十二、OpenCV 深度学习
深度学习是一种最先进的机器学习形式,在图像分类和语音识别中达到了最高的准确率。 深度学习也被用于其他领域,如机器人和具有强化学习的人工智能。 这就是 OpenCV 做出重大努力将深度学习纳入其核心的主要原因。 我们将学习 OpenCV 深度学习界面的基本用法,并了解如何在两个用例中使用它们:对象检测和人脸检测。
在本章中,我们将学习深度学习的基础知识,并了解如何在 OpenCV 中使用深度学习。 为了达到我们的目标,我们将使用You Only Look Once((YOLO)算法学习目标检测和分类。
本章将介绍以下主题:
- 什么是深度学习?
- OpenCV 如何使用深度学习和实施深度学习神经网络(NNs)
- YOLO 提出了一种非常快速的深度学习目标检测算法
- 基于单镜头检测器的人脸检测
技术要求
要轻松阅读本章,需要安装 OpenCV 并编译深度学习模块。 如果没有此模块,您将无法编译和运行示例代码。
拥有支持 CUDA 的 NVIDIA GPU 非常有用。 您可以在 OpenCV 上启用 CUDA 以提高训练和检测的速度。
最后,您可以从https://github.com/PacktPublishing/Building-Computer-Vision-Projects-with-OpenCV4-and-CPlusPlus/tree/master/Chapter12下载本章使用的代码。
请查看以下视频,了解实际操作中的代码: http://bit.ly/2SmbWf7
深度学习入门
深度学习是当今关于图像分类和语音识别的科学论文中最常见的内容。 这是机器学习的一个子领域,基于传统的神经网络,并受到大脑结构的启发。 要理解这项技术,了解神经网络是什么以及它是如何工作的是非常重要的。
什么是神经网络?我们如何从数据中学习?
神经网络的灵感来自大脑的结构,在大脑中,多个神经元相互连接,形成一个网络。 每个神经元都有多个输入和多个输出,就像生物神经元一样。
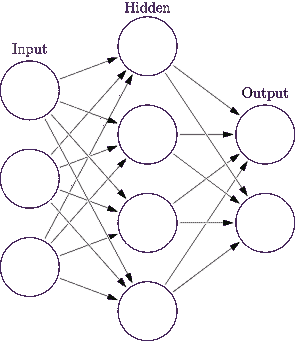
这个网络是分层分布的,每一层都包含许多神经元,这些神经元与前一层的所有神经元相连。 它总是有一个输入层和一个输出层,输入层通常由描述输入图像或数据的要素组成,输出层通常由分类结果组成。 其他中间层称为隐藏层。 下图显示了一个基本的三层神经网络,其中输入层包含三个神经元,输出层包含两个神经元,一个隐藏层包含四个神经元:
