十五、使用人脸模块的脸部地标和姿势设置
人脸标志点检测是在人脸图像中找到兴趣点的过程。 它最近引起了计算机视觉社区的兴趣,因为它有许多引人注目的应用;例如,通过人脸手势检测情感,估计凝视方向,改变人脸外观(脸部交换),用图形增强脸部,以及虚拟人物的木偶表演。 我们可以在今天的智能手机和 PC 网络摄像头程序中看到许多这样的应用。 要实现这些应用,地标检测器必须在脸部找到几十个点,例如嘴角、眼角、下巴轮廓等等。 为此,开发了许多算法,并在 OpenCV 中实现了一些算法。 在本章中,我们将讨论使用cv::face模块检测人脸地标(也称为人脸标记)的过程,该模块提供了用于推理的 API,以及人脸标记检测器的培训。 我们将了解如何应用人脸标记检测器在 3D 中定位人脸的方向。
本章将介绍以下主题:
- 介绍了人脸标志点检测的历史和原理,并对 OpenCV 中实现的算法进行了说明
- 利用 OpenCV 的
face模块进行人脸标志点检测 - 利用 2D-3D 信息估计人脸的大致方向
技术要求
构建本章中的代码需要以下技术和安装:
- OpenCV v4(使用
face contrib模块编译) - Boost v1.66+
附带的代码存储库中将提供前面列出的组件的构建说明,以及实现本章中所示概念的代码。
要运行脸标检测器,需要预先训练的模型。虽然使用 OpenCV 中提供的 API 来训练检测器模型当然是可能的,但也提供了一些预先训练的模型供下载。其中一个模型可以从 OpenCV 的算法实现贡献者提供的https://raw.githubusercontent.com/kurnianggoro/GSOC2017/master/data/lbfmodel.yaml中获得(在 2017 年Google 代码之夏(gsoc))。
人脸标记检测器可以处理任何图像;但是,我们可以使用指定的人脸照片和视频数据集,这些数据集用于对人脸标记算法进行基准测试。 这样的数据集是300-VW,可通过智能行为理解小组(iBUG)获得,该小组是伦敦帝国理工学院的一个计算机视觉小组:https://ibug.doc.ic.ac.uk/resources/300-VW/。 它包含数百个人脸在媒体上露面的视频,仔细注释了 68 个人脸标志点。 该数据集可用于训练人脸标记检测器,以及了解我们使用的预训练模型的性能水平。 以下是 300 辆大众视频中的一段带有基本事实注释的节选:

Image reproduced under Creative Commons license
理论与语境
人脸地标检测算法自动在人脸图像上找到关键地标点的位置。 这些关键点通常是定位人脸成分的突出点,如眼角或嘴角,以实现对脸型的更高层次的理解。 例如,要检测出一系列合适的人脸表情,就需要在颌线、嘴巴、眼睛和眉毛周围的点。 事实证明,寻找人脸地标是一项困难的任务,原因有很多:对象、光照条件和遮挡之间的差异很大。 为此,计算机视觉研究人员在过去 30 年里提出了数十种地标检测算法。
最近关于人脸地标检测的一项调查(Wu and Ji,2018)建议将地标检测器分为三组:整体方法、约束局部模型(CLM)方法和回归方法:
- Wu 和 Ji 提出了整体方法,作为对脸部像素强度的完整外观进行建模的方法
- CLM 方法结合全球模型检查每个地标周围的个局部个斑块
- 回归方法反复尝试使用由回归变量学习的一系列小更新来预测地标位置
活动外观模型和约束局部模型
