块计算的前 20 个 ORB 关键点匹配:

使用 SIFT 描述符的蛮力匹配和使用 OpenCV 的比率测试
两幅图像之间的 SIFT 关键点通过识别其最近邻进行匹配。但在某些情况下,由于噪音等因素,第二个最接近的匹配可能更接近第一个。在这种情况下,我们计算最近距离与第二最近距离的比率,并检查其是否高于 0.8。如果比率大于 0.8,则表示它们被拒绝。
这有效地消除了大约 90%的错误匹配,只有大约 5%的正确匹配(根据 SIFT 纸张)。让我们使用knnMatch()功能来获得一个关键点的k=2最佳匹配;我们还将应用比率测试:
# make sure the opencv version is 3.3.0 with# pip install opencv-python==3.3.0.10 ...
类哈尔特征
类 Haar 特征是用于目标检测的非常有用的图像特征。Viola 和 Jones 在第一台实时人脸检测仪中引入了这种技术。利用积分图像,可以在恒定时间内有效地计算任意大小(尺度)的类 Haar 特征。计算速度是 Haar-like 特征相对于大多数其他特征的关键优势。这些特性就像第 3 章、卷积和频域滤波中介绍的卷积核(矩形滤波器)。每个特征对应于一个单独的值,该值通过从黑色矩形下的像素总和减去白色矩形下的像素总和计算得出。下图显示了不同类型的类 Haar 特征,以及用于人脸检测的重要类 Haar 特征:
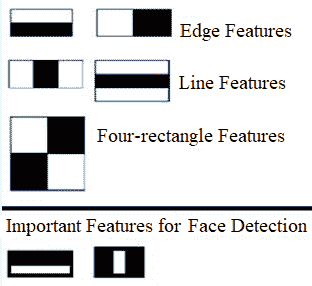
这里显示的人脸检测的第一个和第二个重要特征似乎集中在以下事实上:眼睛区域通常比鼻子和脸颊区域暗,眼睛也比鼻梁暗。下一节使用 scikit 图像可视化 Haar 样特征。
带有 scikit 图像的类 Haar 特征描述符
在本节中,我们将可视化不同类型的 Haar-like 特征描述符,其中有五种不同类型。描述符的值等于蓝色和红色强度值之和之间的差值。
下一个代码块显示了如何使用 scikit 图像特征模块的haar_like_feature_coord()和draw_haar_like_feature()函数来可视化不同类型的 Haar 特征描述符:
from skimage.feature import haar_like_feature_coordfrom skimage.feature import draw_haar_like_featureimages = [np.zeros((2, 2)), np.zeros((2, 2)), np.zeros((3, 3)),np.zeros((3, 3)), np.zeros((2, 2))]feature_types = ['type-2-x', 'type-2-y', 'type-3-x', ...
应用–具有类 Haar 特征的人脸检测
使用 Viola-Jones 人脸检测算法,可以使用这些类似 Haar 的特征在图像中检测人脸。每个 Haar-like 特征只是一个弱分类器,因此需要大量的 Haar-like 特征才能准确地检测人脸。使用积分图像计算每个类 Haar 内核的所有可能大小和位置的大量类 Haar 特征。然后使用 AdaBoost 集成分类器从大量特征中选择重要特征,并在训练阶段将其组合成强分类器模型。然后使用学习的模型对具有选定特征的人脸区域进行分类
图像中的大多数区域通常是非人脸区域。因此,首先检查窗口是否不是面区域。如果不是,则在一次拍摄中丢弃,并在可能发现人脸的不同区域进行检查。为了实现这一思想,引入了级联分类器的概念。与在一个窗口上应用大量的特征不同,这些特征被分组到分类器的不同阶段,并逐个应用。(前几个阶段包含的功能非常少)。如果某个窗口在第一阶段出现故障,它将被丢弃,并且不考虑其上的其余功能。如果通过,则应用特征的第二阶段,依此类推。面区域对应于通过所有阶段的窗口。这些概念将在第 9 章、图像处理中的经典机器学习方法中详细讨论。
基于预训练分类器和 Haar 级联特征的 OpenCV 人脸/眼睛检测
OpenCV 配有一个培训师和一个检测器。在本节中,我们将演示使用预先训练的人脸、眼睛、微笑等分类器进行检测(跳过训练模型)。OpenCV 已经包含了许多已经训练过的模型;我们将使用它们,而不是从头开始训练分类器。这些预先训练好的分类器被序列化为 XML 文件,并附带 OpenCV 安装(可以在opencv/data/haarcascades/文件夹中找到)
为了从输入图像中检测人脸,首先需要加载所需的 XML 分类器,然后加载输入图像(在灰度模式下)。图像中的面可以是。。。
总结
在本章中,我们讨论了一些重要的特征检测和提取技术,以使用 Python 的scikit-image和cv2 (python-opencv)库从图像中计算不同类型的特征描述符。我们首先介绍了图像的局部特征检测器和描述符的基本概念,以及它们所需要的特性。然后,我们讨论了 Harris 角点检测器来检测图像的角点兴趣点,并使用它们匹配两幅图像(从不同的视点捕获相同的对象)。接下来,我们讨论了使用 LoG/DoG/DoH 过滤器的 blob 检测。接下来,我们讨论了 HOG、SIFT、ORB、简短的二进制检测器/描述符以及如何将图像与这些特征匹配。最后,我们讨论了类 Haar 特征和 Viola-Jones 算法的人脸检测。在本章结束时,您应该能够使用 Python 库计算图像的不同特征/描述符。此外,您还应该能够使用不同类型的特征描述符(例如,SIFT、ORB 等)匹配图像并使用 Python 从包含人脸的图像中检测人脸。
在下一章中,我们将讨论图像分割。
问题
- 使用
cv2实现亚像素精度的 Harris 角点检测器。 - 使用
cv2使用几个不同的预先训练好的 Haar Cascade 分类器,尝试从图像中检测多张人脸。 - 使用基于 FLANN 的近似最近邻匹配器代替
BFMatcher将图像与具有cv2的书籍进行匹配。 - 计算 SURF 关键点并使用它们与
cv2进行图像匹配
进一步阅读
- http://scikit-image.org/docs/dev/api/skimage.feature.html
- https://docs.opencv.org/3.1.0/da/df5/tutorial_py_sift_intro.html
- https://sandipanweb.wordpress.com/2017/10/22/feature-detection-with-harris-corner-detector-and-matching-images-with-feature-descriptors-in-python/
- https://sandipanweb.wordpress.com/2018/06/30/detection-of-a-human-object-with-hog-descriptor-features-using-svm-primal-quadprog-implementation-using-cvxopt-in-python/
- http://vision.stanford.edu/teaching/cs231b_spring1213/slides/HOG_2011_Stanford.pdf
- http://cvgl.stanford.edu/teaching/cs231a_winter1415/lecture/lecture10_detector_descriptors_2015.pdf
- https://www.cis.rit.edu/~cnspci/references/dip/feature_extraction/harris1988.pdf
- https://www.cs.ubc.ca/~lowe/papers/ijcv04.pdf
- https://www.cs.cmu.edu/~efros/courses/LBMV07/Papers/viola-cvpr-01.pdf
- https://lear.inrialpes.fr/people/triggs/pubs/Dalal-cvpr05.pdf**