神经元是神经网络的基本元素,它使用一个简单的数学公式,如下图所示:
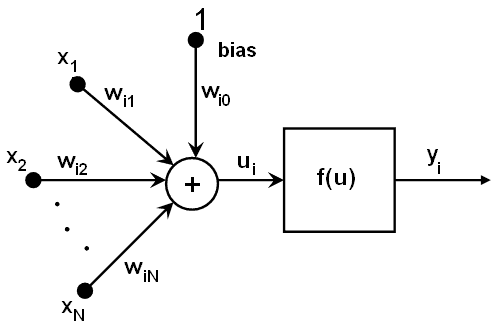
正如我们所看到的,对于每个神经元i,我们数学地将前一个神经元的所有输出(即神经元i(x1,x2...)的输出按权重(wi1,wi2...)相加。)。 加上偏置值,结果是激活函数的自变量f。 最终结果是i神经元的输出:
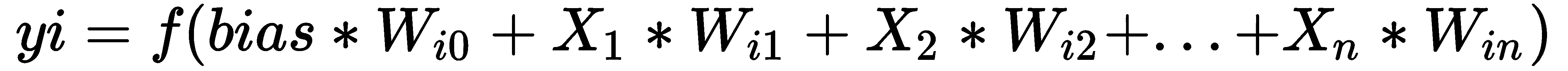
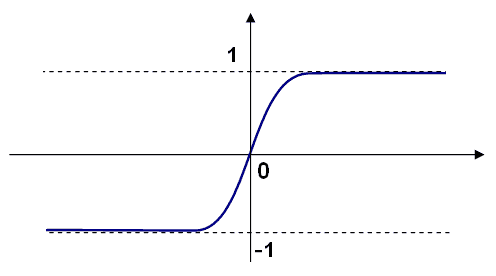
经典神经网络中最常见的激活函数(f)是 Sigmoid 函数或线性函数。 最常用的是 Sigmoid 函数,如下所示:
但是,我们怎样才能用这个公式和这些联系来学习神经网络呢? 我们如何对输入数据进行分类? 神经网络的学习算法可以称为有监督,如果我们知道期望的输出,那么在学习时,输入模式被提供给网络的输入层。 最初,我们将所有权重设置为随机数,然后将输入要素发送到网络中,检查输出结果。 如果这是错误的,我们必须调整网络的所有权重以获得正确的输出。 该算法称为反向传播。 如果你想更多地了解神经网络是如何学习的,请查看http://neuralnetworksanddeeplearning.com/chap2.html和https://youtu.be/IHZwWFHWa-w。
现在我们已经简要介绍了什么是神经网络和神经网络的内部结构,我们将探讨神经网络和深度学习之间的区别。
卷积神经网络
深度学习神经网络与经典神经网络有着相同的背景。 然而,在图像分析的情况下,主要区别在于输入层。 在经典的机器学习算法中,研究人员必须确定定义要分类的图像目标的最佳特征。 例如,如果我们想对数字进行分类,我们可以提取每幅图像中数字的边框和线条,测量图像中对象的面积,所有这些特征都是神经网络或任何其他机器学习算法的输入。 然而,在深度学习中,您不必探究特征是什么;相反,您可以直接使用整个图像作为神经网络的输入。 深度学习可以学习最重要的特征是什么,深度神经网络(DNN)能够检测图像或输入并识别它。