整体方法的一个典型例子是 90 年代末的主动外观模型(AAM),通常归因于 T.F.Cootes(1998)的工作。 在 AAM 中,目标是将已知的人脸绘制(来自训练数据)迭代地匹配到目标输入图像,目标输入图像在收敛时给出形状,从而给出地标。 AAM 方法及其衍生品非常受欢迎,而且仍然受到相当大的关注。 然而,AAM 的继任者 CLM 方法在光照变化和遮挡情况下表现出了更好的性能,并迅速占据了领先地位。 主要归功于 Cristinacce 和 Cootes(2006)和 Saragih 等人的工作。 (2011),CLM 方法对每个地标(补丁)的像素强度外观进行建模,并预先合并全局形状以应对遮挡和错误的局部检测。
CLMS 通常可以描述为寻求最小化,其中p是可以分解为其标志性的D和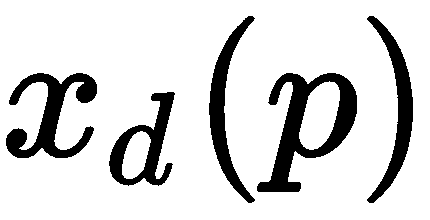 个点的脸型姿势点,如下所示:
个点的脸型姿势点,如下所示:

人脸姿势主要通过主成分分析(PCA)获得,标志点是逆 PCA 运算的结果。 使用 PCA 是很有用的,因为大多数脸型姿势都是强相关的,并且整个地标位置空间是高度冗余的。 距离函数(表示为 )用于确定给定的地标模型点与图像观测
)用于确定给定的地标模型点与图像观测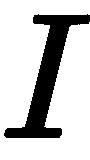 的距离有多近。 在许多情况下,距离函数是面片到面片的相似性度量(模板匹配),或者使用基于边缘的特征,例如梯度的直方图(HOG)。 术语
的距离有多近。 在许多情况下,距离函数是面片到面片的相似性度量(模板匹配),或者使用基于边缘的特征,例如梯度的直方图(HOG)。 术语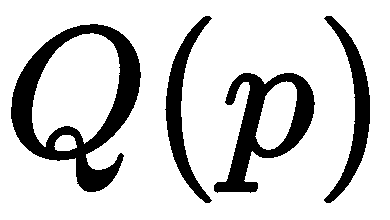 表示不太可能的或极端的脸型姿势的正规化。
表示不太可能的或极端的脸型姿势的正规化。
回归方法
相比之下,回归方法采用更简单但功能强大的方法。 这些方法使用机器学习,通过回归的方式,将更新步骤更新到地标的初始位置,并迭代直到位置收敛,其中, 是时间 tt的形状,并且
是时间 tt的形状,并且 是对图像i和当前形状运行回归函数r的结果,如下所示:
是对图像i和当前形状运行回归函数r的结果,如下所示:

然后通过级联这些更新操作,获得最终的标志性位置。
这种方法允许消耗大量的训练数据,并放弃作为 CLM 方法中心的局部相似性和全局约束而手工构建的模型。 流行的回归方法是梯度增强树(GBT),它提供非常快的推断、简单的实现,并且可以像森林一样并行。
利用深度学习,还有更新的人脸标志性检测方法。 这些新方法或者通过使用卷积神经网络(CNN)直接从图像中回归人脸标志点的位置,或者使用 CNN 与 3D 模型和级联回归方法的混合方法。
OpenCV 的face模块(在 OpenCV v3.0 中首次引入),包含 AAM、Ren 等人的实现。 (2014)和 Kazemi 等人。 (2014)回归类型法。 在本章中,我们将使用 Ren 等人(2014)的方法,因为在给定贡献者提供的预训练模型的情况下,它提供了最好的结果。Ren 等人的方法通过局部二进制特征(LBF)、和最好地学习了局部二进制特征,和一个非常短的二进制代码,它描述了每个地标的点周围的视觉外观,以及通过回归学习形状更新步骤。
OpenCV 中的人脸标志点检测
地标检测从人脸检测开始,在图像中查找人脸及其范围(边界框)。 长期以来,人脸检测一直被认为是一个解决问题,OpenCV 包含了首批向公众免费提供的健壮的人脸检测器之一。 事实上,OpenCV 在其早期主要以其快速的人脸检测功能而闻名并被使用,它实现了规范的 Viola-Jones Boost 级联分类器算法(Viola 等人。 2001、2004),并提供预先训练的模型。 虽然人脸检测在早期已经有了很大的发展,但在 OpenCV 中检测人脸的最快、最简单的方法仍然是使用捆绑的级联分类器,通过core模块中提供的cv::CascadeClassifier类。
我们使用级联分类器实现了一个简单的助手函数来检测人脸,如下所示:
void faceDetector(const Mat& image,
std::vector<Rect> &faces,
CascadeClassifier &face_cascade) {
Mat gray;
// The cascade classifier works best on grayscale images
if (image.channels() > 1) {
cvtColor(image, gray, COLOR_BGR2GRAY);
} else {
gray = image.clone();
}
// Histogram equalization generally aids in face detection
equalizeHist(gray, gray);
faces.clear();
// Run the cascade classifier
face_cascade.detectMultiScale(
gray,
faces,
1.4, // pyramid scale factor
3, // lower thershold for neighbors count
// here we hint the classifier to only look for one face
CASCADE_SCALE_IMAGE + CASCADE_FIND_BIGGEST_OBJECT);
}
我们可能需要调整控制人脸检测的两个参数:金字塔比例因子和邻居数。 金字塔比例因子用于创建图像金字塔,检测器将尝试在其中查找人脸。 这就是多尺度检测的实现方式,因为裸探测器有固定的孔径。 在图像金字塔的每一步中,图像都会按此比例缩小,因此较小的比例(接近 1.0)会产生更多图像,运行时间更长,但结果更准确。 我们还控制了一些邻居的下限。 这在级联分类器在非常接近的情况下具有多个正面分类时开始起作用。 这里,我们指示总体分类仅在其至少有三个相邻的正面分类时才返回一个面界。 较小的数字(整数,接近 1)将返回更多检测,但也会导致误报。
我们必须从 OpenCV 提供的模型初始化级联分类器(序列化模型的 XML 文件在$OPENCV_ROOT/data/haarcascades目录中提供)。 我们在正面人脸上使用标准训练的分类器,演示如下:
const string cascade_name = "$OPENCV_ROOT/data/haarcascades/haarcascade_frontalface_default.xml";
CascadeClassifier face_cascade;
if (not face_cascade.load(cascade_name)) {
cerr << "Cannot load cascade classifier from file: " << cascade_name << endl;
return -1;
}
// ... obtain an image in img
vector<Rect> faces;
faceDetector(img, faces, face_cascade);
// Check if any faces were detected or not
if (faces.size() == 0) {
cerr << "Cannot detect any faces in the image." << endl;
return -1;
}
下面的屏幕截图显示了人脸检测器结果的可视化:

人脸标记检测器将绕过检测到的人脸,从边界框开始。 但是,首先我们必须初始化cv::face::Facemark对象,如下所示:
#include <opencv2/face.hpp>
using namespace cv::face;
// ...
