四、检测和跟踪不同的身体部位
在本章中,我们将学习如何在实时视频流中检测和跟踪不同的身体部位。 我们将首先讨论面部检测管道以及它是如何从头开始构建的。 我们将学习如何使用此框架来检测和跟踪其他身体部位,例如眼睛,耳朵和嘴巴。
在本章结束时,您将了解:
- 如何使用 Haar 级联
- 什么是完整的图像
- 什么是自适应增强
- 如何在实时视频流中检测和跟踪面部
- 如何在实时视频流中检测和跟踪眼睛
- 如何将太阳镜自动覆盖在人的脸上
- 如何检测眼睛,耳朵和嘴巴
- 如何使用形状分析检测瞳孔
使用 Haar 级联检测对象
当我们说 Haar 级联时,实际上是在谈论基于 Haar 特征的级联分类器。 要了解这意味着什么,我们需要退后一步,并首先了解为什么需要这样做。 早在 2001 年,Paul Viola 和 Michael Jones 在他们的开创性论文中提出了一种非常有效的对象检测方法。 它已成为机器学习领域的主要标志之一。
在他们的论文中,他们描述了一种机器学习技术,其中使用了增强的简单分类器级联来获得表现非常好的整体分类器。 这样,我们就可以避免构建单个复杂分类器以实现高精度的过程。 之所以如此令人惊讶,是因为构建一个强大的单步分类器是一个计算量大的过程。 此外,我们需要大量的训练数据来建立这样的分类器。 该模型最终变得复杂,并且表现可能达不到要求。
假设我们要检测像菠萝这样的物体。 为了解决这个问题,我们需要构建一个机器学习系统,该系统将学习菠萝的外观。 它应该能够告诉我们未知图像是否包含菠萝。 为了实现这样的目标,我们需要训练我们的系统。 在机器学习领域,我们有很多方法可以训练系统。 这很像训练狗,只是它不会帮您拿到球! 为了训练我们的系统,我们拍摄了很多菠萝和非菠萝图像,然后将它们输入到系统中。 在此,将菠萝图像称为正图像,将非菠萝图像称为负图像。
就训练而言,有很多路线可供选择。 但是所有传统技术都是计算密集型的,并且会导致模型复杂。 我们不能使用这些模型来构建实时系统。 因此,我们需要保持分类器简单。 但是,如果我们保持分类器简单,那么它将是不准确的。 速度和准确率之间的权衡在机器学习中很常见。 通过构建一组简单的分类器,然后将它们级联在一起以形成一个健壮的统一分类器,我们克服了这个问题。 为了确保整体分类器运行良好,我们需要在层叠步骤中发挥创意。 这是 Viola-Jones 方法如此有效的主要原因之一。
谈到人脸检测这个话题,让我们看看如何训练一个系统来检测人脸。 如果要构建机器学习系统,则首先需要从所有图像中提取特征。 在我们的案例中,机器学习算法将使用这些特征来学习人脸。 我们使用 Haar 特征来构建特征向量。 Haar 特征是整个图像上补丁的简单求和和差异。 我们以多种图像尺寸执行此操作,以确保我们的系统缩放不变。
如果您好奇,可以通过以下网址了解有关该公式的更多信息
提取这些特征后,我们将其传递给一系列的分类器。 我们只检查所有不同的矩形子区域,并继续丢弃其中没有人脸的区域。 这样,我们可以快速得出最终答案,以查看给定的矩形是否包含面。
什么是完整图片?