为了了解这些特征是什么,我们使用深度学习和神经网络中最重要的层之一:卷积层。 卷积层的工作方式类似于卷积运算符,其中将核过滤器应用于前一层,从而提供新的过滤图像,类似于 Sobel 运算符:

然而,在卷积层中,我们可以定义不同的参数,其中之一是要应用于前一层或图像的滤镜数量和大小。 这些滤波器是在学习步骤中计算的,就像经典神经网络上的权重一样。 这就是深度学习的魔力:它可以从标记的图像中提取最重要的特征。
然而,这些卷积层是名称Deep背后的主要原因,我们将在下面的基本示例中了解原因。 假设我们有一幅 100x100 的图像。 在经典的神经网络中,我们将从输入图像中提取我们能想象到的最相关的特征。 这通常会有大约 1000 个特征,对于每个隐藏层,我们可以增加或减少这个数字,但用来计算其权重的神经元数量在正常的计算机中是合理的。 然而,在深度学习中,我们通常会开始应用卷积层--64 个 3x3 大小的滤波器核。 这将生成一个新的 100x100x64 神经元层,其权重为 3x3x64。 如果我们继续添加越来越多的层,这些数字会迅速增加,并且需要巨大的计算能力来学习我们的深度学习架构的良好权重和参数。
卷积层是深度学习体系结构最重要的方面之一,但也有其他重要层,如池化、丢弃、扁平和Softmax。 在下图中,我们可以看到一个基本的深度学习架构,其中堆叠了一些卷积和池层:
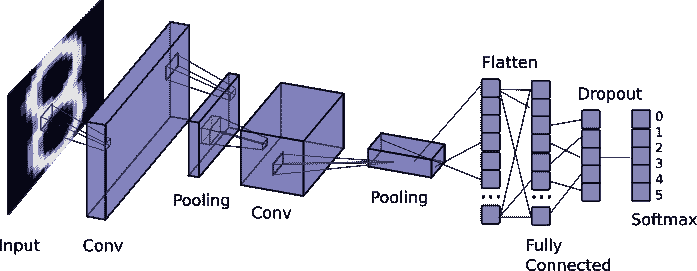
然而,还有一件非常重要的事情使深度学习获得最好的结果:标签数据量。 如果您的数据集很小,深度学习算法将无法帮助您进行分类,因为没有足够的数据来学习特征(深度学习体系结构的权重和参数)。 但是,如果你有海量的数据,你会得到非常好的结果。 但是要小心,您将需要大量的时间来计算和学习您的体系结构的权重和参数。 这就是为什么在这个过程的早期没有使用深度学习,因为计算需要大量的时间。 然而,多亏了新的并行架构,如 NVIDIA GPU,我们可以优化学习反向传播并加快学习任务。
OpenCV 中的深度学习
深度学习模块作为贡献模块引入到版本 3.1 的 OpenCV 中。 这在 3.3 版本中被转移到 OpenCV 的一部分,但直到 3.4.3 和 4 版本才被开发人员广泛采用。