const string facemark_filename = "data/lbfmodel.yaml";
Ptr<Facemark> facemark = createFacemarkLBF();
facemark->loadModel(facemark_filename);
cout << "Loaded facemark LBF model" << endl;
cv::face::Facemark抽象 API 用于所有地标检测器风格,并根据特定算法提供用于推理和训练的实现的基本功能。 加载后,可以将facemark对象与其fit函数一起使用来查找人脸形状,如下所示:
vector<Rect> faces;
faceDetector(img, faces, face_cascade);
// Check if faces detected or not
if (faces.size() != 0) {
// We assume a single face so we look at the first only
cv::rectangle(img, faces[0], Scalar(255, 0, 0), 2);
vector<vector<Point2f> > shapes;
if (facemark->fit(img, faces, shapes)) {
// Draw the detected landmarks
drawFacemarks(img, shapes[0], cv::Scalar(0, 0, 255));
}
} else {
cout << "Faces not detected." << endl;
}
地标探测器结果的可视化(使用cv::face::drawFacemarks)如以下屏幕截图所示:

测量误差
从视觉上看,效果似乎很好。 然而,由于我们有基本的真实数据,我们可以选择将其与检测进行分析比较,并得到误差估计。 我们可以使用标准的平均欧几里得距离度量( )来判断每个预测的地标与地面事实的平均距离:
)来判断每个预测的地标与地面事实的平均距离:
float MeanEuclideanDistance(const vector<Point2f>& A, const vector<Point2f>& B) {
float med = 0.0f;
for (int i = 0; i < A.size(); ++ i) {
med += cv::norm(A[i] - B[i]);
}
return med / (float)A.size();
}
预测(红色)和地面实况(绿色)叠加的可视化结果,如以下屏幕截图所示:

我们可以看到,对于这些特定的视频帧,所有地标的平均误差大约只有一个像素。
根据地标估计人脸方向
获得人脸地标后,我们可以尝试找出人脸的方向。 二维面地标点基本上符合头部的形状。 因此,给定一个通用人头的 3D 模型,我们可以找到多个人脸地标的大致对应的 3D 点,如下图所示:

估计位姿计算
根据这些 2D-3D 对应关系,我们可以通过点-n-透视(PNP)和算法来计算头部相对于相机的 3D 姿势(旋转和平移)。 该算法和对象姿态检测的细节超出了本章的范围;但是,我们可以快速合理地解释为什么只有几个 2D-3D 点对应就足以实现这一点。 拍摄上一张照片的相机具有刚性变换,这意味着它已相对于对象移动了一定距离,并有一定程度的旋转。 在非常宽泛的术语中,我们可以将图像上的点(相机附近)和对象之间的关系写成如下:
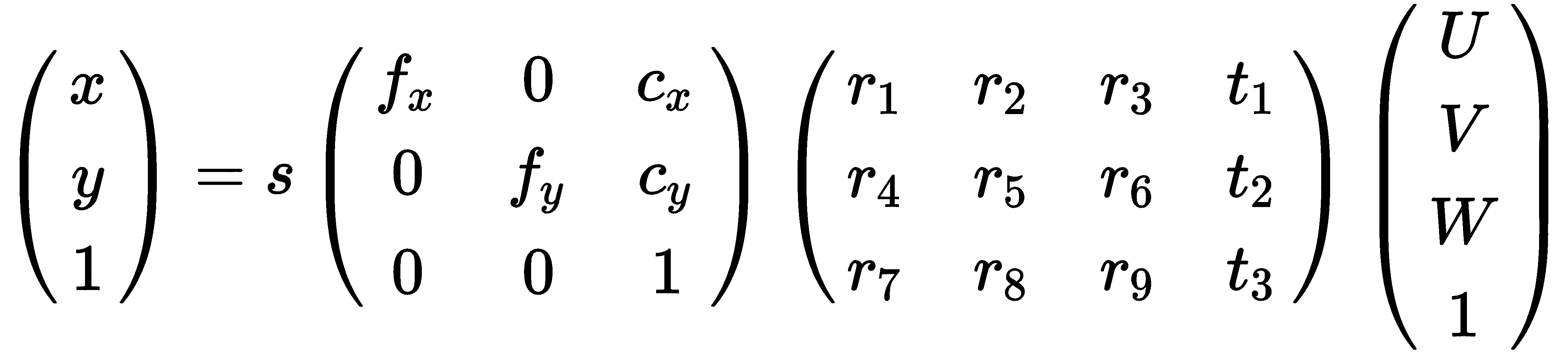
这是一个等式,其中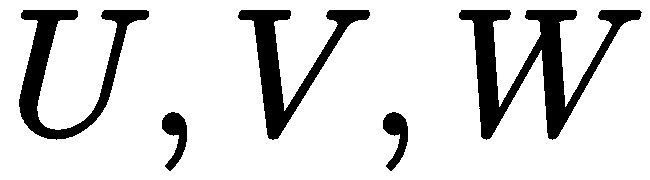 表示对象的 3D 位置,
表示对象的 3D 位置,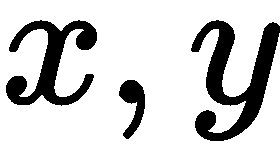 表示图像中的点。 这个等式还包括一个投影,它由相机内部参数(焦距f和中心点c)控制,它将 3D 点转换为 2D 图像点,最高可达s。如果说我们通过校准相机获得内部参数,或者我们对它们进行近似,我们就需要找到 12 个用于旋转和平移的系数。 如果我们有足够的 2D 和 3D 对应点,我们可以写出一个线性方程组,每个点可以贡献两个方程,来求解所有这些系数。 事实上,事实证明我们不需要 6 个点,因为旋转不到 9 个自由度,我们只需要 4 个点就可以凑合了。 OpenCV 提供了使用