如果要计算 Haar 特征,则必须计算图像中许多不同矩形区域的总和。 如果要有效地构建特征集,则需要在多个尺度上计算这些总和。 这是一个非常昂贵的过程! 如果我们要构建一个实时系统,我们就不能花费那么多的周期来计算这些和。 因此,我们使用了积分图像:
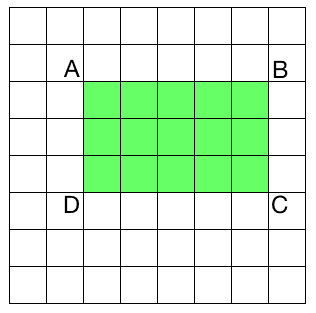
要计算图像中任何矩形的总和,我们不需要遍历该矩形区域中的所有元素。 假设AP表示矩形中由左上角的点和图像中的点P作为两个对角相对的角所形成的所有元素的总和。 因此,现在,如果要计算矩形 ABCD 的面积,可以使用以下公式:
矩形 ABCD 的面积 = AC - (AB + AD - AA)
我们为什么要关心这个特定公式? 如前所述,提取 Haar 特征包括以多个比例计算图像中大量矩形的面积。 这些计算中有很多是重复的,整个过程非常缓慢。 实际上,它是如此之慢,以至于我们无力实时运行任何东西。 这就是我们使用这种秘籍的原因! 这种方法的好处是我们不必重新计算任何东西。 该方程式右侧面积的所有值均已可用。 因此,我们仅使用它们来计算任何给定矩形的面积并提取特征。
检测和追踪人脸
OpenCV 提供了一个不错的人脸检测框架。 我们只需要加载级联文件并使用它来检测图像中的面部。 让我们看看如何做到这一点:
import cv2
import numpy as np
face_cascade = cv2.CascadeClassifier('./cascade_files/haarcascade_frontalface_alt.xml')
cap = cv2.VideoCapture(0)
scaling_factor = 0.5
while True:
ret, frame = cap.read()
frame = cv2.resize(frame, None, fx=scaling_factor,
fy=scaling_factor, interpolation=cv2.INTER_AREA)
face_rects = face_cascade.detectMultiScale(frame, scaleFactor=1.3, minNeighbors=3)
for (x,y,w,h) in face_rects:
cv2.rectangle(frame, (x,y), (x+w,y+h), (0,255,0), 3)
cv2.imshow('Face Detector', frame)
c = cv2.waitKey(1)
if c == 27:
break
cap.release()
cv2.destroyAllWindows()
如果运行前面的代码,结果将类似于下图:

更好地了解它
我们需要一个可用于检测图像中人脸的分类器模型。 OpenCV 提供了可用于此目的的 XML 文件。 我们使用函数CascadeClassifier加载 XML 文件。 一旦我们开始从网络摄像头捕获输入帧并使用detectMultiScale函数获取当前图像中所有面部的边界框,以防万一帧没有以灰度传递,则将在该方法内部运行,因为需要灰度帧来处理检测。 此函数中的第二个参数指定缩放因子的跳跃,例如,如果我们找不到当前缩放比例的图像,则在我们的示例中,下一个要检查的尺寸将比当前尺寸大 1.3 倍。 最后一个参数是一个阈值,用于指定保留当前矩形所需的最小相邻矩形数。 万一人脸识别无法按预期工作时,可以使用它来提高人脸检测器的鲁棒性,降低阈值以获得更好的识别。 如果图像由于处理检测而有些延迟,请将缩放帧的大小减小 0.4 或 0.3。
人脸上的乐趣
现在我们知道了如何检测和跟踪脸部,让我们一起玩一些乐趣。 当我们从摄像头捕获视频流时,我们可以在脸部上方覆盖有趣的遮罩。 它看起来像下图:

如果您是汉尼拔的粉丝,可以尝试以下方法:

让我们看一下代码,看看如何在输入视频流中将头骨遮罩覆盖在面部顶部:
import cv2
import numpy as np
face_cascade = cv2.CascadeClassifier('./cascade_files/haarcascade_frontalface_alt.xml')
face_mask = cv2.imread(img/mask_hannibal.png')
h_mask, w_mask = face_mask.shape[:2]
if face_cascade.empty():
raise IOError('Unable to load the face cascade classifier xml file')
cap = cv2.VideoCapture(0)
scaling_factor = 0.5
while True:
ret, frame = cap.read()
frame = cv2.resize(frame, None, fx=scaling_factor, fy=scaling_factor, interpolation=cv2.INTER_AREA)
face_rects = face_cascade.detectMultiScale(frame, scaleFactor=1.3, minNeighbors=3)
for (x,y,w,h) in face_rects:
if h <= 0 or w <= 0: pass
# Adjust the height and weight parameters depending on the sizes and the locations.
# You need to play around with these to make sure you get it right.
h, w = int(1.0*h), int(1.0*w)
y -= int(-0.2*h)
x = int(x)
# Extract the region of interest from the image
frame_roi = frame[y:y+h, x:x+w]
face_mask_small = cv2.resize(face_mask, (w, h), interpolation=cv2.INTER_AREA)
# Convert color image to grayscale and threshold it
gray_mask = cv2.cvtColor(face_mask_small, cv2.COLOR_BGR2GRAY)
ret, mask = cv2.threshold(gray_mask, 180, 255, cv2.THRESH_BINARY_INV)
# Create an inverse mask
mask_inv = cv2.bitwise_not(mask)
try:
# Use the mask to extract the face mask region of interest
masked_face = cv2.bitwise_and(face_mask_small, face_mask_small, mask=mask)
# Use the inverse mask to get the remaining part of the image
masked_frame = cv2.bitwise_and(frame_roi, frame_roi, mask=mask_inv)
except cv2.error as e:
print('Ignoring arithmentic exceptions: '+ str(e))
# add the two images to get the final output
frame[y:y+h, x:x+w] = cv2.add(masked_face, masked_frame)
cv2.imshow('Face Detector', frame)
c = cv2.waitKey(1)
if c == 27:
break
cap.release()
cv2.destroyAllWindows()
底层原理
像以前一样,我们首先加载面部级联分类器 XML 文件。 人脸检测步骤照常工作。 我们开始无限循环,并持续检测每一帧中的人脸。 一旦知道人脸在哪里,就需要稍微修改坐标以确保遮罩正确适合。 该操作过程是主观的,并且取决于所讨论的掩模。 不同的遮罩需要不同程度的调整,以使其看起来更自然。 我们在以下行中从输入帧中提取兴趣区域:
frame_roi = frame[y:y+h, x:x+w]
现在我们有了所需的关注区域,我们需要在此之上覆盖遮罩。 因此,我们调整输入遮罩的大小以确保它适合此兴趣区域。 输入掩码具有白色背景。 因此,如果我们仅将其覆盖在兴趣区域的顶部,由于白色背景,它看起来将不自然。 我们只需要覆盖头骨遮罩像素即可; 其余区域应该是透明的。
因此,在下一步中,我们通过对头骨图像进行阈值处理来创建遮罩。 由于背景是白色,因此我们对图像进行阈值处理,以使强度值大于 180 的任何像素变为零,其他所有值变为 255。就感兴趣的帧区域而言,我们需要将这个遮罩区域的所有东西涂黑。 我们可以通过简单地使用刚创建的遮罩的逆来实现。 一旦我们获得了头骨图像的遮罩版本和感兴趣的输入区域,我们就将它们加起来以获得最终图像。
从重叠图像中删除 Alpha 通道
由于使用了重叠图像,我们应该记住,可能会在黑色像素上构建一层,这会对我们的代码结果产生不良影响。 为了避免该问题,以下代码从叠加图像中删除了 Alpha 通道层,因此使我们可以在本章中的示例代码上获得良好的效果:
import numpy as np
import cv2
def remove_alpha_channel(source, background_color):
source_img = cv2.cvtColor(source[:,:,:3], cv2.COLOR_BGR2GRAY)
source_mask = source[:,:,3] * (1 / 255.0)
bg_part = (255 * (1 / 255.0)) * (1.0 - source_mask)
weight = (source_img * (1 / 255.0)) * (source_mask)
dest = np.uint8(cv2.addWeighted(bg_part, 255.0, weight, 255.0, 0.0))
return dest
orig_img = cv2.imread(img/overlay_source.png', cv2.IMREAD_UNCHANGED)
dest_img = remove_alpha_channel(orig_img)
cv2.imwrite('images/overlay_dest.png', dest_img, [cv2.IMWRITE_PNG_COMPRESSION])
检测眼睛
现在我们了解了如何检测脸部,我们也可以将概念推广到检测其他身体部位。 重要的是要了解 Viola-Jones 框架可以应用于任何对象。 准确率和鲁棒性将取决于对象的唯一性。 例如,人脸具有非常独特的特征,因此很容易将我们的系统训练成健壮的。 另一方面,毛巾,衣服或书本之类的物体太普通,并且没有明显的特征,因此要构建坚固的检测器会更加困难。