OpenCV 实现的深度学习只用于推理,这意味着您不能创建自己的深度学习架构,也不能在 OpenCV 中进行训练;您只能导入预先训练好的模型,在 OpenCV 库下执行,并将其作为前馈(推理)来获得结果。
实现前馈算法的最重要原因是对 OpenCV 进行优化,以加快推理的计算时间和性能。 不实现后向方法的另一个原因是为了避免浪费时间开发其他库(如 TensorFlow 或 Caffe)专门从事的东西。 OpenCV 随后为最重要的深度学习库和框架创建了导入器,使导入预先训练好的模型成为可能。
然后,如果要创建新的深度学习模型以在 OpenCV 中使用,首先必须使用 TensorFlow、Caffe、Torch 或 Dark Net 框架或可用于以开放式神经网络交换(ONX)格式导出模型的框架来创建和训练该模型。 使用此框架创建模型可能很简单,也可能很复杂,具体取决于您使用的框架,但本质上您必须堆叠多个层,就像我们在上一个图表中所做的那样,设置 DNN 所需的参数和功能。 现在有其他工具可以帮助您在不编码的情况下创建模型,例如https://www.tensoreditor.com或Lobe.ai。 TensorEditor 允许您下载从可视化设计架构生成的 TensorFlow 代码,以便在您的计算机或云中进行训练。 在下面的屏幕截图中,我们可以看到 TensorEditor:
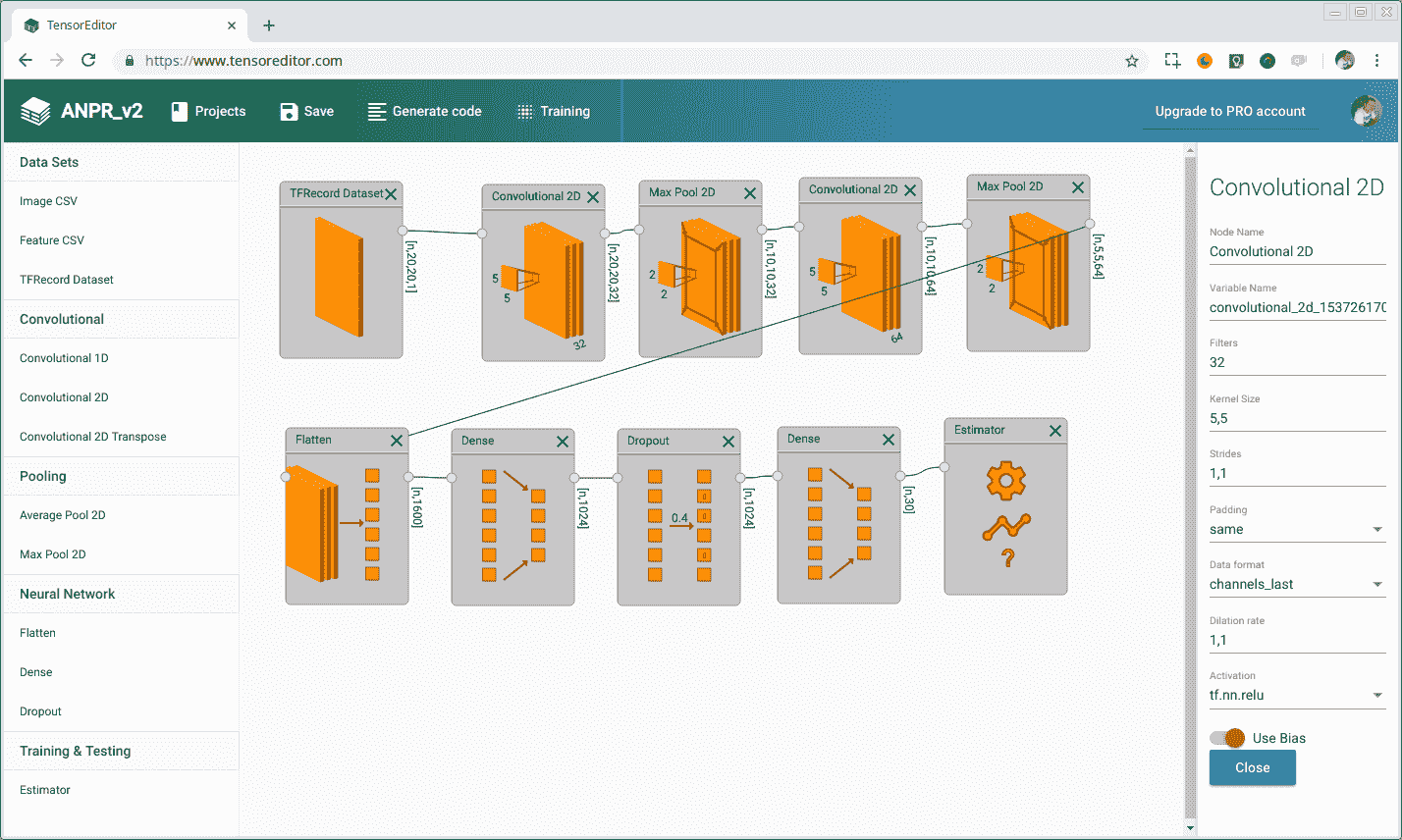
对模型进行训练并对结果满意后,可以将其直接导入到 OpenCV 以预测新的输入图像。 在下一节中,您将了解如何在 OpenCV 中导入和使用深度学习模型。
YOLO-实时目标检测
为了学习如何在 OpenCV 中使用深度学习,我们将给出一个基于 YOLO 算法的目标检测和分类的例子。 这是最快的物体检测和识别算法之一,在 NVIDIA Titan X 上运行速度约为 30fps。
YOLO v3 深度学习模型架构
经典计算机视觉中常见的目标检测使用滑动窗口来检测目标,以不同的窗口大小和比例扫描整个图像。 这里的主要问题是多次扫描图像以查找对象会耗费大量时间。
YOLO 使用了一种不同的方法,将图表划分为 S x S 网格。 对于每个网格,YOLO 检查 B 个边界框,然后深度学习模型提取每个面片的边界框、包含可能对象的置信度以及每个框的训练数据集中每个类别的置信度。 以下屏幕截图显示了 S x S 网格:
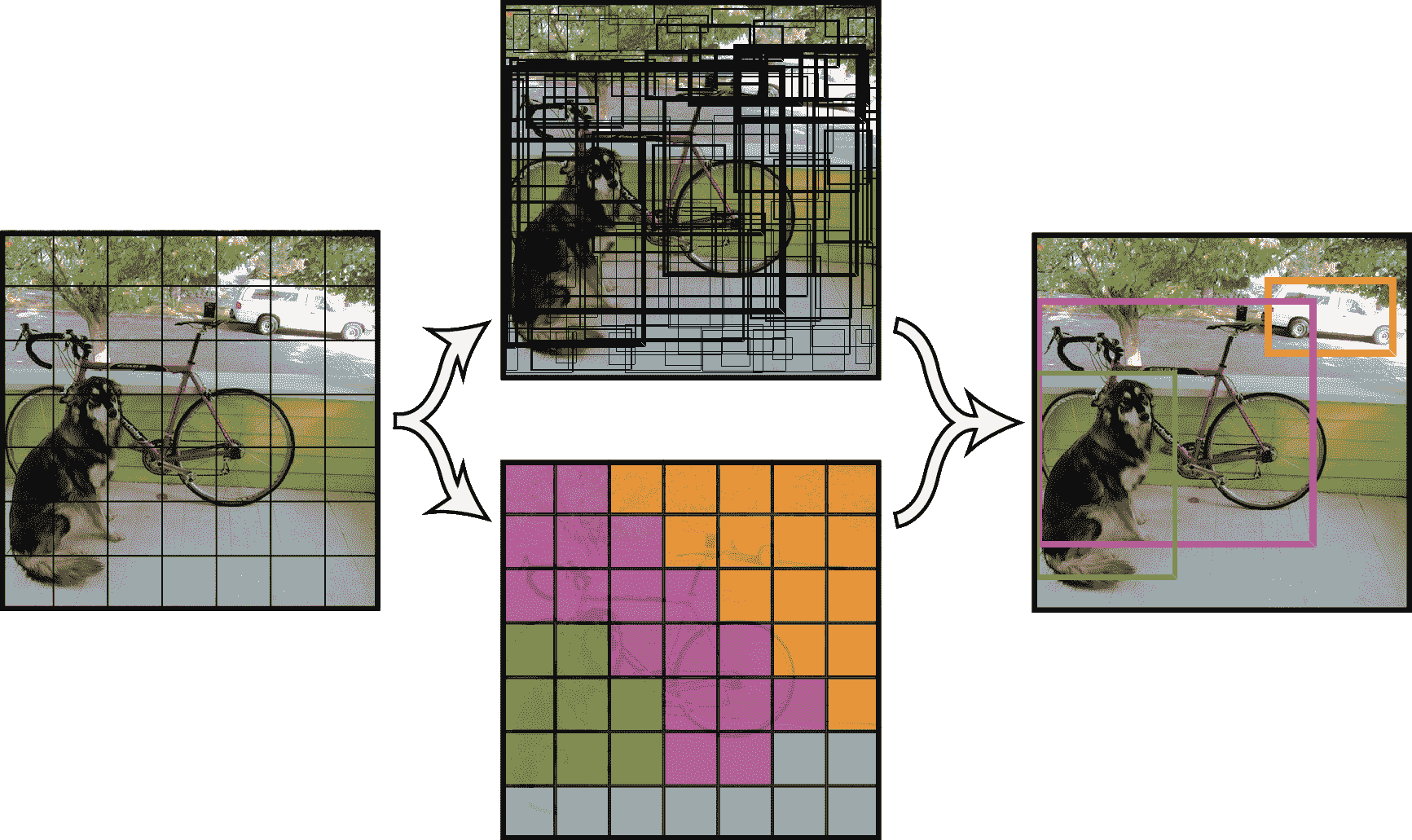
YOLO 使用包含 19 个和 5 个边界框的网格进行训练,每个网格使用 80 个类别。 然后,输出结果为 19x19x425,其中 425 来自边界框(x,y,宽,高)、对象置信度和 80 个类别的数据,置信度乘以每个网格的框数; 5_ 边界框(x,y,w,h,对象_置信度, 分类_置信度[80])=5(4+1+80):

YOLO v3 架构基于暗网,它包含 53 层网络,YOLO 又增加了 53 层,总共有 106 层网络。 如果你想要一个更快的架构,你可以选择版本 2 或 TinyYOLO 版本,它们使用的层更少。
YOLO 数据集、词汇表和模型
在我们开始将模型导入到我们的 OpenCV 代码之前,我们必须通过 yolo 网站获得它:https://pjreddie.com/darknet/yolo/。 这提供了基于COCO数据集的预先训练的模型文件,该数据集包含 80 个对象类别,例如人、伞、自行车、摩托车、汽车、苹果、香蕉、计算机和椅子。
要获取用于可视化的所有类别和用途的名称,请查看https://github.com/pjreddie/darknet/blob/master/data/coco.names?raw=true。
这些名称的顺序与深度学习模型置信度的结果相同。 如果您想按类别查看 COCO 数据集的一些图像,可以在http://cocodataset.org/#explore浏览该数据集,并下载其中一些图像来测试我们的示例应用。
要获取模型配置和预先训练的权重,您必须下载以下文件:
- https://pjreddie.com/media/files/yolov3.weights
- https://github.com/pjreddie/darknet/blob/master/cfg/yolov3.cfg?raw=true
现在,我们已经准备好开始将模型导入到 OpenCV 中。
将 YOLO 导入到 OpenCV
深度学习 OpenCV 模块位于opencv2/dnn.hpp标头下,我们必须将其包括在我们的源标头和cv::dnn namespace中。
则 OpenCV 的标题必须如下所示:
...