表示图像中的点。 这个等式还包括一个投影,它由相机内部参数(焦距f和中心点c)控制,它将 3D 点转换为 2D 图像点,最高可达s。如果说我们通过校准相机获得内部参数,或者我们对它们进行近似,我们就需要找到 12 个用于旋转和平移的系数。 如果我们有足够的 2D 和 3D 对应点,我们可以写出一个线性方程组,每个点可以贡献两个方程,来求解所有这些系数。 事实上,事实证明我们不需要 6 个点,因为旋转不到 9 个自由度,我们只需要 4 个点就可以凑合了。 OpenCV 提供了使用calib3d模块的cv::solvePnP函数查找旋转和平移的实现。
我们将 3D 和 2D 点对齐并采用cv::solvePnP:
vector<Point3f> objectPoints {
{8.27412, 1.33849, 10.63490}, //left eye corner
{-8.27412, 1.33849, 10.63490}, //right eye corner
{0, -4.47894, 17.73010}, //nose tip
{-4.61960, -10.14360, 12.27940}, //right mouth corner
{4.61960, -10.14360, 12.27940}, //left mouth corner
};
vector<int> landmarksIDsFor3DPoints {45, 36, 30, 48, 54}; // 0-index
// ...
vector<Point2f> points2d;
for (int pId : landmarksIDsFor3DPoints) {
points2d.push_back(shapes[0][pId] / scaleFactor);
}
solvePnP(objectPoints, points2d, K, Mat(), rvec, tvec, true);
我们根据前面图像的大小估计的相机本征的K矩阵。
将姿势投影到图像上
获得旋转和平移后,我们将四个点从对象坐标空间投影到上图:鼻尖、x轴方向、y轴方向和z轴方向,并绘制上图中的箭头:
vector<Point3f> objectPointsForReprojection {
objectPoints[2], // tip of nose
objectPoints[2] + Point3f(0,0,15), // nose and Z-axis
objectPoints[2] + Point3f(0,15,0), // nose and Y-axis
objectPoints[2] + Point3f(15,0,0) // nose and X-axis
};
//...
vector<Point2f> projectionOutput(objectPointsForReprojection.size());
projectPoints(objectPointsForReprojection, rvec, tvec, K, Mat(), projectionOutput);
arrowedLine(out, projectionOutput[0], projectionOutput[1], Scalar(255,255,0));
arrowedLine(out, projectionOutput[0], projectionOutput[2], Scalar(0,255,255));
arrowedLine(out, projectionOutput[0], projectionOutput[3], Scalar(255,0,255));
这将显示面指向的方向,如以下屏幕截图所示:

简略的 / 概括的 / 简易判罪的 / 简易的
在本章中,我们学习了如何使用 OpenCV 的face contrib模块和cv::Facemark接口来检测图像中的人脸地标,然后使用带有cv::solvePnP()的地标找到人脸的大致方向。 这些 API 简单明了,但却具有强大的冲击力。 有了地标检测的知识,就可以实现许多令人兴奋的应用,如增强现实、人脸交换、识别和木偶表演。