让我们看看如何构建眼睛检测器:
import cv2
import numpy as np
face_cascade = cv2.CascadeClassifier('./cascade_files/haarcascade_frontalface_alt.xml')
eye_cascade = cv2.CascadeClassifier('./cascade_files/haarcascade_eye.xml')
if face_cascade.empty():
raise IOError('Unable to load the face cascade classifier xml file')
if eye_cascade.empty():
raise IOError('Unable to load the eye cascade classifier xml file')
cap = cv2.VideoCapture(0)
ds_factor = 0.5
while True:
ret, frame = cap.read()
frame = cv2.resize(frame, None, fx=ds_factor, fy=ds_factor, interpolation=cv2.INTER_AREA)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.3, minNeighbors=1)
for (x,y,w,h) in faces:
roi_gray = gray[y:y+h, x:x+w]
roi_color = frame[y:y+h, x:x+w]
eyes = eye_cascade.detectMultiScale(roi_gray)
for (x_eye,y_eye,w_eye,h_eye) in eyes:
center = (int(x_eye + 0.5*w_eye), int(y_eye + 0.5*h_eye))
radius = int(0.3 * (w_eye + h_eye))
color = (0, 255, 0)
thickness = 3
cv2.circle(roi_color, center, radius, color, thickness)
cv2.imshow('Eye Detector', frame)
c = cv2.waitKey(1)
if c == 27:
break
cap.release()
cv2.destroyAllWindows()
如果运行此程序,输出将类似于下图:

事后思考
如果您注意到,该程序看起来与人脸检测程序非常相似。 除了加载人脸检测级联分类器外,我们还加载了眼睛检测级联分类器。 从技术上讲,我们不需要使用面部检测器。 但是我们知道眼睛总是在别人的脸上。 我们使用此信息并仅在感兴趣的相关区域(即脸部)中搜索眼睛。 我们首先检测人脸,然后在该子图像上运行眼睛检测器。 这样,它更快,更高效。
有趣的眼睛
现在,我们知道了如何检测图像中的眼睛,让我们看看我们是否可以对此做一些有趣的事情。 我们可以执行以下屏幕快照中所示的操作:

让我们看一下代码,看看如何做这样的事情:
import cv2
import numpy as np
face_cascade = cv2.CascadeClassifier('./cascade_files/haarcascade_frontalface_alt.xml')
eye_cascade = cv2.CascadeClassifier('./cascade_files/haarcascade_eye.xml')
if face_cascade.empty():
raise IOError('Unable to load the face cascade classifier xml file')
if eye_cascade.empty():
raise IOError('Unable to load the eye cascade classifier xml file')
cap = cv2.VideoCapture(0)
sunglasses_img = cv2.imread('images/sunglasses.png')
while True:
ret, frame = cap.read()
frame = cv2.resize(frame, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_AREA)
vh, vw = frame.shape[:2]
vh, vw = int(vh), int(vw)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.3, minNeighbors=1)
centers = []
for (x,y,w,h) in faces:
roi_gray = gray[y:y+h, x:x+w]
roi_color = frame[y:y+h, x:x+w]
eyes = eye_cascade.detectMultiScale(roi_gray)
for (x_eye,y_eye,w_eye,h_eye) in eyes:
centers.append((x + int(x_eye + 0.5*w_eye), y + int(y_eye + 0.5*h_eye)))
if len(centers) > 1: # if detects both eyes
h, w = sunglasses_img.shape[:2]