#include <opencv2/core.hpp>
#include <opencv2/dnn.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/highgui.hpp>
using namespace cv;
using namespace dnn;
...
我们要做的第一件事是导入 Coco 名称的词汇表,该词汇表位于coco.names文件中。 该文件是一个纯文本文件,每行包含一个类类别,其排序方式与置信度结果相同。 然后,我们将读取该文件的每一行,并将其存储在称为类的字符串向量中:
...
int main(int argc, char** argv)
{
// Load names of classes
string classesFile = "coco.names";
ifstream ifs(classesFile.c_str());
string line;
while (getline(ifs, line)) classes.push_back(line);
...
现在我们将深度学习模型导入到 OpenCV 中。 OpenCV 为深度学习框架实现了最常见的阅读器/导入器,比如 TensorFlow 和 DarkNet,它们都有相似的语法。 在我们的示例中,我们将使用权重导入暗网模型,并使用readNetFromDarknetOpenCV 函数导入模型:
...
// Give the configuration and weight files for the model
String modelConfiguration = "yolov3.cfg";
String modelWeights = "yolov3.weights";
// Load the network
Net net = readNetFromDarknet(modelConfiguration, modelWeights);
...
现在我们可以读取图像,并将深度神经网络发送到推理。 首先,我们必须使用imread函数读取图像,并将其转换为可以读取DotNetNuke(DNN)的张量/BLOB 数据。 要从图像创建斑点,我们将通过传递图像来使用blobFromImage函数。 此函数接受以下参数:
- image:输入图像(具有 1、3 或 4 个通道)。
- BLOB:输出
mat。 - scalefactor:图像值的乘数。
- SIZE:DNN 的输入所需的输出 BLOB 的空间大小。
- Mean:从通道减去平均值的标量。 如果图像具有 BGR 排序且
swapRB为真,则值应按(Mean-R、Mean-G 和 Mean-B)顺序排列。 - swapRB:3 通道图像中指示交换第一个通道和最后一个通道的标志是必需的。
- 裁剪:指示调整大小后是否裁剪图像的标志。
您可以在以下代码片段中阅读有关如何读取图像并将其转换为 BLOB 的完整代码:
...
input= imread(argv[1]);
// Stop the program if reached end of video
if (input.empty()) {
cout << "No input image" << endl;
return 0;
}
// Create a 4D blob from a frame.
blobFromImage(input, blob, 1/255.0, Size(inpWidth, inpHeight), Scalar(0,0,0), true, false);
...
最后,我们必须将 BLOB 提供给 Deep Net,并使用forward函数调用推理,该函数需要两个参数:OUTmat结果和输出需要检索的层的名称:
...
//Sets the input to the network
net.setInput(blob);
// Runs the forward pass to get output of the output layers
vector<Mat> outs;
net.forward(outs, getOutputsNames(net));
// Remove the bounding boxes with low confidence
postprocess(input, outs);
...