# Extract the region of interest from the image
eye_distance = abs(centers[1][0] - centers[0][0])
# Overlay sunglasses; the factor 2.12 is customizable depending on the size of the face
sunglasses_width = 2.12 * eye_distance
scaling_factor = sunglasses_width / w
print(scaling_factor, eye_distance)
overlay_sunglasses = cv2.resize(sunglasses_img, None, fx=scaling_factor, fy=scaling_factor, interpolation=cv2.INTER_AREA)
x = centers[0][0] if centers[0][0] < centers[1][0] else centers[1][0]
# customizable X and Y locations; depends on the size of the face
x -= int(0.26*overlay_sunglasses.shape[1])
y += int(0.26*overlay_sunglasses.shape[0])
h, w = overlay_sunglasses.shape[:2]
h, w = int(h), int(w)
frame_roi = frame[y:y+h, x:x+w]
# Convert color image to grayscale and threshold it
gray_overlay_sunglassess = cv2.cvtColor(overlay_sunglasses, cv2.COLOR_BGR2GRAY)
ret, mask = cv2.threshold(gray_overlay_sunglassess, 180, 255, cv2.THRESH_BINARY_INV)
# Create an inverse mask
mask_inv = cv2.bitwise_not(mask)
try:
# Use the mask to extract the face mask region of interest
masked_face = cv2.bitwise_and(overlay_sunglasses, overlay_sunglasses, mask=mask)
# Use the inverse mask to get the remaining part of the image
masked_frame = cv2.bitwise_and(frame_roi, frame_roi, mask=mask_inv)
except cv2.error as e:
print('Ignoring arithmentic exceptions: '+ str(e))
#raise e
# add the two images to get the final output
frame[y:y+h, x:x+w] = cv2.add(masked_face, masked_frame)
else:
print('Eyes not detected')
cv2.imshow('Eye Detector', frame)
c = cv2.waitKey(1)
if c == 27:
break
cap.release()
cv2.destroyAllWindows()
放置太阳镜
就像我们之前所做的一样,我们加载图像并检测眼睛。 一旦检测到眼睛,便会调整太阳镜图像的大小以适合当前的关注区域。 为了创建兴趣区域,我们考虑了眼睛之间的距离。 我们相应地调整图像的大小,然后继续创建遮罩。 这类似于我们之前对骷髅面罩所做的操作。 太阳镜在脸上的位置是主观的,因此如果您想使用另一副太阳镜,则必须调整权重。
检测耳朵
通过使用 Haar 级联分类器文件,下面的代码将再次识别每只耳朵,并在检测到它们时将它们突出显示。 您会注意到,需要两个不同的分类器,因为每个耳朵的坐标将被反转:
import cv2
import numpy as np
left_ear_cascade = cv2.CascadeClassifier('./cascade_files/haarcascade_mcs_leftear.xml')
right_ear_cascade = cv2.CascadeClassifier('./cascade_files/haarcascade_mcs_rightear.xml')
if left_ear_cascade.empty():
raise IOError('Unable to load the left ear cascade classifier xml file')
if right_ear_cascade.empty():
raise IOError('Unable to load the right ear cascade classifier xml file')
cap = cv2.VideoCapture(0)
scaling_factor = 0.5
while True:
ret, frame = cap.read()
frame = cv2.resize(frame, None, fx=scaling_factor, fy=scaling_factor, interpolation=cv2.INTER_AREA)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