在mat输出向量中,我们有神经网络检测到的所有边界框,我们必须对输出进行后处理,以仅获得置信度大于阈值(通常为 0.5)的结果,最后应用非最大值抑制来消除多余的重叠框。 您可以在 GitHub 上获得完整的后处理代码。
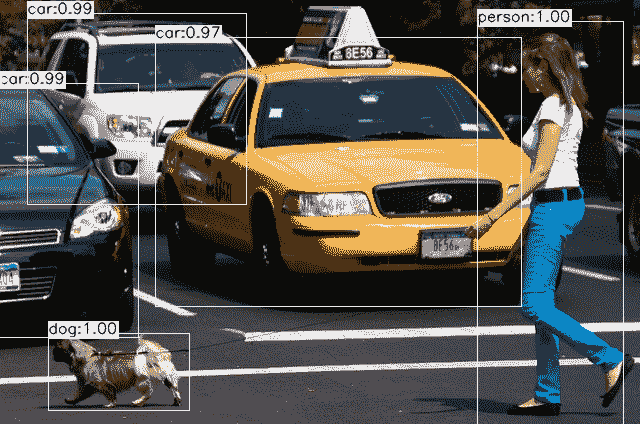
我们示例的最终结果是深度学习中的多目标检测和分类,它显示了一个类似于以下内容的窗口:
现在我们来学习另一个为人脸检测定制的常用目标检测函数。
基于 SSD 的人脸检测
单镜头检测(SSD)是另一种快速、准确的深度学习目标检测方法,其概念类似于 YOLO,在同一架构中预测目标和边界框。
固态硬盘模型架构
SSD 算法被称为单镜头算法,因为它在处理同一深度学习模型中的图像时同时预测边界框和类别。 基本上,架构概括为以下几个步骤:
- 一幅 300x300 的图像被输入到该架构中。
- 输入图像通过多个卷积层,在不同尺度上获得不同的特征。
- 对于在 2 中获得的每个特征地图,我们使用 3x3 卷积过滤器来评估一小部分默认边界框。
- 对于评估的每个默认框,预测边界框偏移量和类别概率。
模型体系结构如下所示:
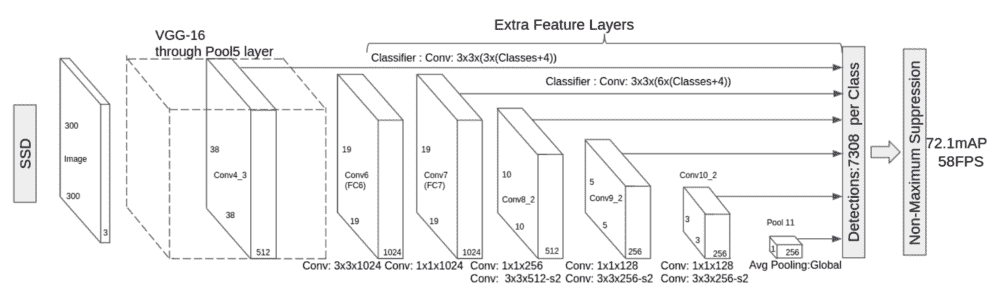
SSD 用于预测多个类别,类似于 YOLO 中的预测,但它可以修改为检测单个对象,更改最后一层,只对一个类别进行训练-这就是我们在示例中使用的人脸检测的重新训练模型,其中只预测一个类别。
将固态硬盘人脸检测导入 OpenCV
要在我们的代码中使用深度学习,我们必须导入相应的标头:
#include <opencv2/dnn.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/highgui.hpp>
之后,我们将导入所需的命名空间:
using namespace cv;
using namespace std;
using namespace cv::dnn;
现在,我们将定义将在代码中使用的输入图像大小和常量:
const size_t inWidth = 300;
const size_t inHeight = 300;
const double inScaleFactor = 1.0;
const Scalar meanVal(104.0, 177.0, 123.0);
在本例中,如果我们要处理摄像机或视频输入,我们需要一些参数作为输入,例如模型配置和预先训练的模型。 我们还需要最低的置信度才能接受预测是正确的还是错误的:
const char* params
= "{ help | false | print usage }"
"{ proto | | model configuration (deploy.prototxt) }"
"{ model | | model weights (res10_300x300_ssd_iter_140000.caffemodel) }"
"{ camera_device | 0 | camera device number }"
"{ video | | video or image for detection }"
"{ opencl | false | enable OpenCL }"
"{ min_confidence | 0.5 | min confidence }";
现在,我们将从main函数开始,在该函数中,我们将使用CommandLineParser函数解析参数:
int main(int argc, char** argv)
{
CommandLineParser parser(argc, argv, params);
if (parser.get<bool>("help"))
{
cout << about << endl;
parser.printMessage();
return 0;
}
我们还将加载模型架构和预先训练的模型文件,并将模型加载到深度学习网络中:
String modelConfiguration = parser.get<string>("proto");
String modelBinary = parser.get<string>("model");
//! [Initialize network]
dnn::Net net = readNetFromCaffe(modelConfiguration, modelBinary);
//! [Initialize network]
检查我们是否正确导入了网络,这一点非常重要。 我们还必须使用empty功能检查模型是否已导入,如下所示:
if (net.empty())
{
cerr << "Can't load network by using the following files" << endl;
exit(-1);
}
加载网络后,我们将初始化输入源、摄像机或视频文件,并加载到VideoCapture中,如下所示:
VideoCapture cap;
if (parser.get<String>("video").empty())
{
int cameraDevice = parser.get<int>("camera_device");
cap = VideoCapture(cameraDevice);
if(!cap.isOpened())
{
cout << "Couldn't find camera: " << cameraDevice << endl;