left_ear = left_ear_cascade.detectMultiScale(gray, scaleFactor=1.3, minNeighbors=3)
right_ear = right_ear_cascade.detectMultiScale(gray, scaleFactor=1.3, minNeighbors=3)
for (x,y,w,h) in left_ear:
cv2.rectangle(frame, (x,y), (x+w,y+h), (0,255,0), 3)
for (x,y,w,h) in right_ear:
cv2.rectangle(frame, (x,y), (x+w,y+h), (255,0,0), 3)
cv2.imshow('Ear Detector', frame)
c = cv2.waitKey(1)
if c == 27:
break
cap.release()
cv2.destroyAllWindows()
如果在图像上运行前面的代码,则应该看到类似以下屏幕截图的内容:

检测嘴巴
这次,使用 Haar 分类器,我们将从输入视频流中提取嘴巴位置,在该代码下面的代码中,我们将使用这些坐标在脸上放置小胡子:
import cv2
import numpy as np
mouth_cascade = cv2.CascadeClassifier('./cascade_files/haarcascade_mcs_mouth.xml')
if mouth_cascade.empty():
raise IOError('Unable to load the mouth cascade classifier xml file')
cap = cv2.VideoCapture(0)
ds_factor = 0.5
while True:
ret, frame = cap.read()
frame = cv2.resize(frame, None, fx=ds_factor, fy=ds_factor, interpolation=cv2.INTER_AREA)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
mouth_rects = mouth_cascade.detectMultiScale(gray, scaleFactor=1.7, minNeighbors=11)
for (x,y,w,h) in mouth_rects:
y = int(y - 0.15*h)
cv2.rectangle(frame, (x,y), (x+w,y+h), (0,255,0), 3)
break
cv2.imshow('Mouth Detector', frame)
c = cv2.waitKey(1)
if c == 27:
break
cap.release()
cv2.destroyAllWindows()
下图显示了输出结果:

覆盖胡须
让我们在上面盖上胡须:
import cv2
import numpy as np
mouth_cascade = cv2.CascadeClassifier('./cascade_files/haarcascade_mcs_mouth.xml')
moustache_mask = cv2.imread(img/moustache.png')
h_mask, w_mask = moustache_mask.shape[:2]
if mouth_cascade.empty():
raise IOError('Unable to load the mouth cascade classifier xml file')
cap = cv2.VideoCapture(0)
scaling_factor = 0.5
while True:
ret, frame = cap.read()
frame = cv2.resize(frame, None, fx=scaling_factor, fy=scaling_factor, interpolation=cv2.INTER_AREA)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
mouth_rects = mouth_cascade.detectMultiScale(gray, 1.3, 5)
if len(mouth_rects) > 0:
(x,y,w,h) = mouth_rects[0]
h, w = int(0.6*h), int(1.2*w)
x -= int(0.05*w)
y -= int(0.55*h)
frame_roi = frame[y:y+h, x:x+w]
moustache_mask_small = cv2.resize(moustache_mask, (w, h), interpolation=cv2.INTER_AREA)
gray_mask = cv2.cvtColor(moustache_mask_small, cv2.COLOR_BGR2GRAY)
ret, mask = cv2.threshold(gray_mask, 50, 255, cv2.THRESH_BINARY_INV)
mask_inv = cv2.bitwise_not(mask)
masked_mouth = cv2.bitwise_and(moustache_mask_small, moustache_mask_small, mask=mask)
masked_frame = cv2.bitwise_and(frame_roi, frame_roi, mask=mask_inv)
frame[y:y+h, x:x+w] = cv2.add(masked_mouth, masked_frame)
cv2.imshow('Moustache', frame)