return -1;
}
}
else
{
cap.open(parser.get<String>("video"));
if(!cap.isOpened())
{
cout << "Couldn't open image or video: " << parser.get<String>("video") << endl;
return -1;
}
}
现在,我们准备开始捕捉帧,并将每个帧处理到深度神经网络中,以找到人脸。
首先,我们必须捕获循环中的每一帧:
for(;;)
{
Mat frame;
cap >> frame; // get a new frame from camera/video or read image
if (frame.empty())
{
waitKey();
break;
}
接下来,我们将把输入帧放入可以管理深度神经网络的Mat斑点结构中。 我们必须发送 SSD 大小合适的图像,即 300 x 300(我们已经初始化了inWidth和inHeight常量变量),并从输入图像中减去平均值,这是使用定义的meanVal常量变量在 SSD 中所需的:
Mat inputBlob = blobFromImage(frame, inScaleFactor, Size(inWidth, inHeight), meanVal, false, false);
现在我们可以将数据设置到网络中,并分别使用net.setInput和net.forward函数获得预测/检测。 这会将检测结果转换为我们可以读取的检测mat,其中detection.size[2]是检测到的对象的数量,detection.size[3]是每次检测的结果数量(边界框数据和置信度):
net.setInput(inputBlob, "data"); //set the network input
Mat detection = net.forward("detection_out"); //compute output
Mat detectionMat(detection.size[2], detection.size[3], CV_32F, detection.ptr<float>());
Mat检测每行包含以下内容:
-
列 0:物体存在的置信度
-
第 1 列:包围盒的置信度
-
列 2:检测到的人脸置信度
-
列 3:X 左下边界框
-
列 4:Y 左下边界框
-
列 5:X 个右上边框
-
列 6:Y 右上边界框
边界框相对于图像大小(0 比 1)。
现在,我们必须应用该阈值,以根据定义的输入阈值仅获得所需的检测:
float confidenceThreshold = parser.get<float>("min_confidence");
for(int i = 0; i < detectionMat.rows; i++)
{
float confidence = detectionMat.at<float>(i, 2);
if(confidence > confidenceThreshold)
{
现在,我们将提取边界框,在每个检测到的面上绘制一个矩形,并如下所示:
int xLeftBottom = static_cast<int>(detectionMat.at<float>(i, 3) * frame.cols);
int yLeftBottom = static_cast<int>(detectionMat.at<float>(i, 4) * frame.rows);
int xRightTop = static_cast<int>(detectionMat.at<float>(i, 5) * frame.cols);
int yRightTop = static_cast<int>(detectionMat.at<float>(i, 6) * frame.rows);
Rect object((int)xLeftBottom, (int)yLeftBottom, (int)(xRightTop - xLeftBottom), (int)(yRightTop - yLeftBottom));
rectangle(frame, object, Scalar(0, 255, 0));
}
}
imshow("detections", frame);
if (waitKey(1) >= 0) break;
}
最终结果如下所示:

在本节中,您学习了一种新的深度学习架构 SSD,以及如何使用它进行人脸检测。
简略的 / 概括的 / 简易判罪的 / 简易的
在本章中,我们学习了什么是深度学习,以及如何在 OpenCV 上使用深度学习进行对象检测和分类。 本章是为任何目的使用其他模型和深度神经网络的基础。
到目前为止,我们学习了如何获取和编译 OpenCV,如何使用基本图像和mat操作,以及如何创建自己的图形用户界面。 您使用了基本过滤器,并在工业检查示例中应用了所有这些过滤器。 我们了解了如何使用 OpenCV 进行人脸检测,以及如何操作它来添加面具。 最后,我们向您介绍了非常复杂的对象跟踪、文本分割和识别用例。 现在,您可以在 OpenCV 中创建自己的应用了,这要归功于这些用例,这些用例向您展示了如何应用每种技术或算法。 在下一章中,我们将学习如何为台式机和小型嵌入式系统(如 Raspberry Pi)编写一些图像处理过滤器。