c = cv2.waitKey(1)
if c == 27:
break
cap.release()
cv2.destroyAllWindows()
看起来是这样的:

检测瞳孔
我们将在这里采取不同的方法。 瞳孔太普通了,无法采用 Haar 级联方法。 我们还将了解如何根据事物的形状检测事物。 以下是输出结果:

让我们看看如何构建瞳孔检测器:
import math
import cv2
eye_cascade = cv2.CascadeClassifier('./cascade_files/haarcascade_eye.xml')
if eye_cascade.empty():
raise IOError('Unable to load the eye cascade classifier xml file')
cap = cv2.VideoCapture(0)
ds_factor = 0.5
ret, frame = cap.read()
contours = []
while True:
ret, frame = cap.read()
frame = cv2.resize(frame, None, fx=ds_factor, fy=ds_factor, interpolation=cv2.INTER_AREA)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
eyes = eye_cascade.detectMultiScale(gray, scaleFactor=1.3, minNeighbors=1)
for (x_eye, y_eye, w_eye, h_eye) in eyes:
pupil_frame = gray[y_eye:y_eye + h_eye, x_eye:x_eye + w_eye]
ret, thresh = cv2.threshold(pupil_frame, 80, 255, cv2.THRESH_BINARY)
cv2.imshow("threshold", thresh)
im2, contours, hierarchy = cv2.findContours(thresh, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
print(contours)
for contour in contours:
area = cv2.contourArea(contour)
rect = cv2.boundingRect(contour)
x, y, w, h = rect
radius = 0.15 * (w + h)
area_condition = (100 <= area <= 200)
symmetry_condition = (abs(1 - float(w)/float(h)) <= 0.2)
fill_condition = (abs(1 - (area / (math.pi * math.pow(radius, 2.0)))) <= 0.4)
cv2.circle(frame, (int(x_eye + x + radius), int(y_eye + y + radius)), int(1.3 * radius), (0, 180, 0), -1)
cv2.imshow('Pupil Detector', frame)
c = cv2.waitKey(1)
if c == 27:
break
cap.release()
cv2.destroyAllWindows()
如果运行此程序,您将看到如前所示的输出。
解构代码
如前所述,我们不会使用 Haar 级联来检测学生。 如果我们不能使用预先训练的分类器,那么我们将如何检测学生? 好吧,我们可以使用形状分析来检测瞳孔。 我们知道瞳孔是圆形的,因此我们可以使用此信息在图像中检测到它们。 我们反转输入图像,然后将其转换为灰度图像,如以下行所示:
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
正如我们在这里看到的,我们可以使用波浪号运算符反转图像。 在我们的情况下,将图像反转非常有用,因为瞳孔是黑色的,而黑色对应于较低的像素值。 然后,我们对图像进行阈值处理,以确保只有黑白像素。 现在,我们必须找出所有形状的边界。 OpenCV 提供了一个很好的函数来实现这一目标,即findContours。 我们将在接下来的章节中讨论更多有关此的内容。 但就目前而言,我们所需要知道的是,此函数返回在图像中找到的所有形状的边界集。
下一步是识别瞳孔的形状,并丢弃其余的瞳孔。 我们将使用圆的某些属性对此形状进行归零。 让我们考虑边界矩形的宽高比。 如果形状是圆形,则该比率将为 1。 我们可以使用boundingRect函数来获取边界矩形的坐标。 让我们考虑一下这种形状的面积。 如果我们粗略计算此形状的半径并使用公式计算圆的面积,则它应接近此轮廓的面积。 我们可以使用contourArea函数来计算图像中任何轮廓的面积。 因此,我们可以使用这些条件并过滤出形状。 完成此操作后,图像中剩下两个瞳孔。 我们可以通过将搜索区域限制在面部或眼睛来进一步完善它。 由于您知道如何检测面部和眼睛,因此可以尝试一下,看看是否可以将其用于实时视频流。
如果您想玩另一种身体检测,只需转到以下链接以找到差异分类器。
总结
在本章中,我们讨论了 Haar 级联和积分图像。 我们了解了人脸检测管道的构建方式。 我们学习了如何在实时视频流中检测和跟踪面部。 我们讨论了如何使用面部检测管道来检测身体的各个部位,例如眼睛,耳朵,鼻子和嘴巴。 我们学习了如何使用身体部位检测的结果在输入图像的顶部覆盖遮罩。 我们使用形状分析的原理来检测学生。
在下一章中,我们将讨论特征检测以及如何将其用于理解图像内容。
